 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Compressive Knowledge Graph Hypothesis: Which Graph Facts Matter for Scientific Hypothesis Generation?
May 28, 2026Knowledge graphs (KGs) can provide structured scientific context to language models, but it remains unclear which graph facts actually shape the generated hypotheses. We study KG-guided hypothesis generation for battery materials across Mistral-7B, Llama-3.1-70B, and Gemini 2.5 Flash. We perturb local KGs by varying density, ontology richness, topology, and control structure, and evaluate outputs with both provided-graph and fixed-reference metrics. Across models, KG utility is selective and model-dependent: graph context changes outputs, but no-KG outputs also recover substantial graph content from model priors. Compact top-k subgraphs often approximate full-KG behavior, including when claimed-outcome triples are held out. At the same time, compression is not unique to one semantic ranking rule, random and topology-based subsets can also recover much of the signal. These results support a redundancy-aware Compressive KG hypothesis: useful KG signal is often recoverable from compact, scientifically structured subgraphs rather than requiring the full local graph.
From Knowledge to Action: Outcomes of the 2025 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
May 04, 2026Large language models (LLMs) are rapidly changing how researchers in materials science and chemistry discover, organize, and act on scientific knowledge. This paper analyzes a broad set of community-developed LLM applications in an effort to identify emerging patterns in how these systems can be used across the scientific research lifecycle. We organize the projects into two complementary categories: Knowledge Infrastructure, systems that structure, retrieve, synthesize, and validate scientific information; and Action Systems, systems that execute, coordinate, or automate scientific work across computational and experimental environments. The submissions reveal a shift from single-purpose LLM tools toward integrated, multi-agent workflows that combine retrieval, reasoning, tool use, and domain-specific validation. Prominent themes include retrieval-augmented generation as grounding infrastructure, persistent structured knowledge representations, multimodal and multilingual scientific inputs, and early progress toward laboratory-integrated closed-loop systems. Together, these results suggest that LLMs are evolving from general-purpose assistants into composable infrastructure for scientific reasoning and action. This work provides a community snapshot of that transition and a practical taxonomy for understanding emerging LLM-enabled workflows in materials science and chemistry.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Lessons in Reproducibility: Insights from NLP Studies in Materials Science
Jul 28, 2023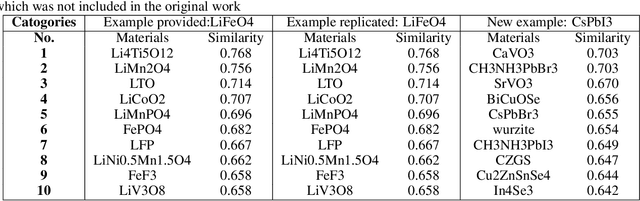
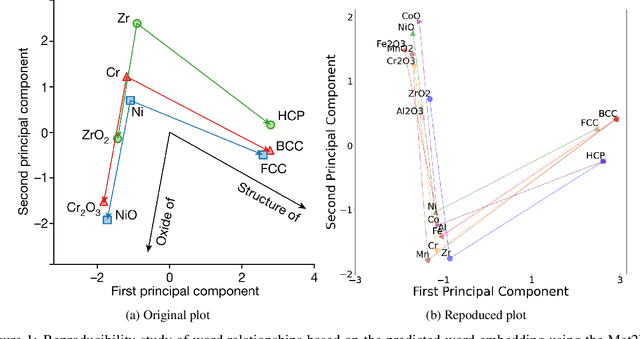
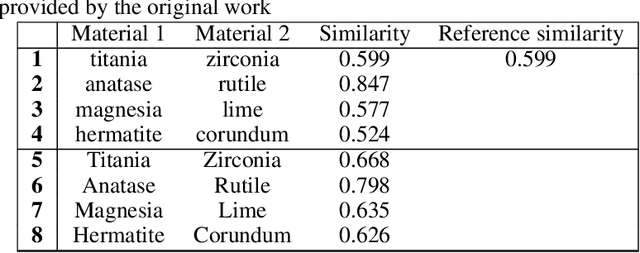

Natural Language Processing (NLP), a cornerstone field within artificial intelligence, has been increasingly utilized in the field of materials science literature. Our study conducts a reproducibility analysis of two pioneering works within this domain: "Machine-learned and codified synthesis parameters of oxide materials" by Kim et al., and "Unsupervised word embeddings capture latent knowledge from materials science literature" by Tshitoyan et al. We aim to comprehend these studies from a reproducibility perspective, acknowledging their significant influence on the field of materials informatics, rather than critiquing them. Our study indicates that both papers offered thorough workflows, tidy and well-documented codebases, and clear guidance for model evaluation. This makes it easier to replicate their results successfully and partially reproduce their findings. In doing so, they set commendable standards for future materials science publications to aspire to. However, our analysis also highlights areas for improvement such as to provide access to training data where copyright restrictions permit, more transparency on model architecture and the training process, and specifications of software dependency versions. We also cross-compare the word embedding models between papers, and find that some key differences in reproducibility and cross-compatibility are attributable to design choices outside the bounds of the models themselves. In summary, our study appreciates the benchmark set by these seminal papers while advocating for further enhancements in research reproducibility practices in the field of NLP for materials science. This balance of understanding and continuous improvement will ultimately propel the intersecting domains of NLP and materials science literature into a future of exciting discoveries.