 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealMAN: A Real-Recorded and Annotated Microphone Array Dataset for Dynamic Speech Enhancement and Localization
Jun 28, 2024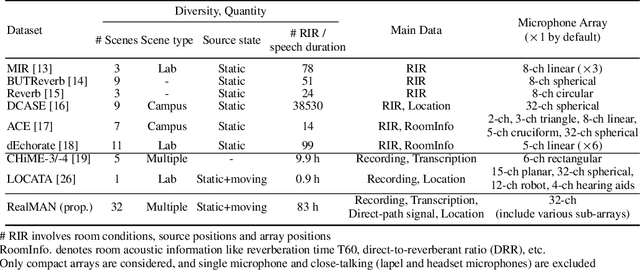
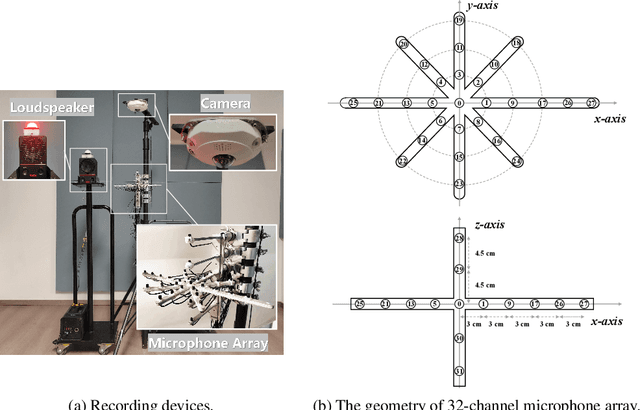


The training of deep learning-based multichannel speech enhancement and source localization systems relies heavily on the simulation of room impulse response and multichannel diffuse noise, due to the lack of large-scale real-recorded datasets. However, the acoustic mismatch between simulated and real-world data could degrade the model performance when applying in real-world scenarios. To bridge this simulation-to-real gap, this paper presents a new relatively large-scale Real-recorded and annotated Microphone Array speech&Noise (RealMAN) dataset. The proposed dataset is valuable in two aspects: 1) benchmarking speech enhancement and localization algorithms in real scenarios; 2) offering a substantial amount of real-world training data for potentially improving the performance of real-world applications. Specifically, a 32-channel array with high-fidelity microphones is used for recording. A loudspeaker is used for playing source speech signals. A total of 83-hour speech signals (48 hours for static speaker and 35 hours for moving speaker) are recorded in 32 different scenes, and 144 hours of background noise are recorded in 31 different scenes. Both speech and noise recording scenes cover various common indoor, outdoor, semi-outdoor and transportation environments, which enables the training of general-purpose speech enhancement and source localization networks. To obtain the task-specific annotations, the azimuth angle of the loudspeaker is annotated with an omni-direction fisheye camera by automatically detecting the loudspeaker. The direct-path signal is set as the target clean speech for speech enhancement, which is obtained by filtering the source speech signal with an estimated direct-path propagation filter.
Multichannel Long-Term Streaming Neural Speech Enhancement for Static and Moving Speakers
Mar 12, 2024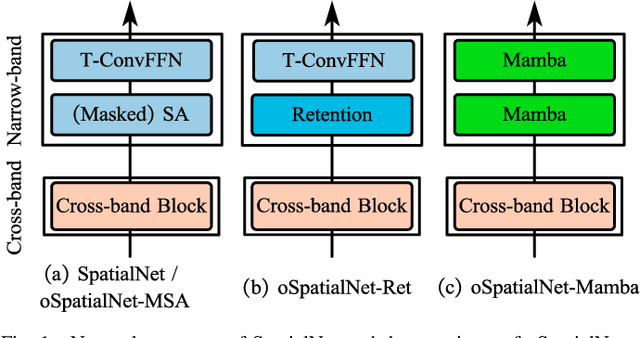

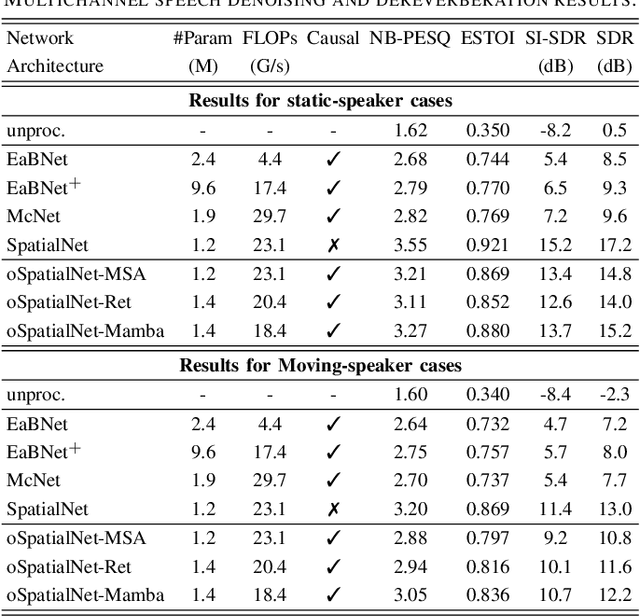
In this work, we extend our previously proposed offline SpatialNet for long-term streaming multichannel speech enhancement in both static and moving speaker scenarios. SpatialNet exploits spatial information, such as the spatial/steering direction of speech, for discriminating between target speech and interferences, and achieved outstanding performance. The core of SpatialNet is a narrow-band self-attention module used for learning the temporal dynamic of spatial vectors. Towards long-term streaming speech enhancement, we propose to replace the offline self-attention network with online networks that have linear inference complexity w.r.t signal length and meanwhile maintain the capability of learning long-term information. Three variants are developed based on (i) masked self-attention, (ii) Retention, a self-attention variant with linear inference complexity, and (iii) Mamba, a structured-state-space-based RNN-like network. Moreover, we investigate the length extrapolation ability of different networks, namely test on signals that are much longer than training signals, and propose a short-signal training plus long-signal fine-tuning strategy, which largely improves the length extrapolation ability of the networks within limited training time. Overall, the proposed online SpatialNet achieves outstanding speech enhancement performance for long audio streams, and for both static and moving speakers. The proposed method will be open-sourced in https://github.com/Audio-WestlakeU/NBSS.
