 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiquiRIS: A Major Step Towards Fast Beam Switching in Liquid Crystal-based RISs
Oct 28, 2024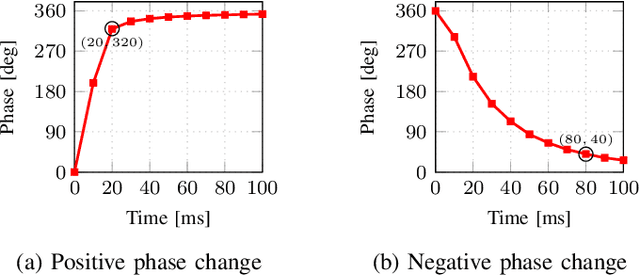
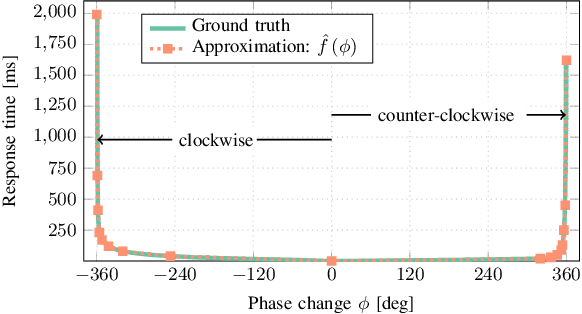
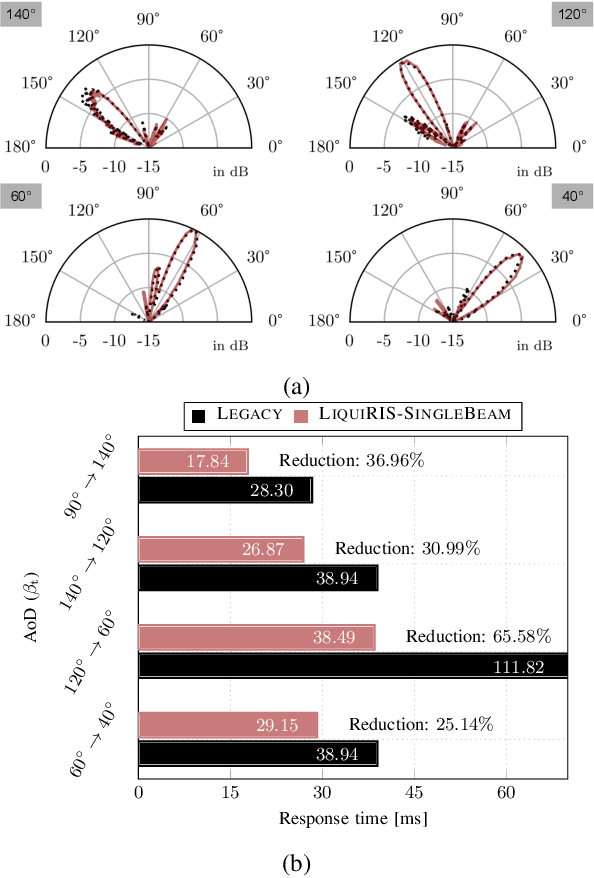
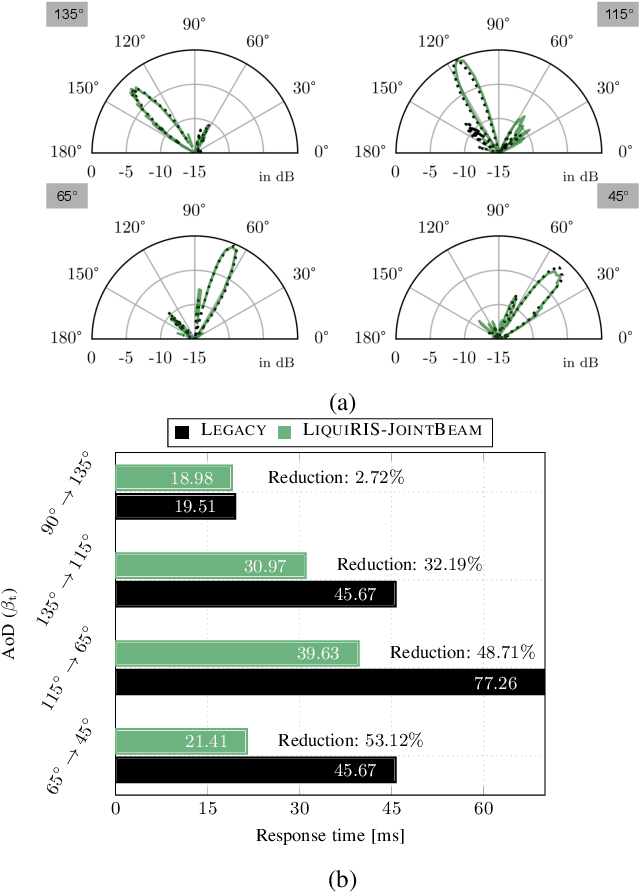
Reconfigurable intelligent surfaces (RISs) offer enhanced control over propagation through phase and amplitude manipulation but face practical challenges like cost and power usage, especially at high frequencies. This is specifically a major problem at high frequencies (Ka- and V-band) where the high cost of semiconductor components (i.e., diodes, varactors, MEMSs) can make RISs prohibitively costly. In recent years, it is shown that liquid crystals (LCs) are low-cost and low-energy alternative which can address the aforementioned challenges but at the cost of lower response time. In LiquiRIS, we enable leveraging LC-based RIS in mobile networks. Specifically, we devise techniques that minimize the beam switching time of LC-based RIS by tapping into the physical properties of LCs and the underlying mathematical principles of beamforming. We achieve this by modeling and optimizing the beamforming vector to account for the rotation characteristics of LC molecules to reduce their transition time from one state to another. In addition to prototyping the proposed system, we show via extensive experimental analysis that LiquiRIS substantially reduces the response time (up to 70.80%) of liquid crystal surface (LCS).
BeamSec: A Practical mmWave Physical Layer Security Scheme Against Strong Adversaries
Sep 19, 2023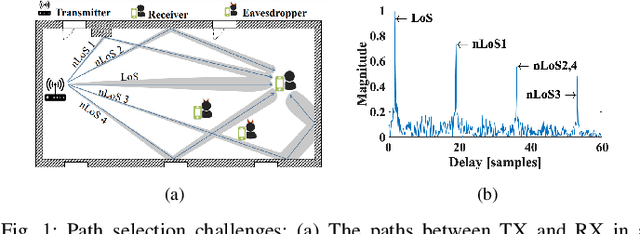
