 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPMamba-YOLO: An Underwater Object Detection Network Based on Multi-Scale Feature Enhancement and Global Context Modeling
Feb 26, 2026Underwater object detection is a critical yet challenging research problem owing to severe light attenuation, color distortion, background clutter, and the small scale of underwater targets. To address these challenges, we propose SPMamba-YOLO, a novel underwater object detection network that integrates multi-scale feature enhancement with global context modeling. Specifically, a Spatial Pyramid Pooling Enhanced Layer Aggregation Network (SPPELAN) module is introduced to strengthen multi-scale feature aggregation and expand the receptive field, while a Pyramid Split Attention (PSA) mechanism enhances feature discrimination by emphasizing informative regions and suppressing background interference. In addition, a Mamba-based state space modeling module is incorporated to efficiently capture long-range dependencies and global contextual information, thereby improving detection robustness in complex underwater environments. Extensive experiments on the URPC2022 dataset demonstrate that SPMamba-YOLO outperforms the YOLOv8n baseline by more than 4.9\% in mAP@0.5, particularly for small and densely distributed underwater objects, while maintaining a favorable balance between detection accuracy and computational cost.
Enhancing Zeroth-order Fine-tuning for Language Models with Low-rank Structures
Oct 10, 2024



Parameter-efficient fine-tuning (PEFT) significantly reduces memory costs when adapting large language models (LLMs) for downstream applications. However, traditional first-order (FO) fine-tuning algorithms incur substantial memory overhead due to the need to store activation values for back-propagation during gradient computation, particularly in long-context fine-tuning tasks. Zeroth-order (ZO) algorithms offer a promising alternative by approximating gradients using finite differences of function values, thus eliminating the need for activation storage. Nevertheless, existing ZO methods struggle to capture the low-rank gradient structure common in LLM fine-tuning, leading to suboptimal performance. This paper proposes a low-rank ZO gradient estimator and introduces a novel low-rank ZO algorithm (LOZO) that effectively captures this structure in LLMs. We provide convergence guarantees for LOZO by framing it as a subspace optimization method. Additionally, its low-rank nature enables LOZO to integrate with momentum techniques while incurring negligible extra memory costs. Extensive experiments across various model sizes and downstream tasks demonstrate that LOZO and its momentum-based variant outperform existing ZO methods and closely approach the performance of FO algorithms.
Linear interpolation gives better gradients than Gaussian smoothing in derivative-free optimization
Jun 02, 2019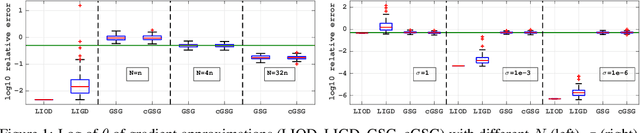
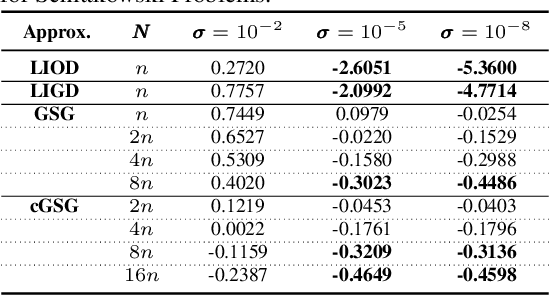
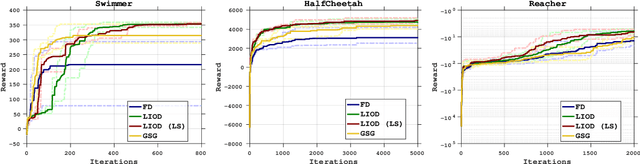
In this paper, we consider derivative free optimization problems, where the objective function is smooth but is computed with some amount of noise, the function evaluations are expensive and no derivative information is available. We are motivated by policy optimization problems in reinforcement learning that have recently become popular [Choromaski et al. 2018; Fazel et al. 2018; Salimans et al. 2016], and that can be formulated as derivative free optimization problems with the aforementioned characteristics. In each of these works some approximation of the gradient is constructed and a (stochastic) gradient method is applied. In [Salimans et al. 2016] the gradient information is aggregated along Gaussian directions, while in [Choromaski et al. 2018] it is computed along orthogonal direction. We provide a convergence rate analysis for a first-order line search method, similar to the ones used in the literature, and derive the conditions on the gradient approximations that ensure this convergence. We then demonstrate via rigorous analysis of the variance and by numerical comparisons on reinforcement learning tasks that the Gaussian sampling method used in [Salimans et al. 2016] is significantly inferior to the orthogonal sampling used in [Choromaski et al. 2018] as well as more general interpolation methods.