 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultistep Quasimetric Learning for Scalable Goal-conditioned Reinforcement Learning
Nov 14, 2025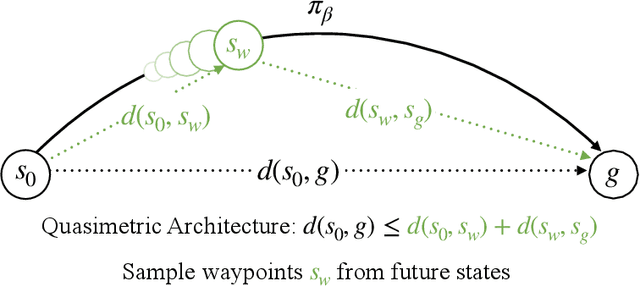


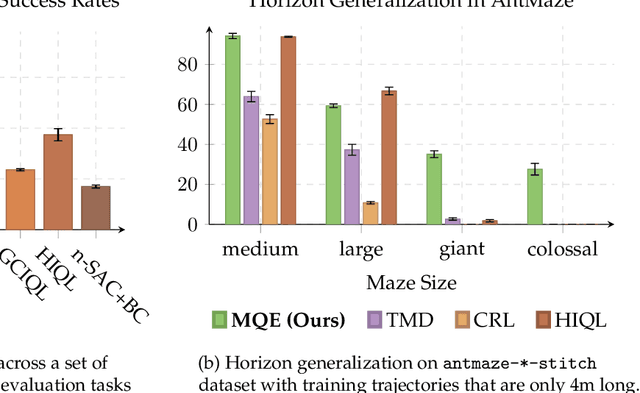
Learning how to reach goals in an environment is a longstanding challenge in AI, yet reasoning over long horizons remains a challenge for modern methods. The key question is how to estimate the temporal distance between pairs of observations. While temporal difference methods leverage local updates to provide optimality guarantees, they often perform worse than Monte Carlo methods that perform global updates (e.g., with multi-step returns), which lack such guarantees. We show how these approaches can be integrated into a practical GCRL method that fits a quasimetric distance using a multistep Monte-Carlo return. We show our method outperforms existing GCRL methods on long-horizon simulated tasks with up to 4000 steps, even with visual observations. We also demonstrate that our method can enable stitching in the real-world robotic manipulation domain (Bridge setup). Our approach is the first end-to-end GCRL method that enables multistep stitching in this real-world manipulation domain from an unlabeled offline dataset of visual observations.
Temporal Representation Alignment: Successor Features Enable Emergent Compositionality in Robot Instruction Following Temporal Representation Alignment
Feb 08, 2025



Effective task representations should facilitate compositionality, such that after learning a variety of basic tasks, an agent can perform compound tasks consisting of multiple steps simply by composing the representations of the constituent steps together. While this is conceptually simple and appealing, it is not clear how to automatically learn representations that enable this sort of compositionality. We show that learning to associate the representations of current and future states with a temporal alignment loss can improve compositional generalization, even in the absence of any explicit subtask planning or reinforcement learning. We evaluate our approach across diverse robotic manipulation tasks as well as in simulation, showing substantial improvements for tasks specified with either language or goal images.
Policy Adaptation via Language Optimization: Decomposing Tasks for Few-Shot Imitation
Aug 29, 2024

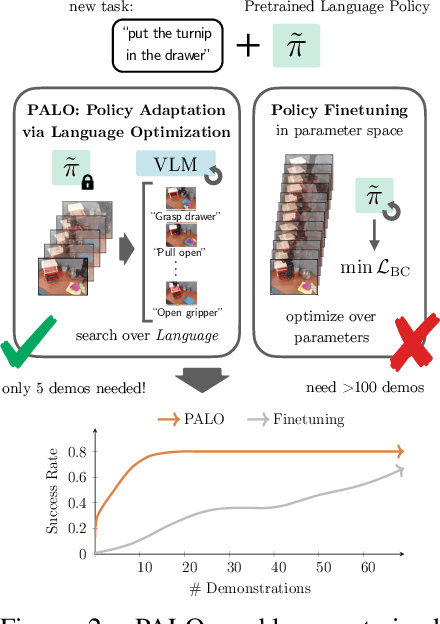

Learned language-conditioned robot policies often struggle to effectively adapt to new real-world tasks even when pre-trained across a diverse set of instructions. We propose a novel approach for few-shot adaptation to unseen tasks that exploits the semantic understanding of task decomposition provided by vision-language models (VLMs). Our method, Policy Adaptation via Language Optimization (PALO), combines a handful of demonstrations of a task with proposed language decompositions sampled from a VLM to quickly enable rapid nonparametric adaptation, avoiding the need for a larger fine-tuning dataset. We evaluate PALO on extensive real-world experiments consisting of challenging unseen, long-horizon robot manipulation tasks. We find that PALO is able of consistently complete long-horizon, multi-tier tasks in the real world, outperforming state of the art pre-trained generalist policies, and methods that have access to the same demonstrations.