 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChaTA: Towards an Intelligent Question-Answer Teaching Assistant using Open-Source LLMs
Nov 13, 2023Responding to the thousands of student questions on online QA platforms each semester has a considerable human cost, particularly in computing courses with rapidly growing enrollments. To address the challenges of scalable and intelligent question-answering (QA), we introduce an innovative solution that leverages open-source Large Language Models (LLMs) from the LLaMA-2 family to ensure data privacy. Our approach combines augmentation techniques such as retrieval augmented generation (RAG), supervised fine-tuning (SFT), and learning from human preferences data using Direct Preference Optimization (DPO). Through extensive experimentation on a Piazza dataset from an introductory CS course, comprising 10,000 QA pairs and 1,500 pairs of preference data, we demonstrate a significant 30% improvement in the quality of answers, with RAG being a particularly impactful addition. Our contributions include the development of a novel architecture for educational QA, extensive evaluations of LLM performance utilizing both human assessments and LLM-based metrics, and insights into the challenges and future directions of educational data processing. This work paves the way for the development of CHATA, an intelligent QA assistant customizable for courses with an online QA platform
* Updates for camera-ready submission
Knowledge Tracing Challenge: Optimal Activity Sequencing for Students
Nov 13, 2023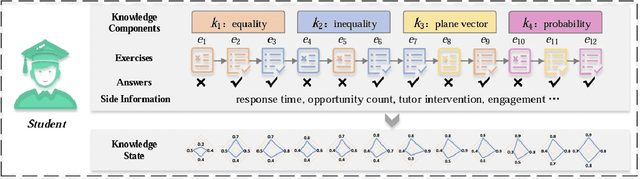
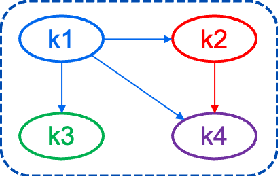

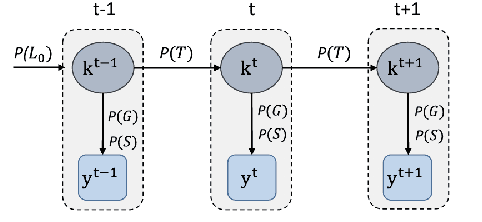
Knowledge tracing is a method used in education to assess and track the acquisition of knowledge by individual learners. It involves using a variety of techniques, such as quizzes, tests, and other forms of assessment, to determine what a learner knows and does not know about a particular subject. The goal of knowledge tracing is to identify gaps in understanding and provide targeted instruction to help learners improve their understanding and retention of material. This can be particularly useful in situations where learners are working at their own pace, such as in online learning environments. By providing regular feedback and adjusting instruction based on individual needs, knowledge tracing can help learners make more efficient progress and achieve better outcomes. Effectively solving the KT problem would unlock the potential of computer-aided education applications such as intelligent tutoring systems, curriculum learning, and learning materials recommendations. In this paper, we will present the results of the implementation of two Knowledge Tracing algorithms on a newly released dataset as part of the AAAI2023 Global Knowledge Tracing Challenge.
Automated Essay Scoring in Argumentative Writing: DeBERTeachingAssistant
Jul 09, 2023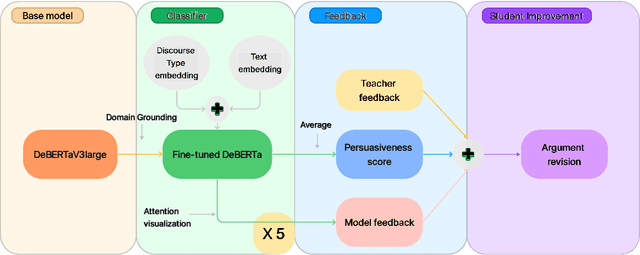
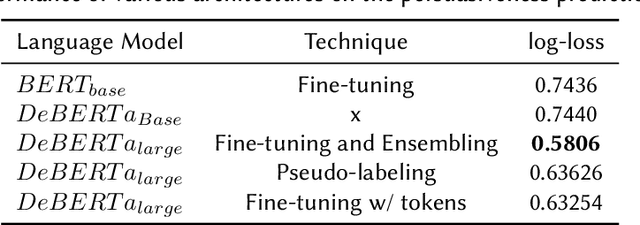
Automated Essay scoring has been explored as a research and industry problem for over 50 years. It has drawn a lot of attention from the NLP community because of its clear educational value as a research area that can engender the creation of valuable time-saving tools for educators around the world. Yet, these tools are generally focused on detecting good grammar, spelling mistakes, and organization quality but tend to fail at incorporating persuasiveness features in their final assessment. The responsibility to give actionable feedback to the student to improve the strength of their arguments is left solely on the teacher's shoulders. In this work, we present a transformer-based architecture capable of achieving above-human accuracy in annotating argumentative writing discourse elements for their persuasiveness quality and we expand on planned future work investigating the explainability of our model so that actionable feedback can be offered to the student and thus potentially enable a partnership between the teacher's advice and the machine's advice.
Assessing the efficacy of large language models in generating accurate teacher responses
Jul 09, 2023

