 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysiological-Physical Feature Fusion for Automatic Voice Spoofing Detection
Paper and Code
Sep 01, 2021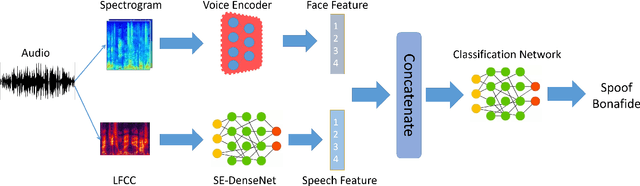



Speaker verification systems have been used in many production scenarios in recent years. Unfortunately, they are still highly prone to different kinds of spoofing attacks such as voice conversion and speech synthesis, etc. In this paper, we propose a new method base on physiological-physical feature fusion to deal with voice spoofing attacks. This method involves feature extraction, a densely connected convolutional neural network with squeeze and excitation block (SE-DenseNet), multi-scale residual neural network with squeeze and excitation block (SE-Res2Net) and feature fusion strategies. We first pre-trained a convolutional neural network using the speaker's voice and face in the video as surveillance signals. It can extract physiological features from speech. Then we use SE-DenseNet and SE-Res2Net to extract physical features. Such a densely connection pattern has high parameter efficiency and squeeze and excitation block can enhance the transmission of the feature. Finally, we integrate the two features into the SE-Densenet to identify the spoofing attacks. Experimental results on the ASVspoof 2019 data set show that our model is effective for voice spoofing detection. In the logical access scenario, our model improves the tandem decision cost function (t-DCF) and equal error rate (EER) scores by 4% and 7%, respectively, compared with other methods. In the physical access scenario, our model improved t-DCF and EER scores by 8% and 10%, respectively.