 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Vision Language Models as Closed-Loop Symbolic Planners for Robotic Applications: A Control-Theoretic Perspective
Nov 10, 2025Large Language Models (LLMs) and Vision Language Models (VLMs) have been widely used for embodied symbolic planning. Yet, how to effectively use these models for closed-loop symbolic planning remains largely unexplored. Because they operate as black boxes, LLMs and VLMs can produce unpredictable or costly errors, making their use in high-level robotic planning especially challenging. In this work, we investigate how to use VLMs as closed-loop symbolic planners for robotic applications from a control-theoretic perspective. Concretely, we study how the control horizon and warm-starting impact the performance of VLM symbolic planners. We design and conduct controlled experiments to gain insights that are broadly applicable to utilizing VLMs as closed-loop symbolic planners, and we discuss recommendations that can help improve the performance of VLM symbolic planners.
Embodied Red Teaming for Auditing Robotic Foundation Models
Nov 27, 2024

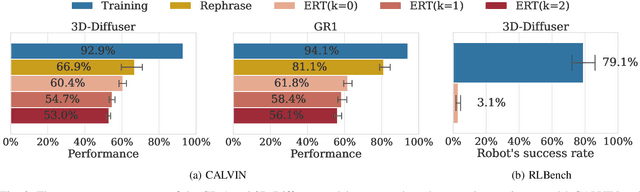
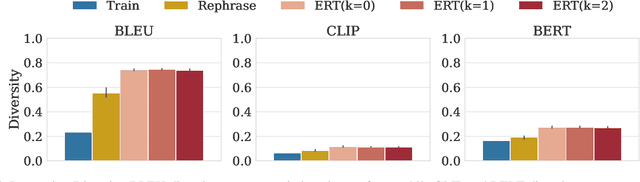
Language-conditioned robot models (i.e., robotic foundation models) enable robots to perform a wide range of tasks based on natural language instructions. Despite strong performance on existing benchmarks, evaluating the safety and effectiveness of these models is challenging due to the complexity of testing all possible language variations. Current benchmarks have two key limitations: they rely on a limited set of human-generated instructions, missing many challenging cases, and they focus only on task performance without assessing safety, such as avoiding damage. To address these gaps, we introduce Embodied Red Teaming (ERT), a new evaluation method that generates diverse and challenging instructions to test these models. ERT uses automated red teaming techniques with Vision Language Models (VLMs) to create contextually grounded, difficult instructions. Experimental results show that state-of-the-art models frequently fail or behave unsafely on ERT tests, underscoring the shortcomings of current benchmarks in evaluating real-world performance and safety. Code and videos are available at: https://sites.google.com/view/embodiedredteam.
Beyond Uniform Sampling: Offline Reinforcement Learning with Imbalanced Datasets
Oct 12, 2023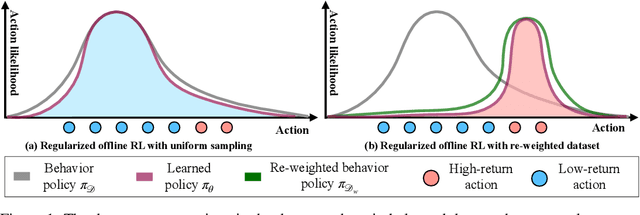