(Tack et al., 2023) organized the shared task hosted by the 18th Workshop on Innovative Use of NLP for Building Educational Applications on generation of teacher language in educational dialogues. Following the structure of the shared task, in this study, we attempt to assess the generative abilities of large language models in providing informative and helpful insights to students, thereby simulating the role of a knowledgeable teacher. To this end, we present an extensive evaluation of several benchmarking generative models, including GPT-4 (few-shot, in-context learning), fine-tuned GPT-2, and fine-tuned DialoGPT. Additionally, to optimize for pedagogical quality, we fine-tuned the Flan-T5 model using reinforcement learning. Our experimental findings on the Teacher-Student Chatroom Corpus subset indicate the efficacy of GPT-4 over other fine-tuned models, measured using BERTScore and DialogRPT. We hypothesize that several dataset characteristics, including sampling, representativeness, and dialog completeness, pose significant challenges to fine-tuning, thus contributing to the poor generalizability of the fine-tuned models. Finally, we note the need for these generative models to be evaluated with a metric that relies not only on dialog coherence and matched language modeling distribution but also on the model's ability to showcase pedagogical skills.
Exploring the MIT Mathematics and EECS Curriculum Using Large Language Models
Jun 24, 2023



We curate a comprehensive dataset of 4,550 questions and solutions from problem sets, midterm exams, and final exams across all MIT Mathematics and Electrical Engineering and Computer Science (EECS) courses required for obtaining a degree. We evaluate the ability of large language models to fulfill the graduation requirements for any MIT major in Mathematics and EECS. Our results demonstrate that GPT-3.5 successfully solves a third of the entire MIT curriculum, while GPT-4, with prompt engineering, achieves a perfect solve rate on a test set excluding questions based on images. We fine-tune an open-source large language model on this dataset. We employ GPT-4 to automatically grade model responses, providing a detailed performance breakdown by course, question, and answer type. By embedding questions in a low-dimensional space, we explore the relationships between questions, topics, and classes and discover which questions and classes are required for solving other questions and classes through few-shot learning. Our analysis offers valuable insights into course prerequisites and curriculum design, highlighting language models' potential for learning and improving Mathematics and EECS education.
Human Evaluation of Text-to-Image Models on a Multi-Task Benchmark
Nov 22, 2022
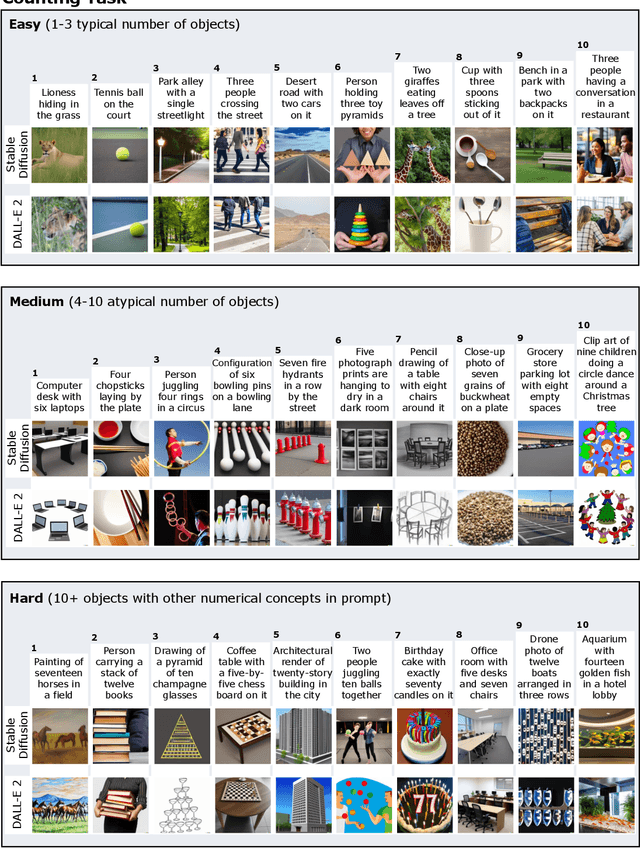