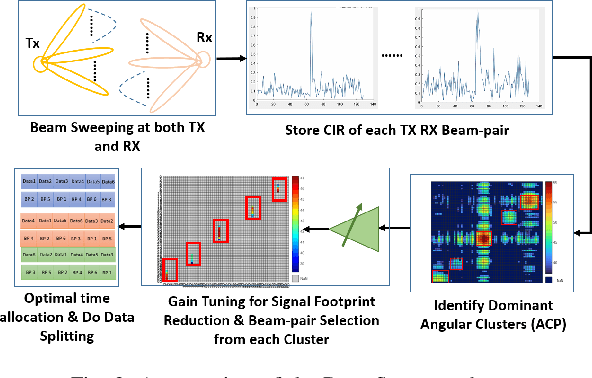
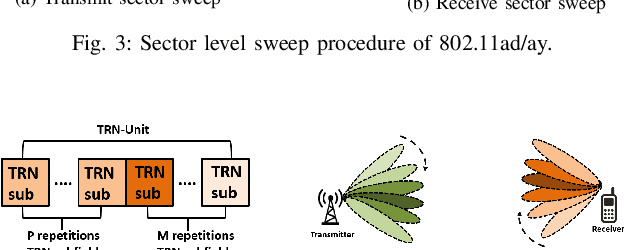
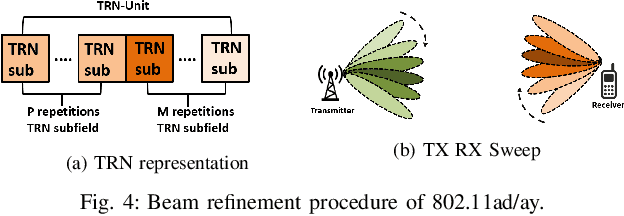
The high directionality of millimeter-wave (mmWave) communication systems has proven effective in reducing the attack surface against eavesdropping, thus improving the physical layer security. However, even with highly directional beams, the system is still exposed to eavesdropping against adversaries located within the main lobe. In this paper, we propose \acrshort{BSec}, a solution to protect the users even from adversaries located in the main lobe. The key feature of BeamSec are: (i) Operating without the knowledge of eavesdropper's location/channel; (ii) Robustness against colluding eavesdropping attack and (iii) Standard compatibility, which we prove using experiments via our IEEE 802.11ad/ay-compatible 60 GHz phased-array testbed. Methodologically, BeamSec first identifies uncorrelated and diverse beam-pairs between the transmitter and receiver by analyzing signal characteristics available through standard-compliant procedures. Next, it encodes the information jointly over all selected beam-pairs to minimize information leakage. We study two methods for allocating transmission time among different beams, namely uniform allocation (no knowledge of the wireless channel) and optimal allocation for maximization of the secrecy rate (with partial knowledge of the wireless channel). Our experiments show that \acrshort{BSec} outperforms the benchmark schemes against single and colluding eavesdroppers and enhances the secrecy rate by 79.8% over a random paths selection benchmark.