SpatialNet: Extensively Learning Spatial Information for Multichannel Joint Speech Separation, Denoising and Dereverberation
Jul 31, 2023



This work proposes a neural network to extensively exploit spatial information for multichannel joint speech separation, denoising and dereverberation, named SpatialNet.In the short-time Fourier transform (STFT) domain, the proposed network performs end-to-end speech enhancement. It is mainly composed of interleaved narrow-band and cross-band blocks to respectively exploit narrow-band and cross-band spatial information. The narrow-band blocks process frequencies independently, and use self-attention mechanism and temporal convolutional layers to respectively perform spatial-feature-based speaker clustering and temporal smoothing/filtering. The cross-band blocks processes frames independently, and use full-band linear layer and frequency convolutional layers to respectively learn the correlation between all frequencies and adjacent frequencies. Experiments are conducted on various simulated and real datasets, and the results show that 1) the proposed network achieves the state-of-the-art performance on almost all tasks; 2) the proposed network suffers little from the spectral generalization problem; and 3) the proposed network is indeed performing speaker clustering (demonstrated by attention maps).
NBC2: Multichannel Speech Separation with Revised Narrow-band Conformer
Dec 05, 2022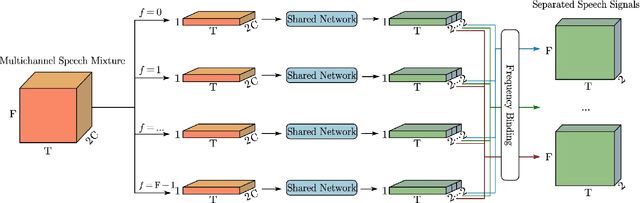
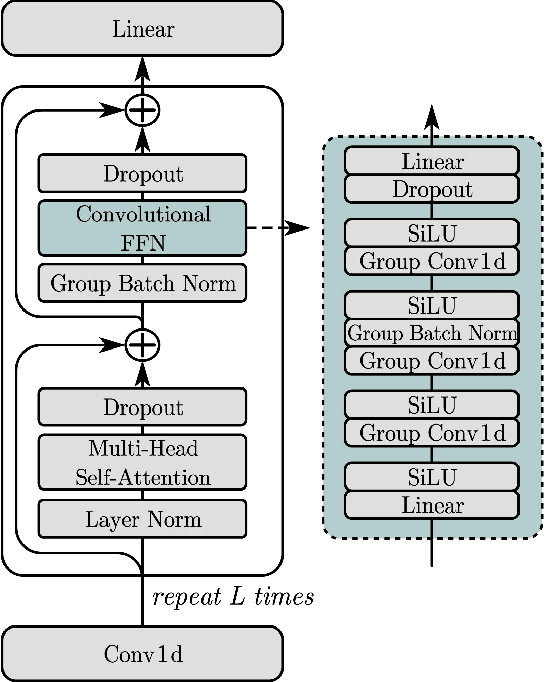

This work proposes a multichannel narrow-band speech separation network. In the short-time Fourier transform (STFT) domain, the proposed network processes each frequency independently, and all frequencies use a shared network. For each frequency, the network performs end-to-end speech separation, namely taking as input the STFT coefficients of microphone signals, and predicting the separated STFT coefficients of multiple speakers. The proposed network learns to cluster the frame-wise spatial/steering vectors that belong to different speakers. It is mainly composed of three components. First, a self-attention network. Clustering of spatial vectors shares a similar principle with the self-attention mechanism in the sense of computing the similarity of vectors and then aggregating similar vectors. Second, a convolutional feed-forward network. The convolutional layers are employed for signal smoothing and reverberation processing. Third, a novel hidden-layer normalization method, i.e. group batch normalization (GBN), is especially designed for the proposed narrow-band network to maintain the distribution of hidden units over frequencies. Overall, the proposed network is named NBC2, as it is a revised version of our previous NBC (narrow-band conformer) network. Experiments show that 1) the proposed network outperforms other state-of-the-art methods by a large margin, 2) the proposed GBN improves the signal-to-distortion ratio by 3 dB, relative to other normalization methods, such as batch/layer/group normalization, 3) the proposed narrow-band network is spectrum-agnostic, as it does not learn spectral patterns, and 4) the proposed network is indeed performing frame clustering (demonstrated by the attention maps).
