 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference Channel Selection by Multi-Channel Masking for End-to-End Multi-Channel Speech Enhancement
Paper and Code
Jun 05, 2024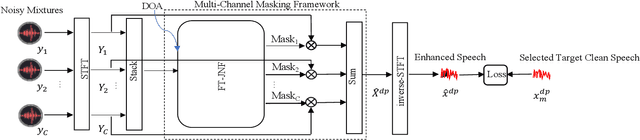
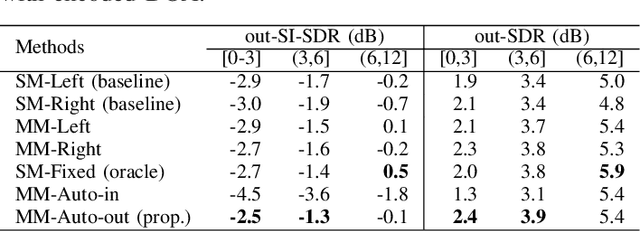
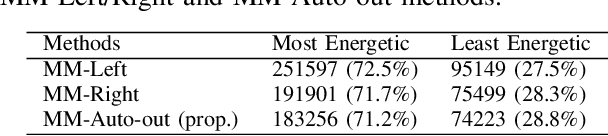

In end-to-end multi-channel speech enhancement, the traditional approach of designating one microphone signal as the reference for processing may not always yield optimal results. The limitation is particularly in scenarios with large distributed microphone arrays with varying speaker-to-microphone distances or compact, highly directional microphone arrays where speaker or microphone positions change over time. Current mask-based methods often fix the reference channel during training, which makes it not possible to adaptively select the reference channel for optimal performance. To address this problem, we introduce an adaptive approach for selecting the optimal reference channel. Our method leverages a multi-channel masking-based scheme, where multiple masked signals are combined to generate a single-channel output signal. This enhanced signal is then used for loss calculation, while the reference clean speech is adjusted based on the highest scale-invariant signal-to-distortion ratio (SI-SDR). The experimental results on the Spear challenge simulated dataset D4 demonstrate the superiority of our proposed method over the conventional approach of using a fixed reference channel with single-channel masking