 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Pseudo-Label Refinement by Negative Ensemble Learning for Source-Free Unsupervised Domain Adaptation
Paper and Code
Mar 29, 2021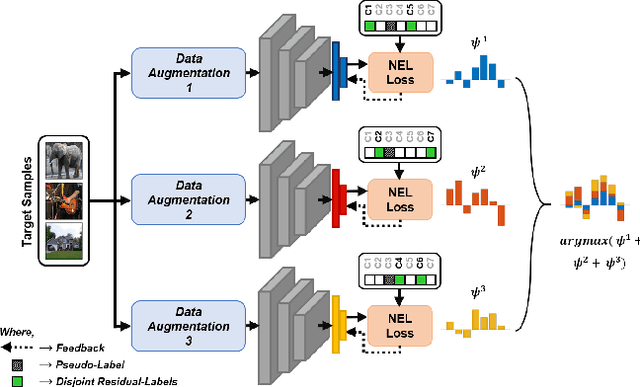
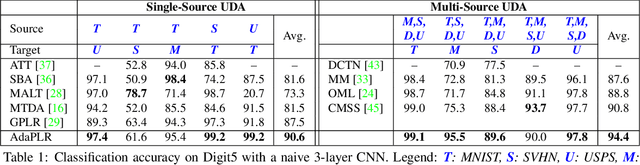
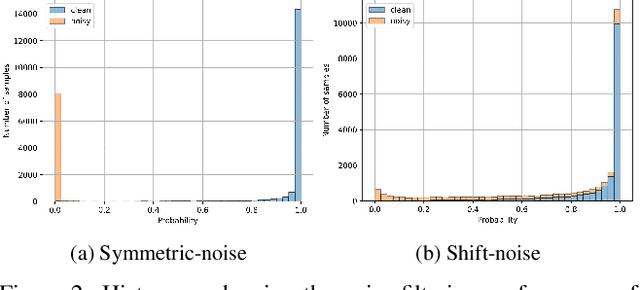
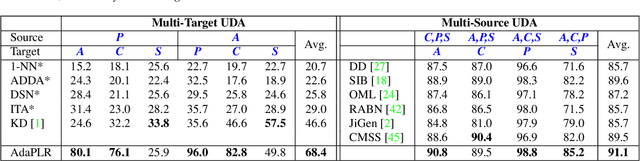
The majority of existing Unsupervised Domain Adaptation (UDA) methods presumes source and target domain data to be simultaneously available during training. Such an assumption may not hold in practice, as source data is often inaccessible (e.g., due to privacy reasons). On the contrary, a pre-trained source model is always considered to be available, even though performing poorly on target due to the well-known domain shift problem. This translates into a significant amount of misclassifications, which can be interpreted as structured noise affecting the inferred target pseudo-labels. In this work, we cast UDA as a pseudo-label refinery problem in the challenging source-free scenario. We propose a unified method to tackle adaptive noise filtering and pseudo-label refinement. A novel Negative Ensemble Learning technique is devised to specifically address noise in pseudo-labels, by enhancing diversity in ensemble members with different stochastic (i) input augmentation and (ii) feedback. In particular, the latter is achieved by leveraging the novel concept of Disjoint Residual Labels, which allow diverse information to be fed to the different members. A single target model is eventually trained with the refined pseudo-labels, which leads to a robust performance on the target domain. Extensive experiments show that the proposed method, named Adaptive Pseudo-Label Refinement, achieves state-of-the-art performance on major UDA benchmarks, such as Digit5, PACS, Visda-C, and DomainNet, without using source data at all.