 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the 2024 Mandarin Stuttering Event Detection and Automatic Speech Recognition Challenge
Sep 09, 2024



The StutteringSpeech Challenge focuses on advancing speech technologies for people who stutter, specifically targeting Stuttering Event Detection (SED) and Automatic Speech Recognition (ASR) in Mandarin. The challenge comprises three tracks: (1) SED, which aims to develop systems for detection of stuttering events; (2) ASR, which focuses on creating robust systems for recognizing stuttered speech; and (3) Research track for innovative approaches utilizing the provided dataset. We utilizes an open-source Mandarin stuttering dataset AS-70, which has been split into new training and test sets for the challenge. This paper presents the dataset, details the challenge tracks, and analyzes the performance of the top systems, highlighting improvements in detection accuracy and reductions in recognition error rates. Our findings underscore the potential of specialized models and augmentation strategies in developing stuttered speech technologies.
AS-70: A Mandarin stuttered speech dataset for automatic speech recognition and stuttering event detection
Jun 11, 2024


The rapid advancements in speech technologies over the past two decades have led to human-level performance in tasks like automatic speech recognition (ASR) for fluent speech. However, the efficacy of these models diminishes when applied to atypical speech, such as stuttering. This paper introduces AS-70, the first publicly available Mandarin stuttered speech dataset, which stands out as the largest dataset in its category. Encompassing conversational and voice command reading speech, AS-70 includes verbatim manual transcription, rendering it suitable for various speech-related tasks. Furthermore, baseline systems are established, and experimental results are presented for ASR and stuttering event detection (SED) tasks. By incorporating this dataset into the model fine-tuning, significant improvements in the state-of-the-art ASR models, e.g., Whisper and Hubert, are observed, enhancing their inclusivity in addressing stuttered speech.
Spatial Processing Front-End For Distant ASR Exploiting Self-Attention Channel Combinator
Mar 25, 2022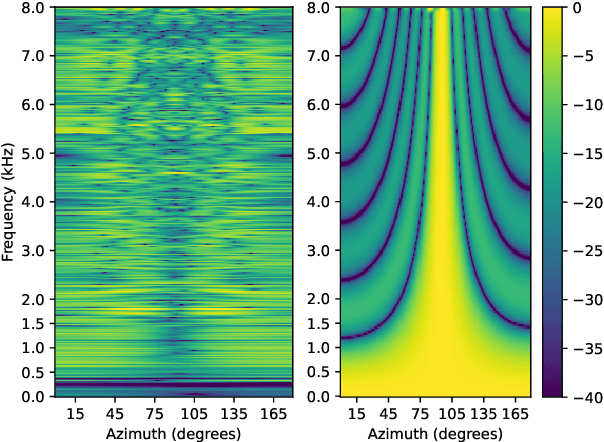
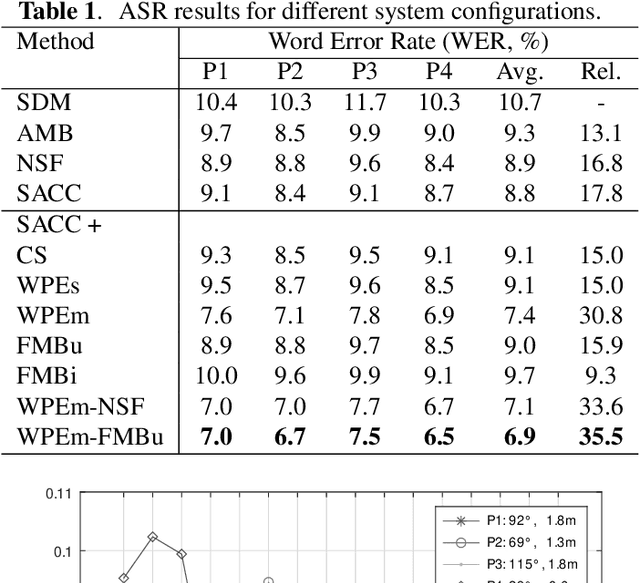
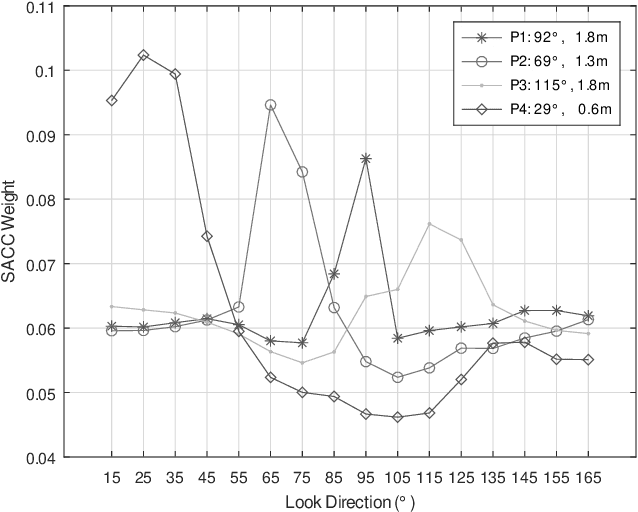
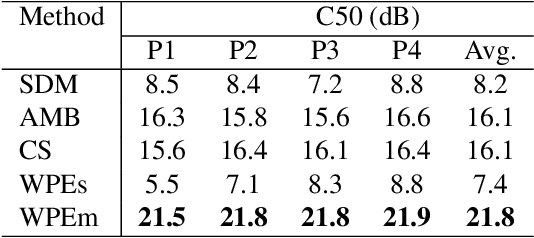
We present a novel multi-channel front-end based on channel shortening with theWeighted Prediction Error (WPE) method followed by a fixed MVDR beamformer used in combination with a recently proposed self-attention-based channel combination (SACC) scheme, for tackling the distant ASR problem. We show that the proposed system used as part of a ContextNet based end-to-end (E2E) ASR system outperforms leading ASR systems as demonstrated by a 21.6% reduction in relative WER on a multi-channel LibriSpeech playback dataset. We also show how dereverberation prior to beamforming is beneficial and compare the WPE method with a modified neural channel shortening approach. An analysis of the non-intrusive estimate of the signal C50 confirms that the 8 channel WPE method provides significant dereverberation of the signals (13.6 dB improvement). We also show how the weights of the SACC system allow the extraction of accurate spatial information which can be beneficial for other speech processing applications like diarization.