Continual Source-Free Unsupervised Domain Adaptation
Apr 14, 2023Existing Source-free Unsupervised Domain Adaptation (SUDA) approaches inherently exhibit catastrophic forgetting. Typically, models trained on a labeled source domain and adapted to unlabeled target data improve performance on the target while dropping performance on the source, which is not available during adaptation. In this study, our goal is to cope with the challenging problem of SUDA in a continual learning setting, i.e., adapting to the target(s) with varying distributional shifts while maintaining performance on the source. The proposed framework consists of two main stages: i) a SUDA model yielding cleaner target labels -- favoring good performance on target, and ii) a novel method for synthesizing class-conditioned source-style images by leveraging only the source model and pseudo-labeled target data as a prior. An extensive pool of experiments on major benchmarks, e.g., PACS, Visda-C, and DomainNet demonstrates that the proposed Continual SUDA (C-SUDA) framework enables preserving satisfactory performance on the source domain without exploiting the source data at all.
Compact CNN Structure Learning by Knowledge Distillation
Apr 19, 2021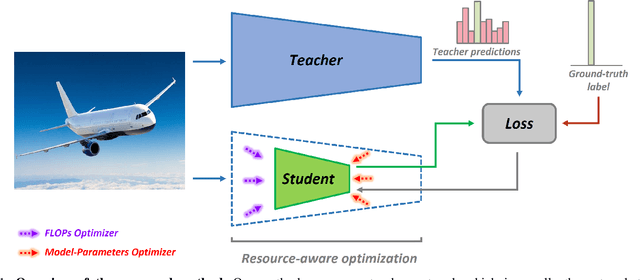
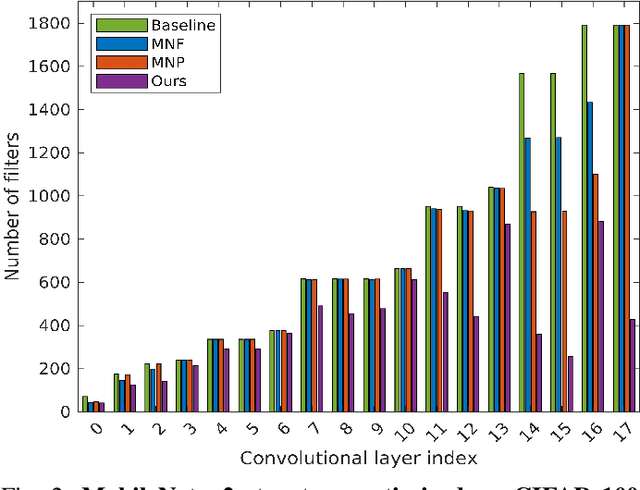
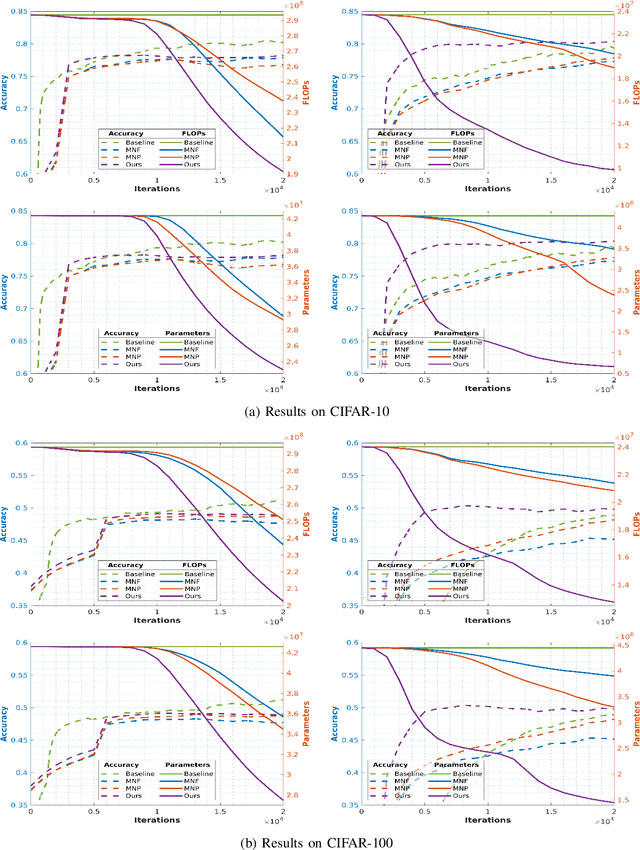
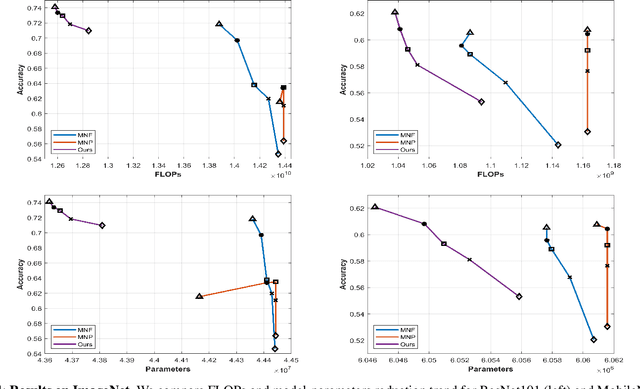
The concept of compressing deep Convolutional Neural Networks (CNNs) is essential to use limited computation, power, and memory resources on embedded devices. However, existing methods achieve this objective at the cost of a drop in inference accuracy in computer vision tasks. To address such a drawback, we propose a framework that leverages knowledge distillation along with customizable block-wise optimization to learn a lightweight CNN structure while preserving better control over the