 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCleanMel: Mel-Spectrogram Enhancement for Improving Both Speech Quality and ASR
Feb 27, 2025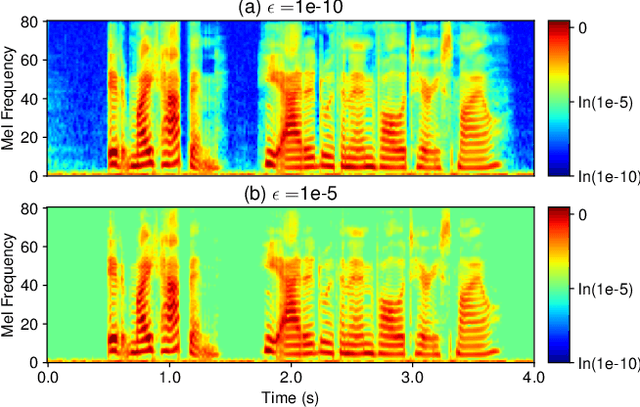
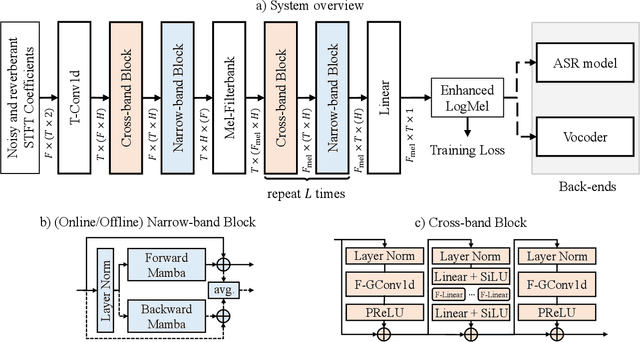
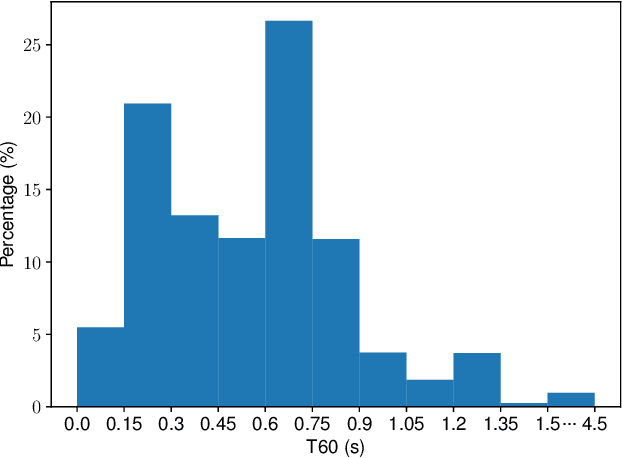
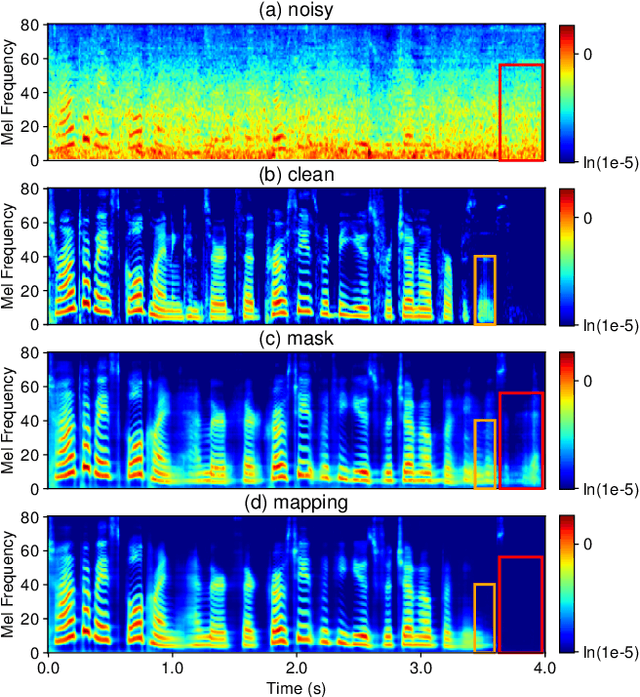
In this work, we propose CleanMel, a single-channel Mel-spectrogram denoising and dereverberation network for improving both speech quality and automatic speech recognition (ASR) performance. The proposed network takes as input the noisy and reverberant microphone recording and predicts the corresponding clean Mel-spectrogram. The enhanced Mel-spectrogram can be either transformed to speech waveform with a neural vocoder or directly used for ASR. The proposed network is composed of interleaved cross-band and narrow-band processing in the Mel-frequency domain, for learning the full-band spectral pattern and the narrow-band properties of signals, respectively. Compared to linear-frequency domain or time-domain speech enhancement, the key advantage of Mel-spectrogram enhancement is that Mel-frequency presents speech in a more compact way and thus is easier to learn, which will benefit both speech quality and ASR. Experimental results on four English and one Chinese datasets demonstrate a significant improvement in both speech quality and ASR performance achieved by the proposed model. Code and audio examples of our model are available online in https://audio.westlake.edu.cn/Research/CleanMel.html.
