Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMcNet: Fuse Multiple Cues for Multichannel Speech Enhancement
Paper and Code


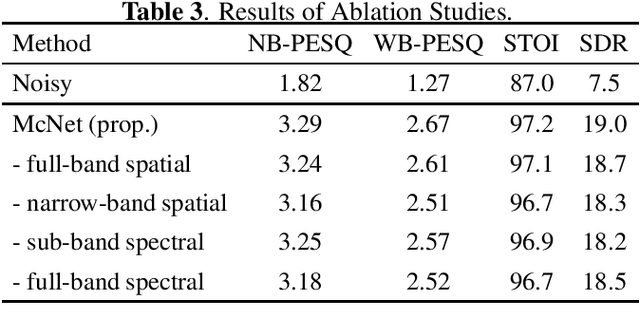
In multichannel speech enhancement, both spectral and spatial information are vital for discriminating between speech and noise. How to fully exploit these two types of information and their temporal dynamics remains an interesting research problem. As a solution to this problem, this paper proposes a multi-cue fusion network named McNet, which cascades four modules to respectively exploit the full-band spatial, narrow-band spatial, sub-band spectral, and full-band spectral information. Experiments show that each module in the proposed network has its unique contribution and, as a whole, notably outperforms other state-of-the-art methods.
* submitted to icassp 2023
View paper on