 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Graph-based Topic Modeling from Video Transcriptions
Paper and Code
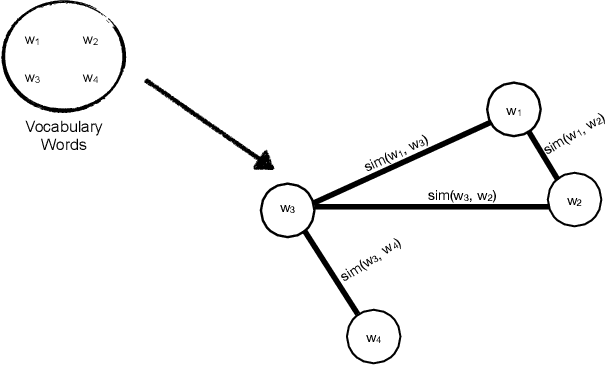



To unfold the tremendous amount of audiovisual data uploaded daily to social media platforms, effective topic modelling techniques are needed. Existing work tends to apply variants of topic models on text data sets. In this paper, we aim at developing a topic extractor on video transcriptions. The model improves coherence by exploiting neural word embeddings through a graph-based clustering method. Unlike typical topic models, this approach works without knowing the true number of topics. Experimental results on the real-life multimodal data set MuSe-CaR demonstrates that our approach extracts coherent and meaningful topics, outperforming baseline methods. Furthermore, we successfully demonstrate the generalisability of our approach on a pure text review data set.