 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-based Loco-Manipulation for Human-Robot Collaboration in Industrial Environments
Dec 22, 2023Robots with a high level of autonomy are increasingly requested by smart industries. A way to reduce the workers' stress and effort is to optimize the working environment by taking advantage of autonomous collaborative robots. A typical task for Human-Robot Collaboration (HRC) which improves the working setup in an industrial environment is the \textit{"bring me an object please"} where the user asks the collaborator to search for an object while he/she is focused on something else. As often happens, science fiction is ahead of the times, indeed, in the \textit{Iron Man} movie, the robot \textit{Dum-E} helps its creator, \textit{Tony Stark}, to create its famous armours. The ability of the robot to comprehend the semantics of the environment and engage with it is valuable for the human execution of more intricate tasks. In this work, we reproduce this operation to enable a mobile robot with manipulation and grasping capabilities to leverage its geometric and semantic understanding of the environment for the execution of the \textit{Bring Me} action, thereby assisting a worker autonomously. Results are provided to validate the proposed workflow in a simulated environment populated with objects and people. This framework aims to take a step forward in assistive robotics autonomy for industries and domestic environments.
FollowMe: a Robust Person Following Framework Based on Re-Identification and Gestures
Nov 21, 2023



Human-robot interaction (HRI) has become a crucial enabler in houses and industries for facilitating operational flexibility. When it comes to mobile collaborative robots, this flexibility can be further increased due to the autonomous mobility and navigation capacity of the robotic agents, expanding their workspace and consequently, the personalizable assistance they can provide to the human operators. This however requires that the robot is capable of detecting and identifying the human counterpart in all stages of the collaborative task, and in particular while following a human in crowded workplaces. To respond to this need, we developed a unified perception and navigation framework, which enables the robot to identify and follow a target person using a combination of visual Re-Identification (Re-ID), hand gestures detection, and collision-free navigation. The Re-ID module can autonomously learn the features of a target person and use the acquired knowledge to visually re-identify the target. The navigation stack is used to follow the target avoiding obstacles and other individuals in the environment. Experiments are conducted with few subjects in a laboratory setting where some unknown dynamic obstacles are introduced.
Artifacts Mapping: Multi-Modal Semantic Mapping for Object Detection and 3D Localization
Jul 03, 2023Geometric navigation is nowadays a well-established field of robotics and the research focus is shifting towards higher-level scene understanding, such as Semantic Mapping. When a robot needs to interact with its environment, it must be able to comprehend the contextual information of its surroundings. This work focuses on classifying and localising objects within a map, which is under construction (SLAM) or already built. To further explore this direction, we propose a framework that can autonomously detect and localize predefined objects in a known environment using a multi-modal sensor fusion approach (combining RGB and depth data from an RGB-D camera and a lidar). The framework consists of three key elements: understanding the environment through RGB data, estimating depth through multi-modal sensor fusion, and managing artifacts (i.e., filtering and stabilizing measurements). The experiments show that the proposed framework can accurately detect 98% of the objects in the real sample environment, without post-processing, while 85% and 80% of the objects were mapped using the single RGBD camera or RGB + lidar setup respectively. The comparison with single-sensor (camera or lidar) experiments is performed to show that sensor fusion allows the robot to accurately detect near and far obstacles, which would have been noisy or imprecise in a purely visual or laser-based approach.
Design and Validation of a Multi-Arm Relocatable Manipulator for Space Applications
Jan 24, 2023



This work presents the computational design and validation of the Multi-Arm Relocatable Manipulator (MARM), a three-limb robot for space applications, with particular reference to the MIRROR (i.e., the Multi-arm Installation Robot for Readying ORUs and Reflectors) use-case scenario as proposed by the European Space Agency. A holistic computational design and validation pipeline is proposed, with the aim of comparing different limb designs, as well as ensuring that valid limb candidates enable MARM to perform the complex loco-manipulation tasks required. Motivated by the task complexity in terms of kinematic reachability, (self)-collision avoidance, contact wrench limits, and motor torque limits affecting Earth experiments, this work leverages on multiple state-of-art planning and control approaches to aid the robot design and validation. These include sampling-based planning on manifolds, non-linear trajectory optimization, and quadratic programs for inverse dynamics computations with constraints. Finally, we present the attained MARM design and conduct preliminary tests for hardware validation through a set of lab experiments.
