 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Recover: Dynamic Reward Shaping with Wheel-Leg Coordination for Fallen Robots
Jun 05, 2025Adaptive recovery from fall incidents are essential skills for the practical deployment of wheeled-legged robots, which uniquely combine the agility of legs with the speed of wheels for rapid recovery. However, traditional methods relying on preplanned recovery motions, simplified dynamics or sparse rewards often fail to produce robust recovery policies. This paper presents a learning-based framework integrating Episode-based Dynamic Reward Shaping and curriculum learning, which dynamically balances exploration of diverse recovery maneuvers with precise posture refinement. An asymmetric actor-critic architecture accelerates training by leveraging privileged information in simulation, while noise-injected observations enhance robustness against uncertainties. We further demonstrate that synergistic wheel-leg coordination reduces joint torque consumption by 15.8% and 26.2% and improves stabilization through energy transfer mechanisms. Extensive evaluations on two distinct quadruped platforms achieve recovery success rates up to 99.1% and 97.8% without platform-specific tuning. The supplementary material is available at https://boyuandeng.github.io/L2R-WheelLegCoordination/
Semantic-based Loco-Manipulation for Human-Robot Collaboration in Industrial Environments
Dec 22, 2023Robots with a high level of autonomy are increasingly requested by smart industries. A way to reduce the workers' stress and effort is to optimize the working environment by taking advantage of autonomous collaborative robots. A typical task for Human-Robot Collaboration (HRC) which improves the working setup in an industrial environment is the \textit{"bring me an object please"} where the user asks the collaborator to search for an object while he/she is focused on something else. As often happens, science fiction is ahead of the times, indeed, in the \textit{Iron Man} movie, the robot \textit{Dum-E} helps its creator, \textit{Tony Stark}, to create its famous armours. The ability of the robot to comprehend the semantics of the environment and engage with it is valuable for the human execution of more intricate tasks. In this work, we reproduce this operation to enable a mobile robot with manipulation and grasping capabilities to leverage its geometric and semantic understanding of the environment for the execution of the \textit{Bring Me} action, thereby assisting a worker autonomously. Results are provided to validate the proposed workflow in a simulated environment populated with objects and people. This framework aims to take a step forward in assistive robotics autonomy for industries and domestic environments.
FollowMe: a Robust Person Following Framework Based on Re-Identification and Gestures
Nov 21, 2023



Human-robot interaction (HRI) has become a crucial enabler in houses and industries for facilitating operational flexibility. When it comes to mobile collaborative robots, this flexibility can be further increased due to the autonomous mobility and navigation capacity of the robotic agents, expanding their workspace and consequently, the personalizable assistance they can provide to the human operators. This however requires that the robot is capable of detecting and identifying the human counterpart in all stages of the collaborative task, and in particular while following a human in crowded workplaces. To respond to this need, we developed a unified perception and navigation framework, which enables the robot to identify and follow a target person using a combination of visual Re-Identification (Re-ID), hand gestures detection, and collision-free navigation. The Re-ID module can autonomously learn the features of a target person and use the acquired knowledge to visually re-identify the target. The navigation stack is used to follow the target avoiding obstacles and other individuals in the environment. Experiments are conducted with few subjects in a laboratory setting where some unknown dynamic obstacles are introduced.
CARPE-ID: Continuously Adaptable Re-identification for Personalized Robot Assistance
Oct 30, 2023



In today's Human-Robot Interaction (HRI) scenarios, a prevailing tendency exists to assume that the robot shall cooperate with the closest individual or that the scene involves merely a singular human actor. However, in realistic scenarios, such as shop floor operations, such an assumption may not hold and personalized target recognition by the robot in crowded environments is required. To fulfil this requirement, in this work, we propose a person re-identification module based on continual visual adaptation techniques that ensure the robot's seamless cooperation with the appropriate individual even subject to varying visual appearances or partial or complete occlusions. We test the framework singularly using recorded videos in a laboratory environment and an HRI scenario, i.e., a person-following task by a mobile robot. The targets are asked to change their appearance during tracking and to disappear from the camera field of view to test the challenging cases of occlusion and outfit variations. We compare our framework with one of the state-of-the-art Multi-Object Tracking (MOT) methods and the results show that the CARPE-ID can accurately track each selected target throughout the experiments in all the cases (except two limit cases). At the same time, the s-o-t-a MOT has a mean of 4 tracking errors for each video.