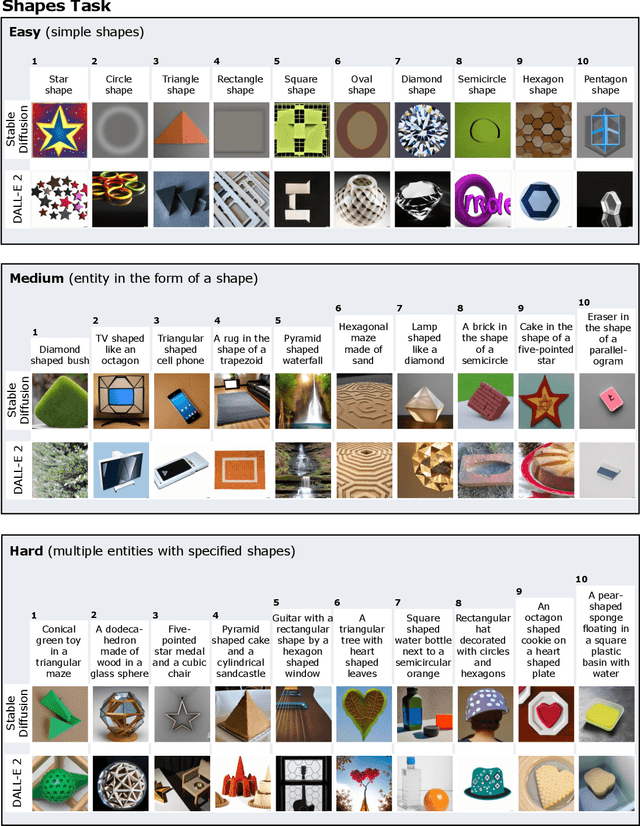
We provide a new multi-task benchmark for evaluating text-to-image models. We perform a human evaluation comparing the most common open-source (Stable Diffusion) and commercial (DALL-E 2) models. Twenty computer science AI graduate students evaluated the two models, on three tasks, at three difficulty levels, across ten prompts each, providing 3,600 ratings. Text-to-image generation has seen rapid progress to the point that many recent models have demonstrated their ability to create realistic high-resolution images for various prompts. However, current text-to-image methods and the broader body of research in vision-language understanding still struggle with intricate text prompts that contain many objects with multiple attributes and relationships. We introduce a new text-to-image benchmark that contains a suite of thirty-two tasks over multiple applications that capture a model's ability to handle different features of a text prompt. For example, asking a model to generate a varying number of the same object to measure its ability to count or providing a text prompt with several objects that each have a different attribute to identify its ability to match objects and attributes correctly. Rather than subjectively evaluating text-to-image results on a set of prompts, our new multi-task benchmark consists of challenge tasks at three difficulty levels (easy, medium, and hard) and human ratings for each generated image.
A Dataset and Benchmark for Automatically Answering and Generating Machine Learning Final Exams
Jun 11, 2022


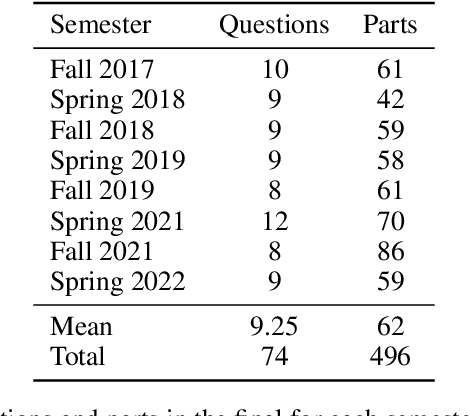
Can a machine learn machine learning? We propose to answer this question using the same criteria we use to answer a similar question: can a human learn machine learning? We automatically answer MIT final exams in Introduction to Machine Learning at a human level. The course is a large undergraduate class with around five hundred students each semester. Recently, program synthesis and few-shot learning solved university-level problem set questions in mathematics and STEM courses at a human level. In this work, we solve questions from final exams that differ from problem sets in several ways: the questions are longer, have multiple parts, are more complicated, and span a broader set of topics. We provide a new dataset and benchmark of questions from eight MIT Introduction to Machine Learning final exams between Fall 2017 and Spring 2022 and provide code for automatically answering these questions and generating new questions. We perform ablation studies comparing zero-shot learning with few-shot learning, chain-of-thought prompting, GPT-3 pre-trained on text and Codex fine-tuned on code on a range of machine learning topics and find that few-shot learning methods perform best. We make our data and code publicly available for the machine learning community.