compression-performance tradeoff. Considering specific resource constraints, e.g., floating-point operations per inference (FLOPs) or model-parameters, our method results in a state of the art network compression while being capable of achieving better inference accuracy. In a comprehensive evaluation, we demonstrate that our method is effective, robust, and consistent with results over a variety of network architectures and datasets, at negligible training overhead. In particular, for the already compact network MobileNet_v2, our method offers up to 2x and 5.2x better model compression in terms of FLOPs and model-parameters, respectively, while getting 1.05% better model performance than the baseline network.
Adaptive Pseudo-Label Refinement by Negative Ensemble Learning for Source-Free Unsupervised Domain Adaptation
Mar 29, 2021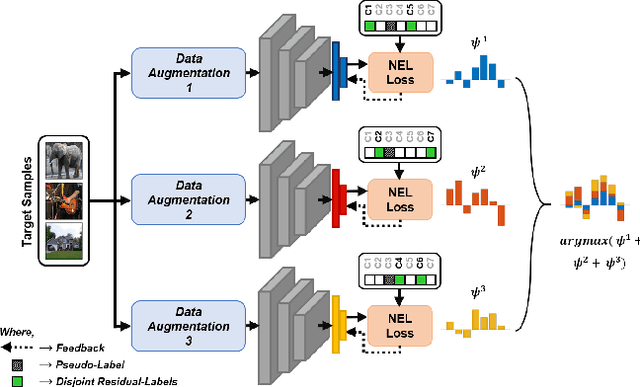
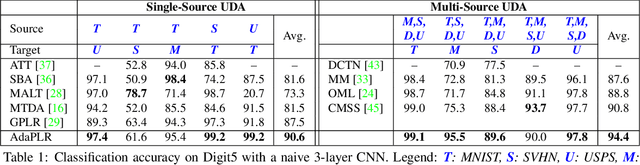
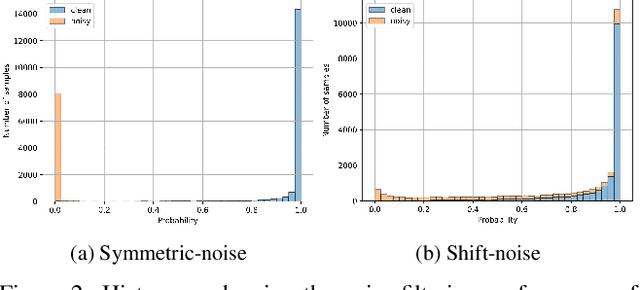
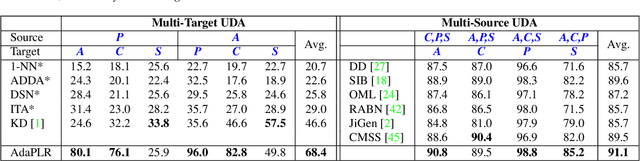
The majority of existing Unsupervised Domain Adaptation (UDA) methods presumes source and target domain data to be simultaneously available during training. Such an assumption may not hold in practice, as source data is often inaccessible (e.g., due to privacy reasons). On the contrary, a pre-trained source model is always considered to be available, even though performing poorly on target due to the well-known domain shift problem. This translates into a significant amount of misclassifications, which can be interpreted as structured noise affecting the inferred target pseudo-labels. In this work, we cast UDA as a pseudo-label refinery problem in the challenging source-free scenario. We propose a unified method to tackle adaptive noise filtering and pseudo-label refinement. A novel Negative Ensemble Learning technique is devised to specifically address noise in pseudo-labels, by enhancing