Artifacts Mapping: Multi-Modal Semantic Mapping for Object Detection and 3D Localization
Jul 03, 2023Geometric navigation is nowadays a well-established field of robotics and the research focus is shifting towards higher-level scene understanding, such as Semantic Mapping. When a robot needs to interact with its environment, it must be able to comprehend the contextual information of its surroundings. This work focuses on classifying and localising objects within a map, which is under construction (SLAM) or already built. To further explore this direction, we propose a framework that can autonomously detect and localize predefined objects in a known environment using a multi-modal sensor fusion approach (combining RGB and depth data from an RGB-D camera and a lidar). The framework consists of three key elements: understanding the environment through RGB data, estimating depth through multi-modal sensor fusion, and managing artifacts (i.e., filtering and stabilizing measurements). The experiments show that the proposed framework can accurately detect 98% of the objects in the real sample environment, without post-processing, while 85% and 80% of the objects were mapped using the single RGBD camera or RGB + lidar setup respectively. The comparison with single-sensor (camera or lidar) experiments is performed to show that sensor fusion allows the robot to accurately detect near and far obstacles, which would have been noisy or imprecise in a purely visual or laser-based approach.
Optimization-Based Quadrupedal Hybrid Wheeled-Legged Locomotion
Jul 15, 2021
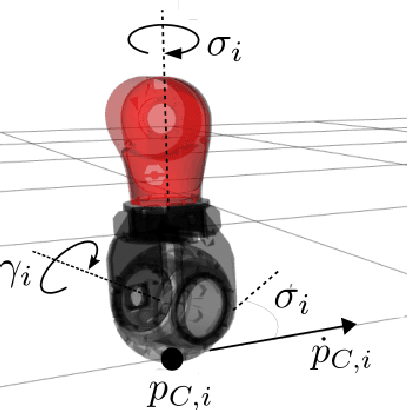
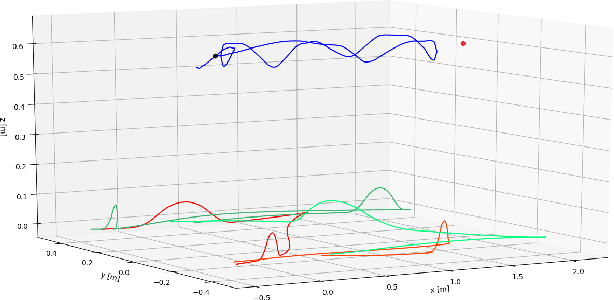
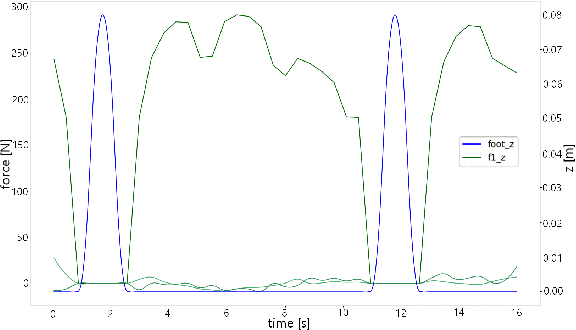
Hybrid wheeled-legged locomotion is a navigation paradigm only recently opened up by novel robotic designs,e.g. the centaur-type humanoid CENTAURO [1] or the quadruped ANYmal [2] in its configuration featuring non-steerable wheels. The term Hybrid Locomotion is hereafter used to indicate a particular type of locomotion, achieved with simultaneous and coordinate use of legs and wheels,see Fig. 1. Such choice stems at the intersection between legged locomotion and the simpler wheeled navigation, in order to get the best from both techniques: agility and ability to traverse uneven terrains from the first, speed and stability from the second. As a consequence, the problem of planning feasible trajectories for a hybrid robot shares many similarities with the legged locomotion problem: also in the hybrid case the motion of the base is reached through contact of the feet with the environment, taking into account that the wheeled feet can just push on the ground and not pull it. Forces compatible with friction cones have to be considered, while the contacts can slide just along the direction prescribed by the orientation of the wheels.