 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVicaSplat: A Single Run is All You Need for 3D Gaussian Splatting and Camera Estimation from Unposed Video Frames
Mar 13, 2025We present VicaSplat, a novel framework for joint 3D Gaussians reconstruction and camera pose estimation from a sequence of unposed video frames, which is a critical yet underexplored task in real-world 3D applications. The core of our method lies in a novel transformer-based network architecture. In particular, our model starts with an image encoder that maps each image to a list of visual tokens. All visual tokens are concatenated with additional inserted learnable camera tokens. The obtained tokens then fully communicate with each other within a tailored transformer decoder. The camera tokens causally aggregate features from visual tokens of different views, and further modulate them frame-wisely to inject view-dependent features. 3D Gaussian splats and camera pose parameters can then be estimated via different prediction heads. Experiments show that VicaSplat surpasses baseline methods for multi-view inputs, and achieves comparable performance to prior two-view approaches. Remarkably, VicaSplat also demonstrates exceptional cross-dataset generalization capability on the ScanNet benchmark, achieving superior performance without any fine-tuning. Project page: https://lizhiqi49.github.io/VicaSplat.
IncEventGS: Pose-Free Gaussian Splatting from a Single Event Camera
Oct 10, 2024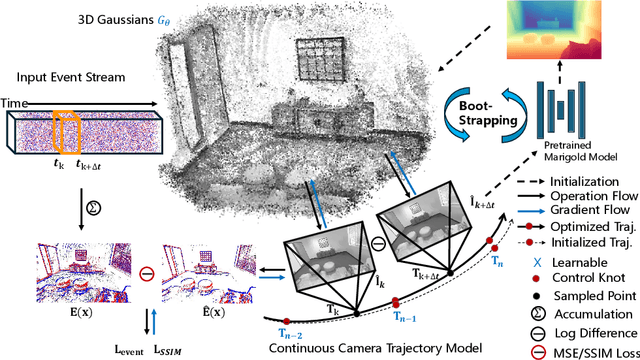



Implicit neural representation and explicit 3D Gaussian Splatting (3D-GS) for novel view synthesis have achieved remarkable progress with frame-based camera (e.g. RGB and RGB-D cameras) recently. Compared to frame-based camera, a novel type of bio-inspired visual sensor, i.e. event camera, has demonstrated advantages in high temporal resolution, high dynamic range, low power consumption and low latency. Due to its unique asynchronous and irregular data capturing process, limited work has been proposed to apply neural representation or 3D Gaussian splatting for an event camera. In this work, we present IncEventGS, an incremental 3D Gaussian Splatting reconstruction algorithm with a single event camera. To recover the 3D scene representation incrementally, we exploit the tracking and mapping paradigm of conventional SLAM pipelines for IncEventGS. Given the incoming event stream, the tracker firstly estimates an initial camera motion based on prior reconstructed 3D-GS scene representation. The mapper then jointly refines both the 3D scene representation and camera motion based on the previously estimated motion trajectory from the tracker. The experimental results demonstrate that IncEventGS delivers superior performance compared to prior NeRF-based methods and other related baselines, even we do not have the ground-truth camera poses. Furthermore, our method can also deliver better performance compared to state-of-the-art event visual odometry methods in terms of camera motion estimation. Code is publicly available at: https://github.com/wu-cvgl/IncEventGS.