 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Sociological Effect Heterogeneity using Machine Learning
Paper and Code
Sep 18, 2019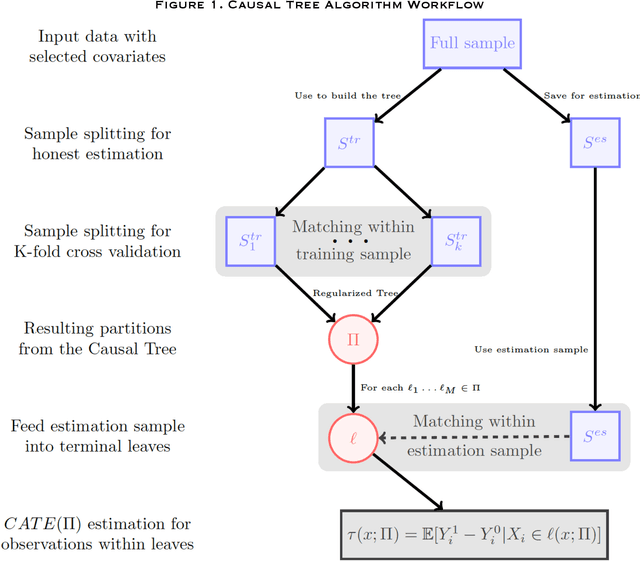



Individuals do not respond uniformly to treatments, events, or interventions. Sociologists routinely partition samples into subgroups to explore how the effects of treatments vary by covariates like race, gender, and socioeconomic status. In so doing, analysts determine the key subpopulations based on theoretical priors. Data-driven discoveries are also routine, yet the analyses by which sociologists typically go about them are problematic and seldom move us beyond our expectations, and biases, to explore new meaningful subgroups. Emerging machine learning methods allow researchers to explore sources of variation that they may not have previously considered, or envisaged. In this paper, we use causal trees to recursively partition the sample and uncover sources of treatment effect heterogeneity. We use honest estimation, splitting the sample into a training sample to grow the tree and an estimation sample to estimate leaf-specific effects. Assessing a central topic in the social inequality literature, college effects on wages, we compare what we learn from conventional approaches for exploring variation in effects to causal trees. Given our use of observational data, we use leaf-specific matching and sensitivity analyses to address confounding and offer interpretations of effects based on observed and unobserved heterogeneity. We encourage researchers to follow similar practices in their work on variation in sociological effects.