 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Class Ontology and Data Scale Affect Audio Transfer Learning
Mar 26, 2026Transfer learning is a crucial concept within deep learning that allows artificial neural networks to benefit from a large pre-training data basis when confronted with a task of limited data. Despite its ubiquitous use and clear benefits, there are still many open questions regarding the inner workings of transfer learning and, in particular, regarding the understanding of when and how well it works. To that extent, we perform a rigorous study focusing on audio-to-audio transfer learning, in which we pre-train various model states on (ontology-based) subsets of AudioSet and fine-tune them on three computer audition tasks, namely acoustic scene recognition, bird activity recognition, and speech command recognition. We report that increasing the number of samples and classes in the pre-training data both have a positive impact on transfer learning. This is, however, generally surpassed by similarity between pre-training and the downstream task, which can lead the model to learn comparable features.
Enhancing Efficiency and Performance in Deepfake Audio Detection through Neuron-level dropin & Neuroplasticity Mechanisms
Mar 25, 2026Current audio deepfake detection has achieved remarkable performance using diverse deep learning architectures such as ResNet, and has seen further improvements with the introduction of large models (LMs) like Wav2Vec. The success of large language models (LLMs) further demonstrates the benefits of scaling model parameters, but also highlights one bottleneck where performance gains are constrained by parameter counts. Simply stacking additional layers, as done in current LLMs, is computationally expensive and requires full retraining. Furthermore, existing low-rank adaptation methods are primarily applied to attention-based architectures, which limits their scope. Inspired by the neuronal plasticity observed in mammalian brains, we propose novel algorithms, dropin and further plasticity, that dynamically adjust the number of neurons in certain layers to flexibly modulate model parameters. We evaluate these algorithms on multiple architectures, including ResNet, Gated Recurrent Neural Networks, and Wav2Vec. Experimental results using the widely recognised ASVSpoof2019 LA, PA, and FakeorReal dataset demonstrate consistent improvements in computational efficiency with the dropin approach and a maximum of around 39% and 66% relative reduction in Equal Error Rate with the dropin and plasticity approach among these dataset, respectively. The code and supplementary material are available at Github link.
Large Language Models for Depression Recognition in Spoken Language Integrating Psychological Knowledge
May 28, 2025Depression is a growing concern gaining attention in both public discourse and AI research. While deep neural networks (DNNs) have been used for recognition, they still lack real-world effectiveness. Large language models (LLMs) show strong potential but require domain-specific fine-tuning and struggle with non-textual cues. Since depression is often expressed through vocal tone and behaviour rather than explicit text, relying on language alone is insufficient. Diagnostic accuracy also suffers without incorporating psychological expertise. To address these limitations, we present, to the best of our knowledge, the first application of LLMs to multimodal depression detection using the DAIC-WOZ dataset. We extract the audio features using the pre-trained model Wav2Vec, and mapped it to text-based LLMs for further processing. We also propose a novel strategy for incorporating psychological knowledge into LLMs to enhance diagnostic performance, specifically using a question and answer set to grant authorised knowledge to LLMs. Our approach yields a notable improvement in both Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) compared to a base score proposed by the related original paper. The codes are available at https://github.com/myxp-lyp/Depression-detection.git