diversity in ensemble members with different stochastic (i) input augmentation and (ii) feedback. In particular, the latter is achieved by leveraging the novel concept of Disjoint Residual Labels, which allow diverse information to be fed to the different members. A single target model is eventually trained with the refined pseudo-labels, which leads to a robust performance on the target domain. Extensive experiments show that the proposed method, named Adaptive Pseudo-Label Refinement, achieves state-of-the-art performance on major UDA benchmarks, such as Digit5, PACS, Visda-C, and DomainNet, without using source data at all.
Towards Formal Fault Tree Analysis using Theorem Proving
May 08, 2015
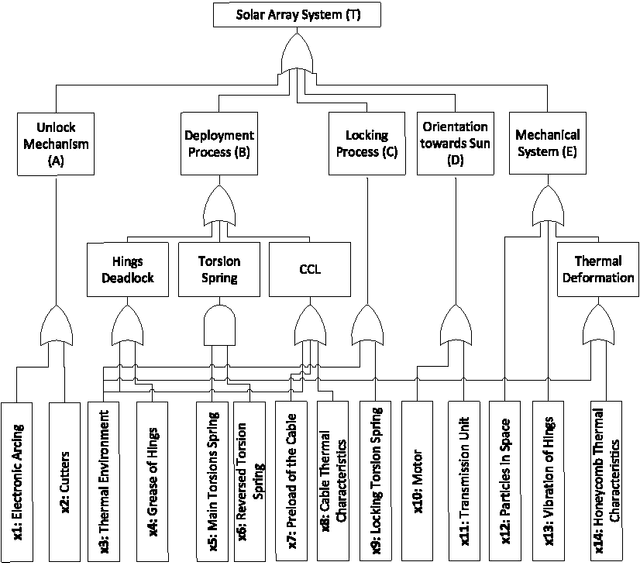

Fault Tree Analysis (FTA) is a dependability analysis technique that has been widely used to predict reliability, availability and safety of many complex engineering systems. Traditionally, these FTA-based analyses are done using paper-and-pencil proof methods or computer simulations, which cannot ascertain absolute correctness due to their inherent limitations. As a complementary approach, we propose to use the higher-order-logic theorem prover HOL4 to conduct the FTA-based analysis of safety-critical systems where accuracy of failure analysis is a dire need. In particular, the paper presents a higher-order-logic formalization of generic Fault Tree gates, i.e., AND, OR, NAND, NOR, XOR and NOT and the formal verification of their failure probability expressions. Moreover, we have formally verified the generic probabilistic inclusion-exclusion principle, which is one of the foremost requirements for conducting the FTA-based failure analysis of any given system. For illustration purposes, we conduct the FTA-based failure analysis of a solar array that is used as the main source of power for the Dong Fang Hong-3 (DFH-3) satellite.