WoLF: the Whole-body Locomotion Framework for Quadruped Robots
May 13, 2022
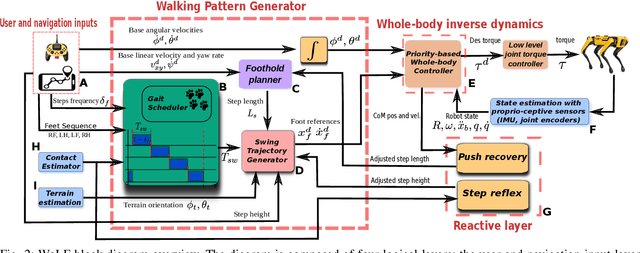
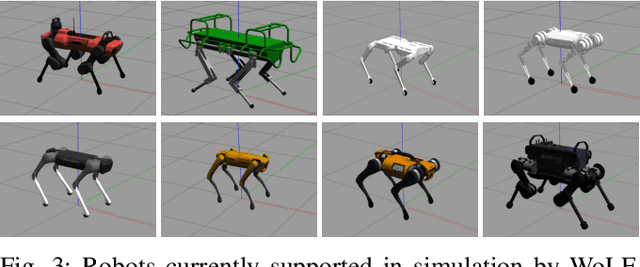
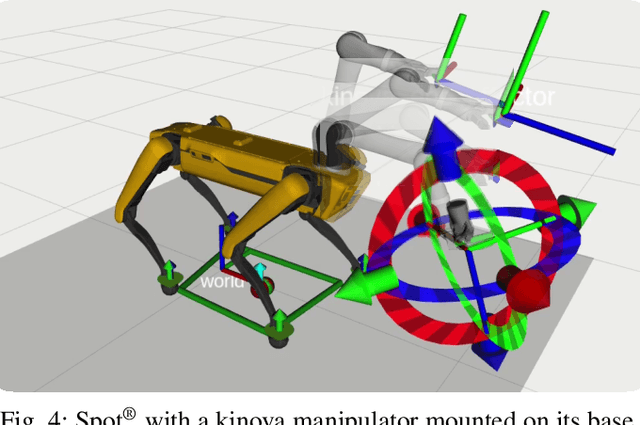
The Whole-Body Locomotion Framework (WoLF) is an end-to-end software suite devoted to the loco-manipulation of quadruped robots. WoLF abstracts the complexity of planning and control of quadrupedal robot hardware into a simple to use and robust software that can be connected through multiple tele-operation devices to different quadruped robot models. Furthermore, WoLF allows controlling mounted devices, such as arms or pan-tilt cameras, jointly with the quadrupedal platform. In this short paper, we introduce the main features of WoLF and its overall software architecture.
Feasible Region: an Actuation-Aware Extension of the Support Region
Mar 19, 2019
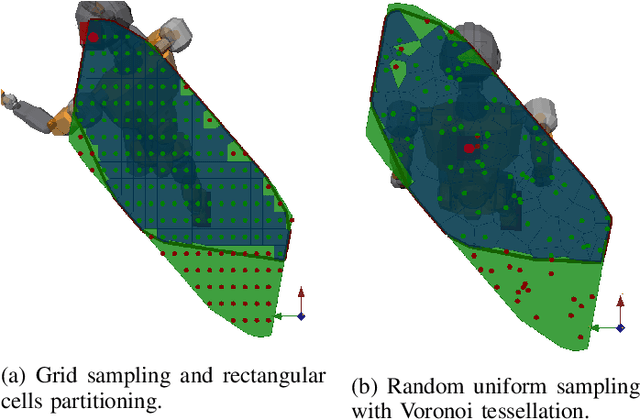
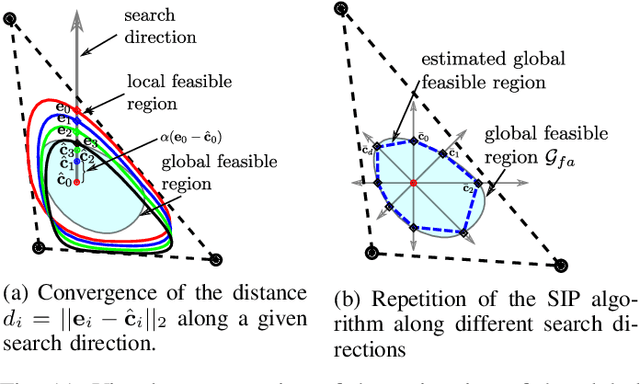
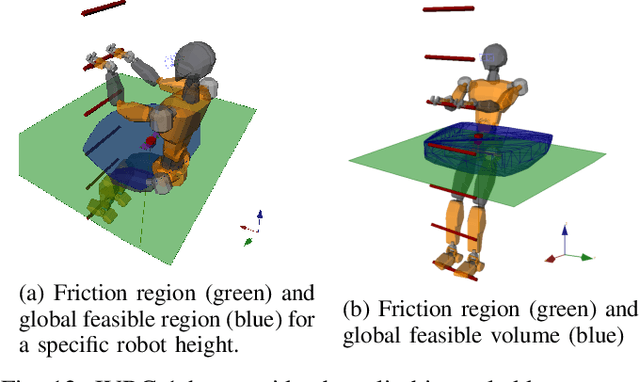
In legged locomotion the support region is defined as the 2D horizontal convex area where the robot is able to support its own body weight in static conditions. Despite this definition, when the joint-torque limits (actuation limits) are hit, the robot can be unable to carry its own body weight, even when the projection of its Center of Mass (CoM) lies inside the support region. In this manuscript we overcome this inconsistency by defining the Feasible Region, a revisited support region that guarantees both global static stability of the robot and the existence of a set of joint torques that are able to sustain the body weight. Thanks to the usage of an Iterative Projection (IP) algorithm, we show that the Feasible Region can be efficiently employed for online motion planning of loco-manipulation tasks for both humanoids and quadrupeds. Unlike the classical support region, the Feasible Region represents a local measure of the robots robustness to external disturbances and it must be recomputed at every configuration change. For this, we also propose a global extension of the Feasible Region that is configuration independent and only needs to be recomputed at every stance change.