McNet: Fuse Multiple Cues for Multichannel Speech Enhancement
Nov 16, 2022

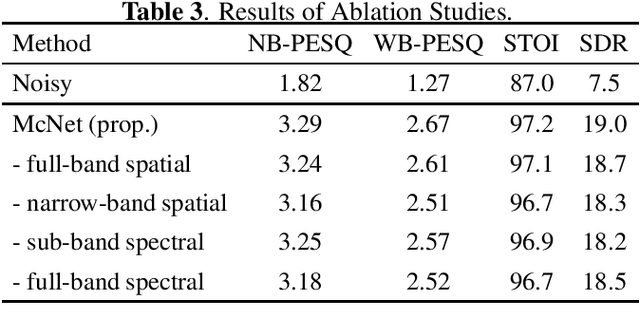
In multichannel speech enhancement, both spectral and spatial information are vital for discriminating between speech and noise. How to fully exploit these two types of information and their temporal dynamics remains an interesting research problem. As a solution to this problem, this paper proposes a multi-cue fusion network named McNet, which cascades four modules to respectively exploit the full-band spatial, narrow-band spatial, sub-band spectral, and full-band spectral information. Experiments show that each module in the proposed network has its unique contribution and, as a whole, notably outperforms other state-of-the-art methods.
Multichannel Speech Separation with Narrow-band Conformer
Apr 09, 2022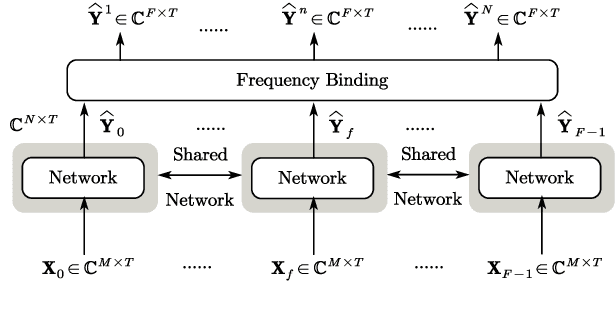
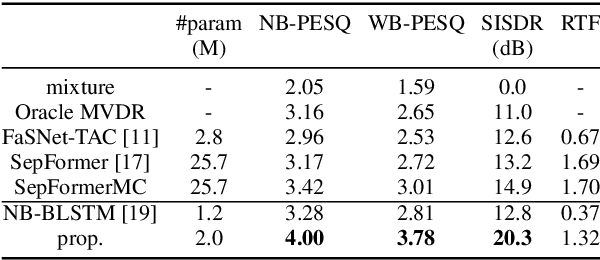
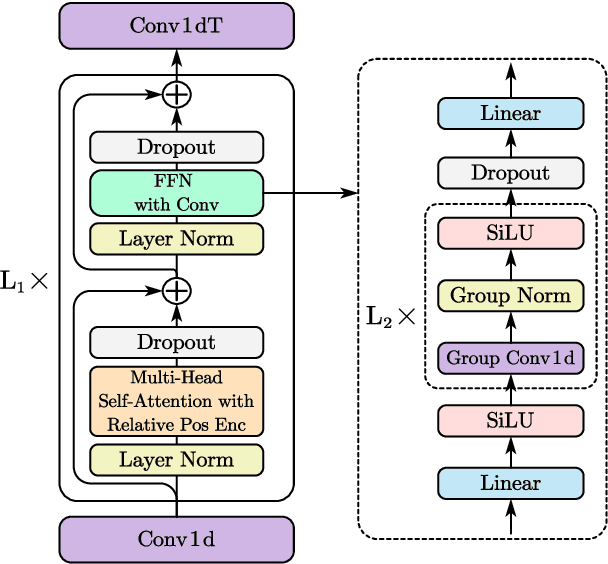
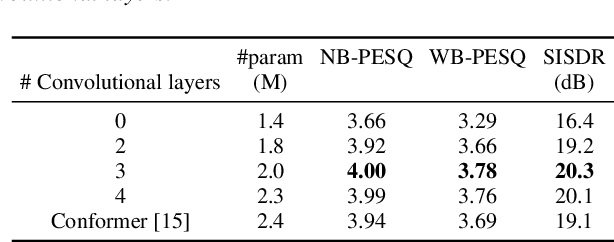
This work proposes a multichannel speech separation method with narrow-band Conformer (named NBC). The network is trained to learn to automatically exploit narrow-band speech separation information, such as spatial vector clustering of multiple speakers. Specifically, in the short-time Fourier transform (STFT) domain, the network processes each frequency independently, and is shared by all frequencies. For one frequency, the network inputs the STFT coefficients of multichannel mixture signals, and predicts the STFT coefficients of separated speech signals. Clustering of spatial vectors shares a similar principle with the self-attention mechanism in the sense of