 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElectroencephalogram-based Multi-class Decoding of Attended Speakers' Direction with Audio Spatial Spectrum
Nov 11, 2024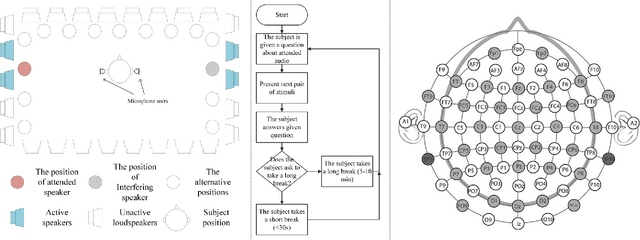
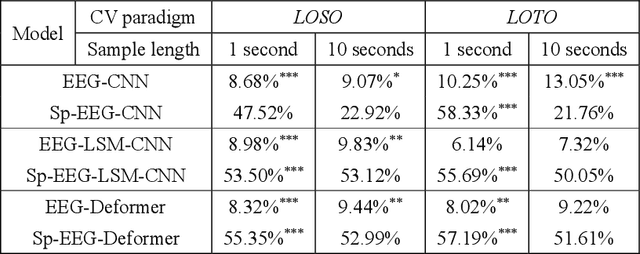
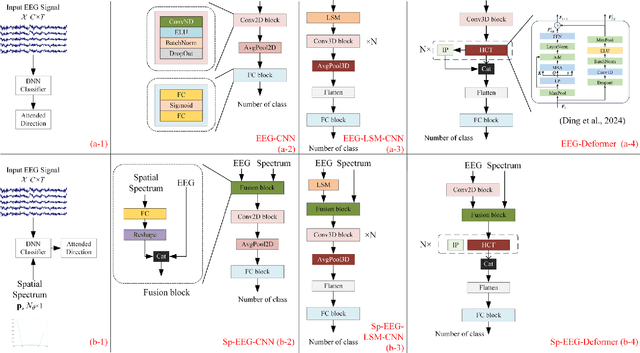
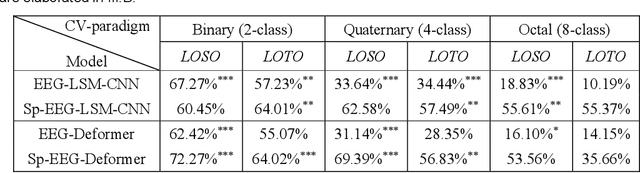
Decoding the directional focus of an attended speaker from listeners' electroencephalogram (EEG) signals is essential for developing brain-computer interfaces to improve the quality of life for individuals with hearing impairment. Previous works have concentrated on binary directional focus decoding, i.e., determining whether the attended speaker is on the left or right side of the listener. However, a more precise decoding of the exact direction of the attended speaker is necessary for effective speech processing. Additionally, audio spatial information has not been effectively leveraged, resulting in suboptimal decoding results. In this paper, we observe that, on our recently presented dataset with 15-class directional focus, models relying exclusively on EEG inputs exhibits significantly lower accuracy when decoding the directional focus in both leave-one-subject-out and leave-one-trial-out scenarios. By integrating audio spatial spectra with EEG features, the decoding accuracy can be effectively improved. We employ the CNN, LSM-CNN, and EEG-Deformer models to decode the directional focus from listeners' EEG signals with the auxiliary audio spatial spectra. The proposed Sp-Aux-Deformer model achieves notable 15-class decoding accuracies of 57.48% and 61.83% in leave-one-subject-out and leave-one-trial-out scenarios, respectively.