 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVP-GO: a "light" action-conditioned visual prediction model
Sep 26, 2021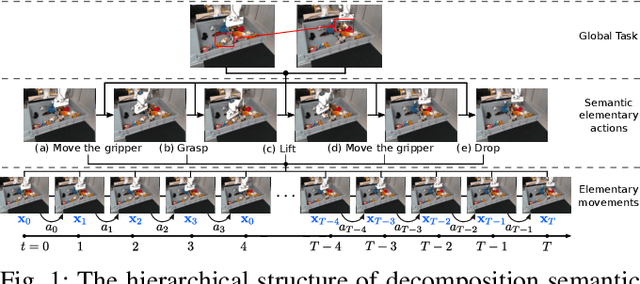
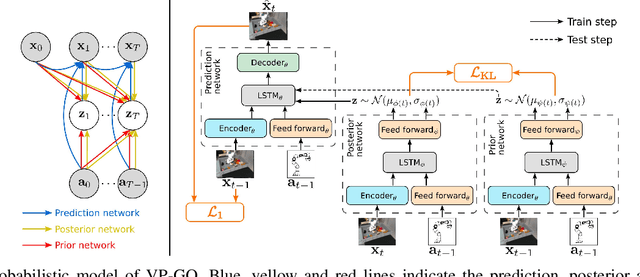

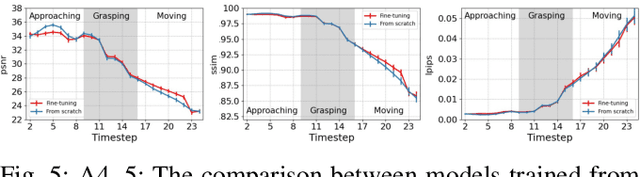
Visual prediction models are a promising solution for visual-based robotic grasping of cluttered, unknown soft objects. Previous models from the literature are computationally greedy, which limits reproducibility; although some consider stochasticity in the prediction model, it is often too weak to catch the reality of robotics experiments involving grasping such objects. Furthermore, previous work focused on elementary movements that are not efficient to reason in terms of more complex semantic actions. To address these limitations, we propose VP-GO, a ``light'' stochastic action-conditioned visual prediction model. We propose a hierarchical decomposition of semantic grasping and manipulation actions into elementary end-effector movements, to ensure compatibility with existing models and datasets for visual prediction of robotic actions such as RoboNet. We also record and release a new open dataset for visual prediction of object grasping, called PandaGrasp. Our model can be pre-trained on RoboNet and fine-tuned on PandaGrasp, and performs similarly to more complex models in terms of signal prediction metrics. Qualitatively, it outperforms when predicting the outcome of complex grasps performed by our robot.