 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCT: Random Consistency Training for Semi-supervised Sound Event Detection
Paper and Code
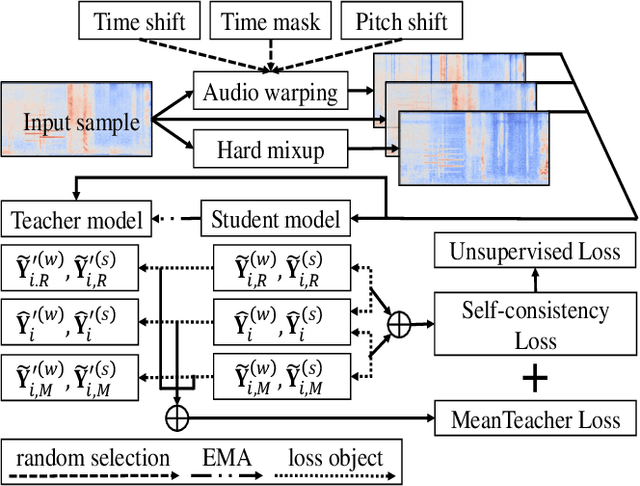

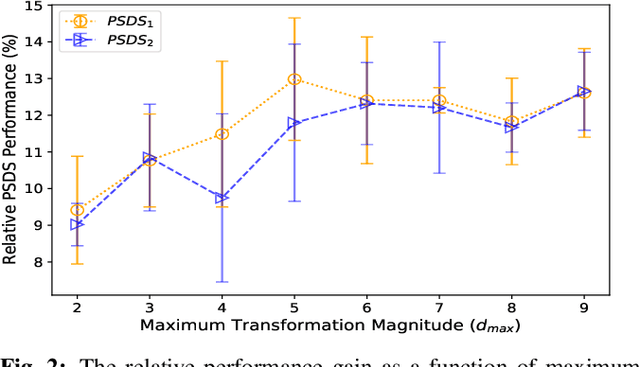
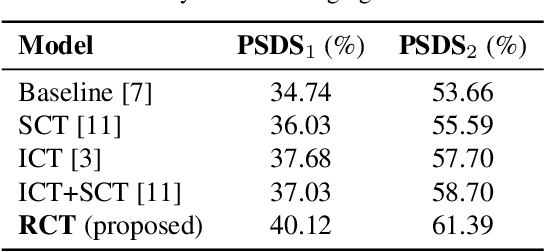
Sound event detection (SED), as a core module of acoustic environmental analysis, suffers from the problem of data deficiency. The integration of semi-supervised learning (SSL) largely mitigates such problem while bringing no extra annotation budget. This paper researches on several core modules of SSL, and introduces a random consistency training (RCT) strategy. First, a self-consistency loss is proposed to fuse with the teacher-student model to stabilize the training. Second, a hard mixup data augmentation is proposed to account for the additive property of sounds. Third, a random augmentation scheme is applied to flexibly combine different types of data augmentations. Experiments show that the proposed strategy outperform other widely-used strategies.