 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-efficient learning of object-centric grasp preferences
Mar 01, 2022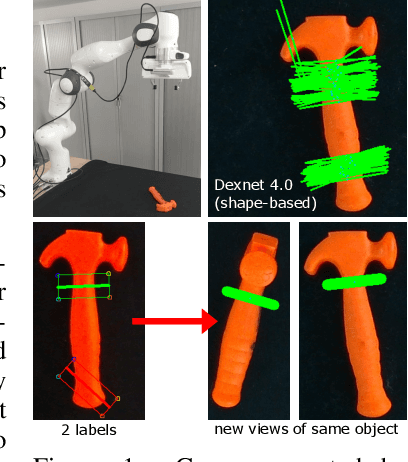
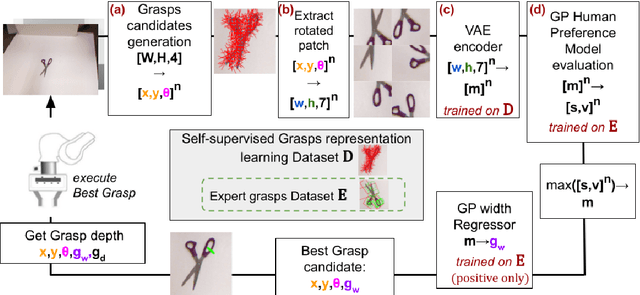
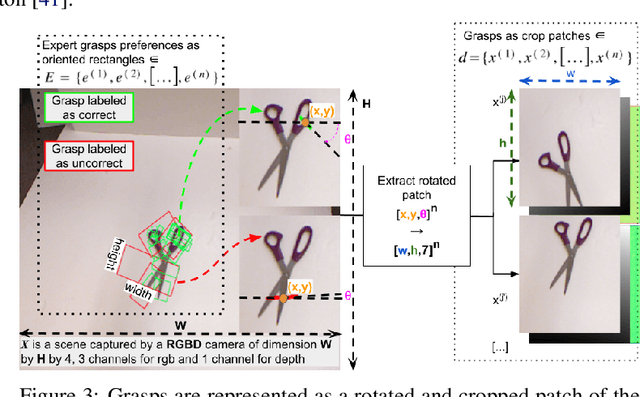

Grasping made impressive progress during the last few years thanks to deep learning. However, there are many objects for which it is not possible to choose a grasp by only looking at an RGB-D image, might it be for physical reasons (e.g., a hammer with uneven mass distribution) or task constraints (e.g., food that should not be spoiled). In such situations, the preferences of experts need to be taken into account. In this paper, we introduce a data-efficient grasping pipeline (Latent Space GP Selector -- LGPS) that learns grasp preferences with only a few labels per object (typically 1 to 4) and generalizes to new views of this object. Our pipeline is based on learning a latent space of grasps with a dataset generated with any state-of-the-art grasp generator (e.g., Dex-Net). This latent space is then used as a low-dimensional input for a Gaussian process classifier that selects the preferred grasp among those proposed by the generator. The results show that our method outperforms both GR-ConvNet and GG-CNN (two state-of-the-art methods that are also based on labeled grasps) on the Cornell dataset, especially when only a few labels are used: only 80 labels are enough to correctly choose 80% of the grasps (885 scenes, 244 objects). Results are similar on our dataset (91 scenes, 28 objects).
VP-GO: a "light" action-conditioned visual prediction model
Sep 26, 2021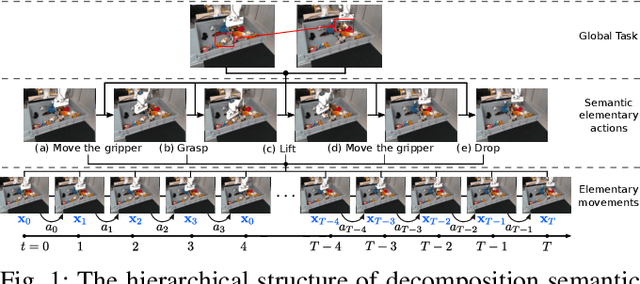
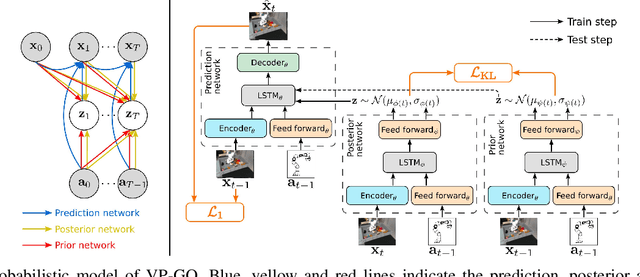

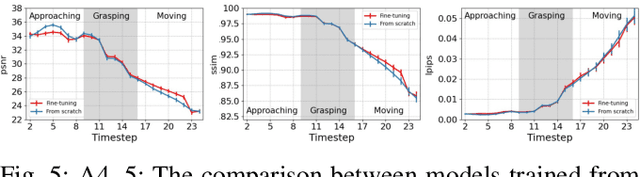
Visual prediction models are a promising solution for visual-based robotic grasping of cluttered, unknown soft objects. Previous models from the literature are computationally greedy, which limits reproducibility; although some consider stochasticity in the prediction model, it is often too weak to catch the reality of robotics experiments involving grasping such objects. Furthermore, previous work focused on elementary movements that are not efficient to reason in terms of more complex semantic actions. To address these limitations, we propose VP-GO, a ``light'' stochastic action-conditioned visual prediction model. We propose a hierarchical decomposition of semantic grasping and manipulation actions into elementary end-effector movements, to ensure compatibility with existing models and datasets for visual prediction of robotic actions such as RoboNet. We also record and release a new open dataset for visual prediction of object grasping, called PandaGrasp. Our model can be pre-trained on RoboNet and fine-tuned on PandaGrasp, and performs similarly to more complex models in terms of signal prediction metrics. Qualitatively, it outperforms when predicting the outcome of complex grasps performed by our robot.