 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAD-SUM: Leveraging Gradient Summarization for Optimal Prompt Engineering
Jul 12, 2024



Prompt engineering for large language models (LLMs) is often a manual time-intensive process that involves generating, evaluating, and refining prompts iteratively to ensure high-quality outputs. While there has been work on automating prompt engineering, the solutions generally are either tuned to specific tasks with given answers or are quite costly. We introduce GRAD-SUM, a scalable and flexible method for automatic prompt engineering that builds on gradient-based optimization techniques. Our approach incorporates user-defined task descriptions and evaluation criteria, and features a novel gradient summarization module to generalize feedback effectively. Our results demonstrate that GRAD-SUM consistently outperforms existing methods across various benchmarks, highlighting its versatility and effectiveness in automatic prompt optimization.
A Dataset and Benchmark for Automatically Answering and Generating Machine Learning Final Exams
Jun 11, 2022


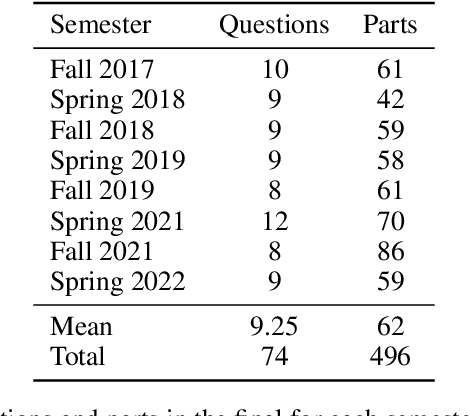
Can a machine learn machine learning? We propose to answer this question using the same criteria we use to answer a similar question: can a human learn machine learning? We automatically answer MIT final exams in Introduction to Machine Learning at a human level. The course is a large undergraduate class with around five hundred students each semester. Recently, program synthesis and few-shot learning solved university-level problem set questions in mathematics and STEM courses at a human level. In this work, we solve questions from final exams that differ from problem sets in several ways: the questions are longer, have multiple parts, are more complicated, and span a broader set of topics. We provide a new dataset and benchmark of questions from eight MIT Introduction to Machine Learning final exams between Fall 2017 and Spring 2022 and provide code for automatically answering these questions and generating new questions. We perform ablation studies comparing zero-shot learning with few-shot learning, chain-of-thought prompting, GPT-3 pre-trained on text and Codex fine-tuned on code on a range of machine learning topics and find that few-shot learning methods perform best. We make our data and code publicly available for the machine learning community.