 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceBench: Benchmarking LLM-Based Voice Assistants
Paper and Code

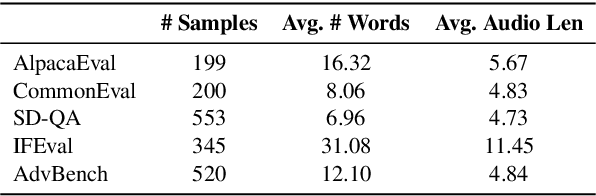

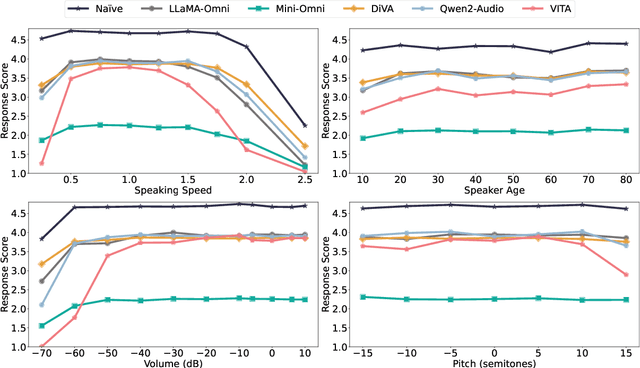
Building on the success of large language models (LLMs), recent advancements such as GPT-4o have enabled real-time speech interactions through LLM-based voice assistants, offering a significantly improved user experience compared to traditional text-based interactions. However, the absence of benchmarks designed to evaluate these speech interaction capabilities has hindered progress of LLM-based voice assistants development. Current evaluations focus primarily on automatic speech recognition (ASR) or general knowledge evaluation with clean speeches, neglecting the more intricate, real-world scenarios that involve diverse speaker characteristics, environmental and content factors. To address this, we introduce VoiceBench, the first benchmark designed to provide a multi-faceted evaluation of LLM-based voice assistants. VoiceBench also includes both real and synthetic spoken instructions that incorporate the above three key real-world variations. Extensive experiments reveal the limitations of current LLM-based voice assistant models and offer valuable insights for future research and development in this field.