Neuroplasticity in Artificial Intelligence -- An Overview and Inspirations on Drop In \& Out Learning
Mar 27, 2025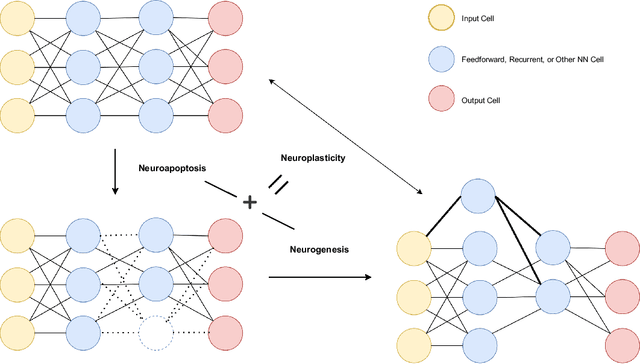
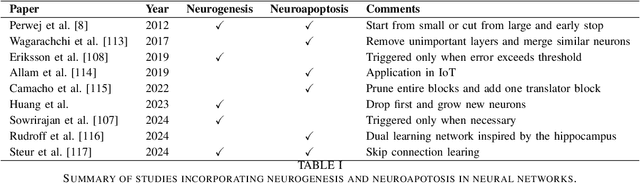
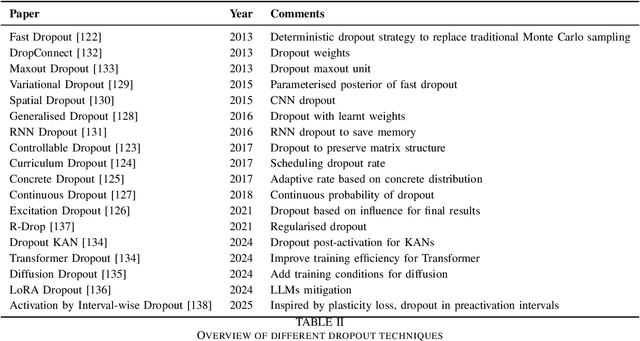
Artificial Intelligence (AI) has achieved new levels of performance and spread in public usage with the rise of deep neural networks (DNNs). Initially inspired by human neurons and their connections, NNs have become the foundation of AI models for many advanced architectures. However, some of the most integral processes in the human brain, particularly neurogenesis and neuroplasticity in addition to the more spread neuroapoptosis have largely been ignored in DNN architecture design. Instead, contemporary AI development predominantly focuses on constructing advanced frameworks, such as large language models, which retain a static structure of neural connections during training and inference. In this light, we explore how neurogenesis, neuroapoptosis, and neuroplasticity can inspire future AI advances. Specifically, we examine analogous activities in artificial NNs, introducing the concepts of ``dropin'' for neurogenesis and revisiting ``dropout'' and structural pruning for neuroapoptosis. We additionally suggest neuroplasticity combining the two for future large NNs in ``life-long learning'' settings following the biological inspiration. We conclude by advocating for greater research efforts in this interdisciplinary domain and identifying promising directions for future exploration.
Detecting Document-level Paraphrased Machine Generated Content: Mimicking Human Writing Style and Involving Discourse Features
Dec 17, 2024



The availability of high-quality APIs for Large Language Models (LLMs) has facilitated the widespread creation of Machine-Generated Content (MGC), posing challenges such as academic plagiarism and the spread of misinformation. Existing MGC detectors often focus solely on surface-level information, overlooking implicit and structural features. This makes them susceptible to deception by surface-level sentence patterns, particularly for longer texts and in texts that have been subsequently paraphrased. To overcome these challenges, we introduce novel methodologies and datasets. Besides the publicly available dataset Plagbench, we developed the paraphrased Long-Form Question and Answer (paraLFQA) and paraphrased Writing Prompts (paraWP) datasets using GPT and DIPPER, a discourse paraphrasing tool, by extending artifacts from their original versions. To address the challenge of detecting highly similar paraphrased texts, we propose MhBART, an encoder-decoder model designed to emulate human writing style while incorporating a novel difference score mechanism. This model outperforms strong classifier baselines and identifies deceptive sentence patterns. To better capture the structure of longer texts at document level, we propose DTransformer, a model that integrates discourse analysis through PDTB preprocessing to encode structural features. It results in substantial performance gains across both datasets -- 15.5\% absolute improvement on paraLFQA, 4\% absolute improvement on paraWP, and 1.5\% absolute improvement on M4 compared to SOTA approaches.
autrainer: A Modular and Extensible Deep Learning Toolkit for Computer Audition Tasks
Dec 16, 2024
This work introduces the key operating principles for autrainer, our new deep learning training framework for computer audition tasks. autrainer is a PyTorch-based toolkit that allows for rapid, reproducible, and easily extensible training on a variety of different computer audition tasks. Concretely, autrainer offers low-code training and supports a wide range of neural networks as well as preprocessing routines. In this work, we present an overview of its inner workings and key capabilities.