RealMAN: A Real-Recorded and Annotated Microphone Array Dataset for Dynamic Speech Enhancement and Localization
Jun 28, 2024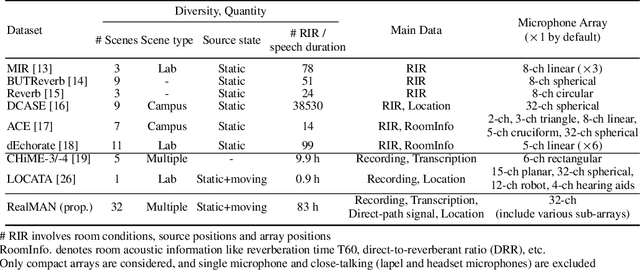


The training of deep learning-based multichannel speech enhancement and source localization systems relies heavily on the simulation of room impulse response and multichannel diffuse noise, due to the lack of large-scale real-recorded datasets. However, the acoustic mismatch between simulated and real-world data could degrade the model performance when applying in real-world scenarios. To bridge this simulation-to-real gap, this paper presents a new relatively large-scale Real-recorded and annotated Microphone Array speech&Noise (RealMAN) dataset. The proposed dataset is valuable in two aspects: 1) benchmarking speech enhancement and localization algorithms in real scenarios; 2) offering a substantial amount of real-world training data for potentially improving the performance of real-world applications. Specifically, a 32-channel array with high-fidelity microphones is used for recording. A loudspeaker is used for playing source speech signals. A total of 83-hour speech signals (48 hours for static speaker and 35 hours for moving speaker) are recorded in 32 different scenes, and 144 hours of background noise are recorded in 31 different scenes. Both speech and noise recording scenes cover various common indoor, outdoor, semi-outdoor and transportation environments, which enables the training of general-purpose speech enhancement and source localization networks. To obtain the task-specific annotations, the azimuth angle of the loudspeaker is annotated with an omni-direction fisheye camera by automatically detecting the loudspeaker. The direct-path signal is set as the target clean speech for speech enhancement, which is obtained by filtering the source speech signal with an estimated direct-path propagation filter.
Frame-wise streaming end-to-end speaker diarization with non-autoregressive self-attention-based attractors
Sep 25, 2023This work proposes a frame-wise online/streaming end-to-end neural diarization (FS-EEND) method in a frame-in-frame-out fashion. To frame-wisely detect a flexible number of speakers and extract/update their corresponding attractors, we propose to leverage a causal speaker embedding encoder and an online non-autoregressive self-attention-based attractor decoder. A look-ahead mechanism is adopted to allow leveraging some future frames for effectively detecting new speakers in real time and adaptively updating speaker attractors. The proposed method processes the audio stream frame by frame, and has a low inference latency caused by the look-ahead frames. Experiments show that, compared with the recently proposed block-wise online methods, our method FS-EEND achieves state-of-the-art diarization results, with a low inference latency and computational cost.
Fine-tune the pretrained ATST model for sound event detection
Sep 15, 2023



Sound event detection (SED) often suffers from the data deficiency problem. The recent baseline system in the DCASE2023 challenge task 4 leverages the large pretrained self-supervised learning (SelfSL) models to mitigate such restriction, where the pretrained models help to produce more discriminative features for SED. However, the pretrained models are regarded as a frozen feature extractor in the challenge baseline system and most of the challenge submissions, and fine-tuning of the pretrained models has been rarely studied. In this work, we study the fine-tuning method of the pretrained models for SED. We first introduce ATST-Frame, our newly proposed SelfSL model, to the SED system. ATST-Frame was especially designed for learning frame-level representations of audio signals and obtained state-of-the-art (SOTA) performances on a series of downstream tasks. We then propose a fine-tuning method for ATST-Frame using both (in-domain) unlabelled and labelled SED data. Our experiments show that, the proposed method overcomes the overfitting problem when fine-tuning the large pretrained network, and our SED system obtains new SOTA results of 0.587/0.812 PSDS1/PSDS2 scores on the DCASE challenge task 4 dataset.
