 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-box Explanation of Object Detectors via Saliency Maps
Paper and Code

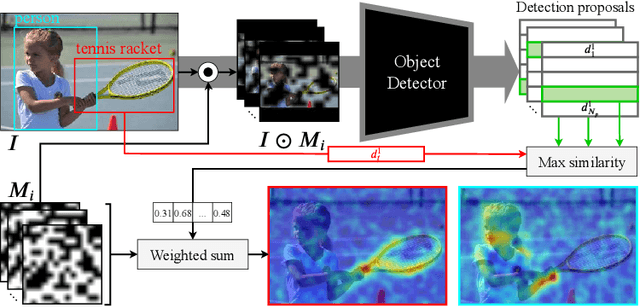
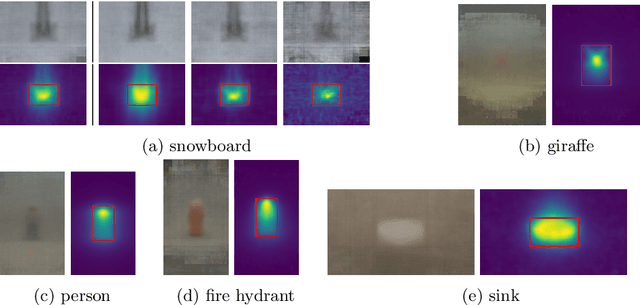
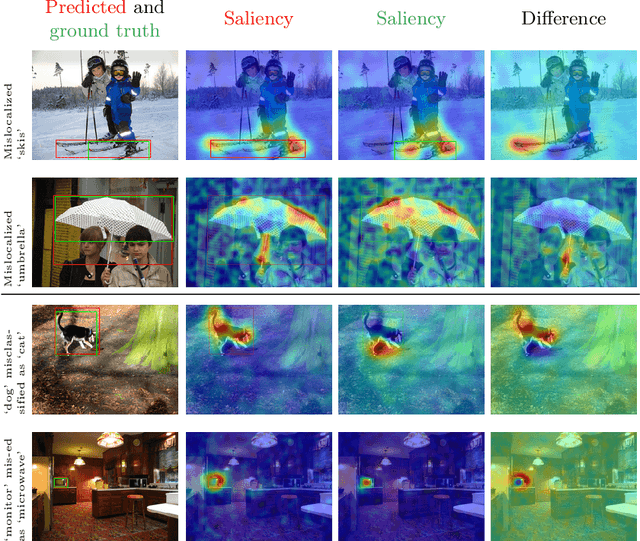
We propose D-RISE, a method for generating visual explanations for the predictions of object detectors. D-RISE can be considered "black-box" in the software testing sense, it only needs access to the inputs and outputs of an object detector. Compared to gradient-based methods, D-RISE is more general and agnostic to the particular type of object detector being tested as it does not need to know about the inner workings of the model. We show that D-RISE can be easily applied to different object detectors including one-stage detectors such as YOLOv3 and two-stage detectors such as Faster-RCNN. We present a detailed analysis of the generated visual explanations to highlight the utilization of context and the possible biases learned by object detectors.