From Audio Deepfake Detection to AI-Generated Music Detection -- A Pathway and Overview
Nov 30, 2024
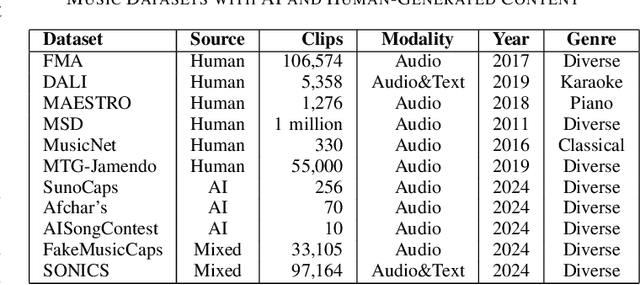
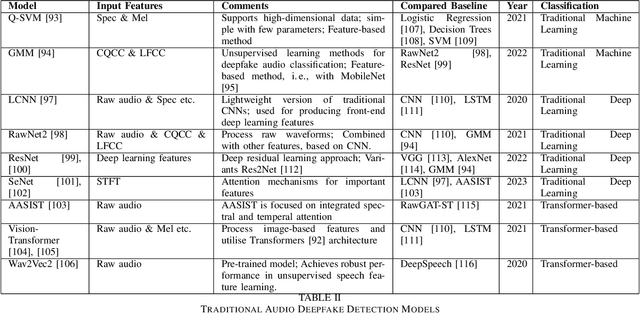
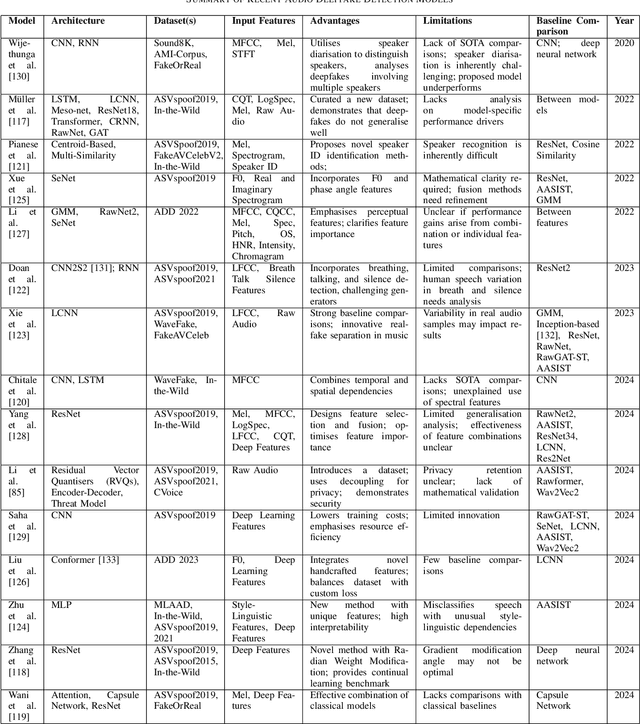
As Artificial Intelligence (AI) technologies continue to evolve, their use in generating realistic, contextually appropriate content has expanded into various domains. Music, an art form and medium for entertainment, deeply rooted into human culture, is seeing an increased involvement of AI into its production. However, the unregulated use of AI music generation (AIGM) tools raises concerns about potential negative impacts on the music industry, copyright and artistic integrity, underscoring the importance of effective AIGM detection. This paper provides an overview of existing AIGM detection methods. To lay a foundation to the general workings and challenges of AIGM detection, we first review general principles of AIGM, including recent advancements in deepfake audios, as well as multimodal detection techniques. We further propose a potential pathway for leveraging foundation models from audio deepfake detection to AIGM detection. Additionally, we discuss implications of these tools and propose directions for future research to address ongoing challenges in the field.
Does the Definition of Difficulty Matter? Scoring Functions and their Role for Curriculum Learning
Nov 01, 2024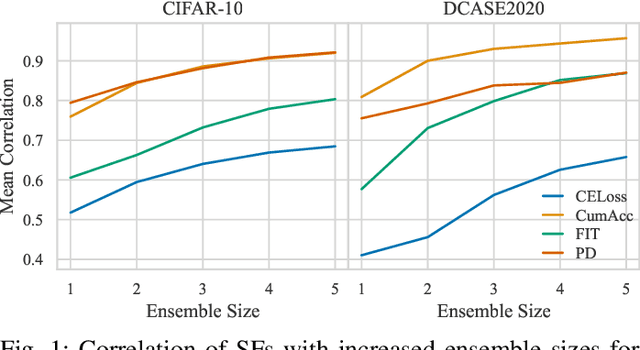
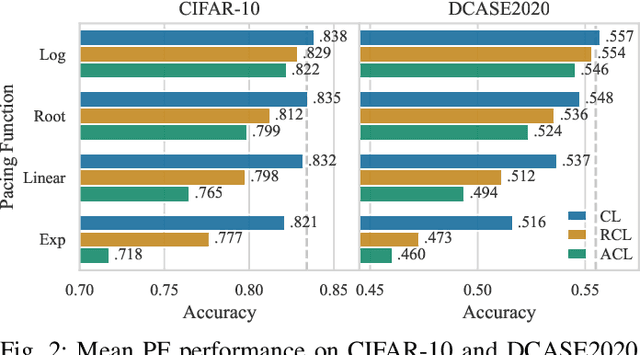
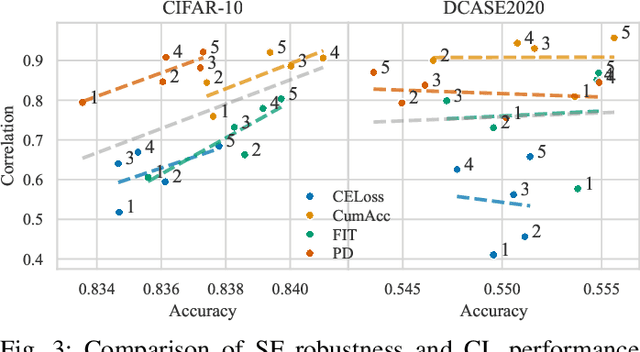
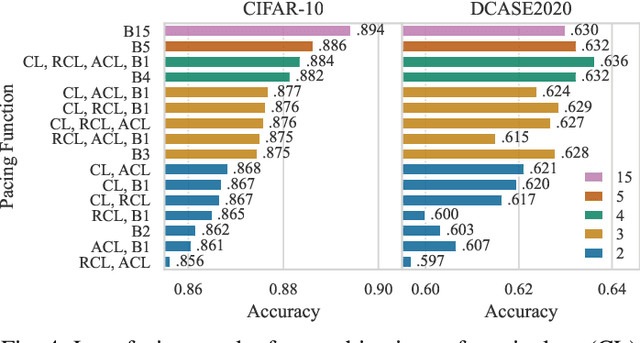
Curriculum learning (CL) describes a machine learning training strategy in which samples are gradually introduced into the training process based on their difficulty. Despite a partially contradictory body of evidence in the literature, CL finds popularity in deep learning research due to its promise of leveraging human-inspired curricula to achieve higher model performance. Yet, the subjectivity and biases that follow any necessary definition of difficulty, especially for those found in orderings derived from models or training statistics, have rarely been investigated. To shed more light on the underlying unanswered questions, we conduct an extensive study on the robustness and similarity of the most common scoring functions for sample difficulty estimation, as well as their potential benefits in CL, using the popular benchmark dataset CIFAR-10 and the acoustic scene classification task from the DCASE2020 challenge as representatives of computer vision and computer audition, respectively. We report a strong dependence of scoring functions on the training setting, including randomness, which can partly be mitigated through ensemble scoring. While we do not find a general