Self-supervised Audio Teacher-Student Transformer for Both Clip-level and Frame-level Tasks
Jun 07, 2023In recent years, self-supervised learning (SSL) has emerged as a popular approach for learning audio representations. The ultimate goal of audio self-supervised pre-training is to transfer knowledge to downstream audio tasks, generally including clip-level and frame-level tasks. Clip-level tasks classify the scene or sound of an entire audio clip, e.g. audio tagging, instrument recognition, etc. While frame-level tasks detect event-level timestamps from an audio clip, e.g. sound event detection, speaker diarization, etc. Prior studies primarily evaluate on clip-level downstream tasks. Frame-level tasks are important for fine-grained acoustic scene/event understanding, and are generally more challenging than clip-level tasks. In order to tackle both clip-level and frame-level tasks, this paper proposes two self-supervised audio representation learning methods: ATST-Clip and ATST-Frame, responsible for learning clip-level and frame-level representations, respectively. ATST stands for Audio Teacher-Student Transformer, which means both methods use a transformer encoder and a teacher-student training scheme.Experimental results show that our ATST-Frame model obtains state-of-the-art (SOTA) performance on most of the clip-level and frame-level downstream tasks. Especially, it outperforms other models by a large margin on the frame-level sound event detection task. In addition, the performance can be further improved by combining the two models through knowledge distillation.
RCT: Random Consistency Training for Semi-supervised Sound Event Detection
Nov 04, 2021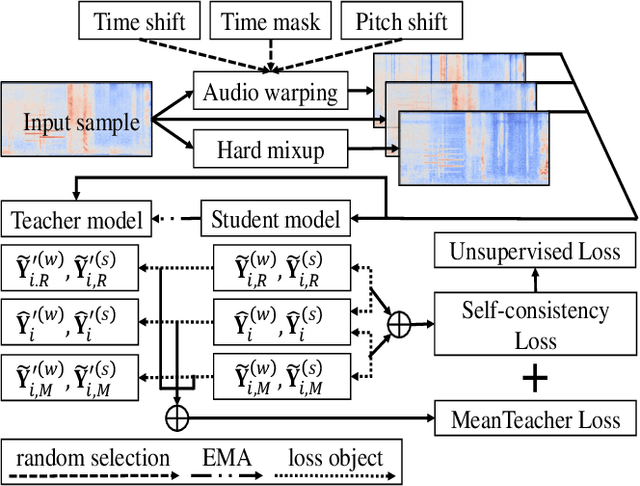

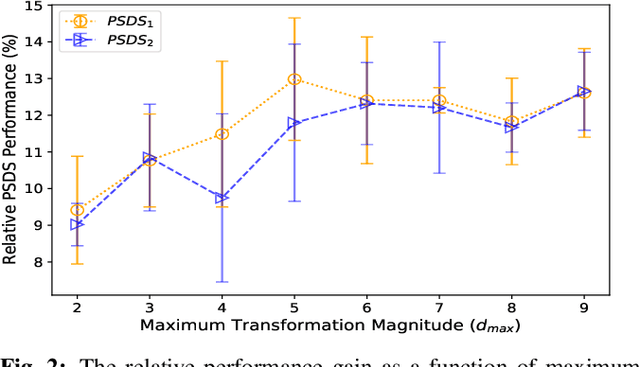
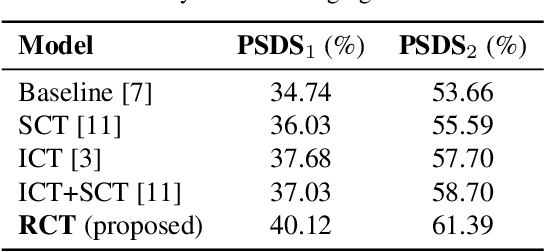
Sound event detection (SED), as a core module of acoustic environmental analysis, suffers from the problem of data deficiency. The integration of semi-supervised learning (SSL) largely mitigates such problem while bringing no extra annotation budget. This paper researches on several core modules of SSL, and introduces a random consistency training (RCT) strategy. First, a self-consistency loss is proposed to fuse with the teacher-student model to stabilize the training. Second, a hard mixup data augmentation is proposed to account for the additive property of sounds. Third, a random augmentation scheme is applied to flexibly combine different types of data augmentations. Experiments show that the proposed strategy outperform other widely-used strategies.