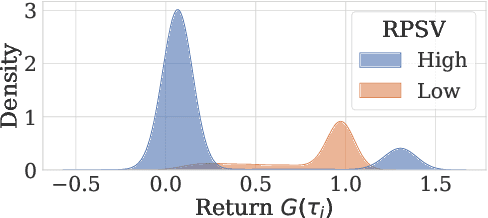
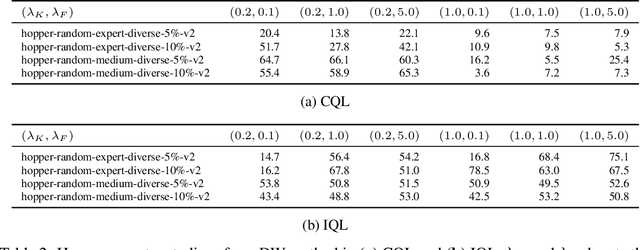
Offline policy learning is aimed at learning decision-making policies using existing datasets of trajectories without collecting additional data. The primary motivation for using reinforcement learning (RL) instead of supervised learning techniques such as behavior cloning is to find a policy that achieves a higher average return than the trajectories constituting the dataset. However, we empirically find that when a dataset is dominated by suboptimal trajectories, state-of-the-art offline RL algorithms do not substantially improve over the average return of trajectories in the dataset. We argue this is due to an assumption made by current offline RL algorithms of staying close to the trajectories in the dataset. If the dataset primarily consists of sub-optimal trajectories, this assumption forces the policy to mimic the suboptimal actions. We overcome this issue by proposing a sampling strategy that enables the policy to only be constrained to ``good data" rather than all actions in the dataset (i.e., uniform sampling). We present a realization of the sampling strategy and an algorithm that can be used as a plug-and-play module in standard offline RL algorithms. Our evaluation demonstrates significant performance gains in 72 imbalanced datasets, D4RL dataset, and across three different offline RL algorithms. Code is available at https://github.com/Improbable-AI/dw-offline-rl.
* Accepted NeurIPS 2023
A Dataset and Benchmark for Automatically Answering and Generating Machine Learning Final Exams
Jun 11, 2022


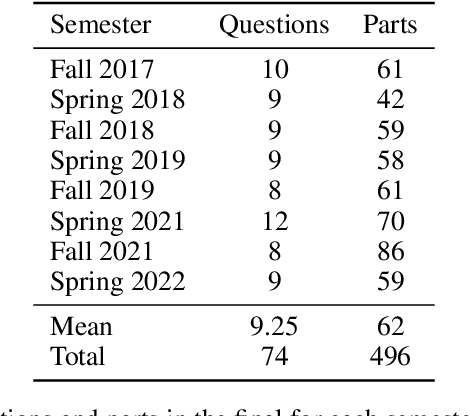
Can a machine learn machine learning? We propose to answer this question using the same criteria we use to answer a similar question: can a human learn machine learning? We automatically answer MIT final exams in Introduction to Machine Learning at a human level. The course is a large undergraduate class with around five hundred students each semester. Recently, program synthesis and few-shot learning solved university-level problem set questions in mathematics and STEM courses at a human level. In this work, we solve questions from final exams that differ from problem sets in several ways: the questions are longer, have multiple parts, are more complicated, and span a broader set of topics. We provide a new dataset and benchmark of questions from eight MIT Introduction to Machine Learning final exams between Fall 2017 and Spring 2022 and provide code for automatically answering these questions and generating new questions. We perform ablation studies comparing zero-shot learning with few-shot learning, chain-of-thought prompting, GPT-3 pre-trained on text and Codex fine-tuned on code on a range of machine learning topics and find that few-shot learning methods perform best. We make our data and code publicly available for the machine learning community.
Fully Persistent Spatial Data Structures for Efficient Queries in Path-Dependent Motion Planning Applications
Jun 06, 2022


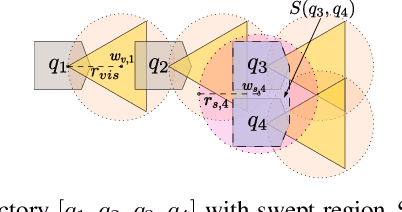
Motion planning is a ubiquitous problem that is often a bottleneck in robotic applications. We demonstrate that motion planning problems such as minimum constraint removal, belief-space planning, and visibility-aware motion planning (VAMP) benefit from a path-dependent formulation, in which the state at a search node is represented implicitly by the path to that node. A naive approach to computing the feasibility of a successor node in such a path-dependent formulation takes time linear in the path length to the node, in contrast to a (possibly very large) constant time for a more typical search formulation. For long-horizon plans, performing this linear-time computation, which we call the lookback, for each node becomes prohibitive. To improve upon this, we introduce the use of a fully persistent spatial data structure (FPSDS), which bounds the size of the lookback. We then focus on the application of the FPSDS in VAMP, which involves incremental geometric computations that can be accelerated by filtering configurations with bounding volumes using nearest-neighbor data structures. We demonstrate an asymptotic and practical improvement in the runtime of finding VAMP solutions in several illustrative domains. To the best of our knowledge, this is the first use of a fully persistent data structure for accelerating motion planning.