Self-Attention Channel Combinator Frontend for End-to-End Multichannel Far-field Speech Recognition
Sep 10, 2021
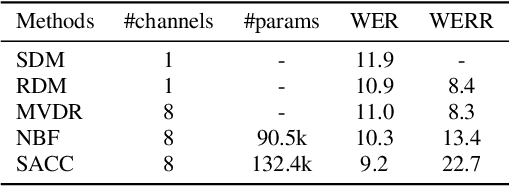
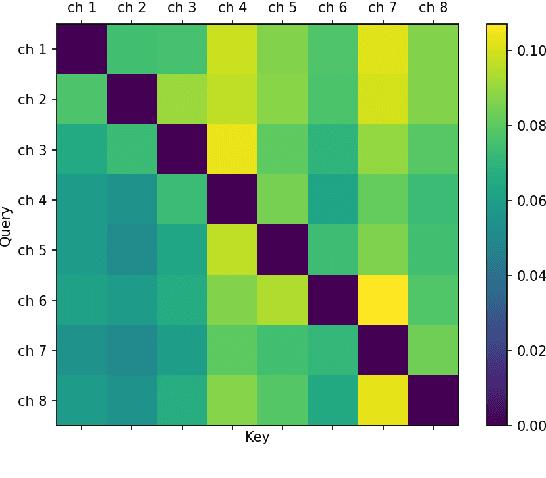
When a sufficiently large far-field training data is presented, jointly optimizing a multichannel frontend and an end-to-end (E2E) Automatic Speech Recognition (ASR) backend shows promising results. Recent literature has shown traditional beamformer designs, such as MVDR (Minimum Variance Distortionless Response) or fixed beamformers can be successfully integrated as the frontend into an E2E ASR system with learnable parameters. In this work, we propose the self-attention channel combinator (SACC) ASR frontend, which leverages the self-attention mechanism to combine multichannel audio signals in the magnitude spectral domain. Experiments conducted on a multichannel playback test data shows that the SACC achieved a 9.3% WERR compared to a state-of-the-art fixed beamformer-based frontend, both jointly optimized with a ContextNet-based ASR backend. We also demonstrate the connection between the SACC and the traditional beamformers, and analyze the intermediate outputs of the SACC.
A Simple Fusion of Deep and Shallow Learning for Acoustic Scene Classification
Jun 27, 2018
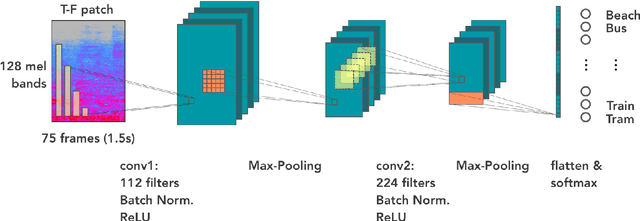
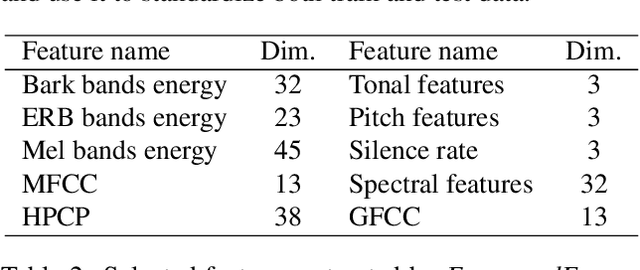
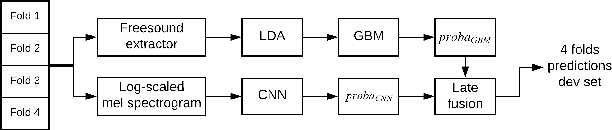
In the past, Acoustic Scene Classification systems have been based on hand crafting audio features that are input to a classifier. Nowadays, the common trend is to adopt data driven techniques, e.g., deep learning, where audio representations are learned from data. In this paper, we propose a system that consists of a simple fusion of two methods of the aforementioned types: a deep learning approach where log-scaled mel-spectrograms are input to a convolutional neural network, and a feature engineering approach, where a collection of hand-crafted features is input to a gradient boosting machine. We first show that both methods provide complementary information to some extent. Then, we use a simple late fusion strategy to combine both methods. We report classification accuracy of each method individually and the combined system on the TUT Acoustic Scenes 2017 dataset. The proposed fused system outperforms each of the individual methods and attains a classification accuracy of 72.8% on the evaluation set, improving the baseline system by 11.8%.