computing the similarity of vectors and then aggregating similar vectors. Therefore, Conformer would be especially suitable for the present problem. Experiments show that the proposed narrow-band Conformer achieves better speech separation performance than other state-of-the-art methods by a large margin.
Multi-channel Narrow-Band Deep Speech Separation with Full-band Permutation Invariant Training
Oct 12, 2021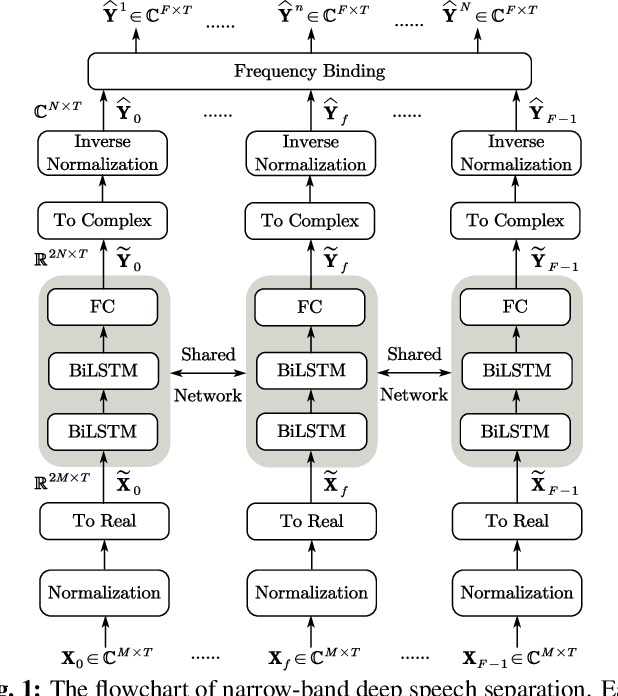
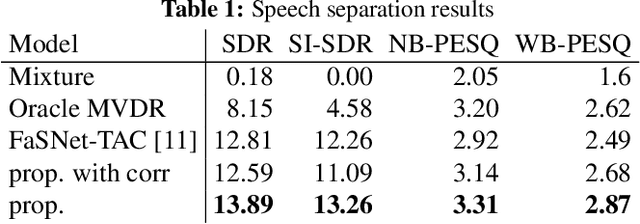

This paper addresses the problem of multi-channel multi-speech separation based on deep learning techniques. In the short time Fourier transform domain, we propose an end-to-end narrow-band network that directly takes as input the multi-channel mixture signals of one frequency, and outputs the separated signals of this frequency. In narrow-band, the spatial information (or inter-channel difference) can well discriminate between speakers at different positions. This information is intensively used in many narrow-band speech separation methods, such as beamforming and clustering of spatial vectors. The proposed network is trained to learn a rule to automatically exploit this information and perform speech separation. Such a rule should be valid for any frequency, thence the network is shared by all frequencies. In addition, a full-band permutation invariant training criterion is proposed to solve the frequency permutation problem encountered by most narrow-band methods. Experiments show that, by focusing on deeply learning the narrow-band information, the proposed method outperforms the oracle beamforming method and the state-of-the-art deep learning based method.