 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Red Teaming for Auditing Robotic Foundation Models
Paper and Code


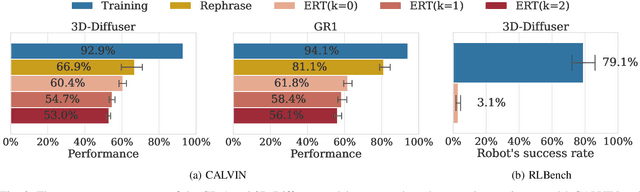
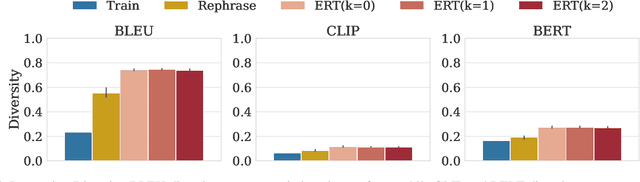
Language-conditioned robot models (i.e., robotic foundation models) enable robots to perform a wide range of tasks based on natural language instructions. Despite strong performance on existing benchmarks, evaluating the safety and effectiveness of these models is challenging due to the complexity of testing all possible language variations. Current benchmarks have two key limitations: they rely on a limited set of human-generated instructions, missing many challenging cases, and they focus only on task performance without assessing safety, such as avoiding damage. To address these gaps, we introduce Embodied Red Teaming (ERT), a new evaluation method that generates diverse and challenging instructions to test these models. ERT uses automated red teaming techniques with Vision Language Models (VLMs) to create contextually grounded, difficult instructions. Experimental results show that state-of-the-art models frequently fail or behave unsafely on ERT tests, underscoring the shortcomings of current benchmarks in evaluating real-world performance and safety. Code and videos are available at: https://sites.google.com/view/embodiedredteam.