advantage of CL over uniform sampling, we observe that the ordering in which data is presented for CL-based training plays an important role in model performance. Furthermore, we find that the robustness of scoring functions across random seeds positively correlates with CL performance. Finally, we uncover that models trained with different CL strategies complement each other by boosting predictive power through late fusion, likely due to differences in the learnt concepts. Alongside our findings, we release the aucurriculum toolkit (https://github.com/autrainer/aucurriculum), implementing sample difficulty and CL-based training in a modular fashion.
Audio-based Kinship Verification Using Age Domain Conversion
Oct 14, 2024


Audio-based kinship verification (AKV) is important in many domains, such as home security monitoring, forensic identification, and social network analysis. A key challenge in the task arises from differences in age across samples from different individuals, which can be interpreted as a domain bias in a cross-domain verification task. To address this issue, we design the notion of an "age-standardised domain" wherein we utilise the optimised CycleGAN-VC3 network to perform age-audio conversion to generate the in-domain audio. The generated audio dataset is employed to extract a range of features, which are then fed into a metric learning architecture to verify kinship. Experiments are conducted on the KAN_AV audio dataset, which contains age and kinship labels. The results demonstrate that the method markedly enhances the accuracy of kinship verification, while also offering novel insights for future kinship verification research.
Audio Enhancement for Computer Audition -- An Iterative Training Paradigm Using Sample Importance
Aug 12, 2024Neural network models for audio tasks, such as automatic speech recognition (ASR) and acoustic scene classification (ASC), are susceptible to noise contamination for real-life applications. To improve audio quality, an enhancement module, which can be developed independently, is explicitly used at the front-end of the target audio applications. In this paper, we present an end-to-end learning solution to jointly optimise the models for audio enhancement (AE) and the subsequent applications. To guide the optimisation of the AE module towards a target application, and especially to overcome difficult samples, we make use of the sample-wise performance measure as an indication of sample importance. In experiments, we consider four representative applications to evaluate our training paradigm, i.e., ASR, speech command recognition (SCR), speech emotion recognition (SER), and ASC. These applications are associated with speech and non-speech tasks concerning semantic and non-semantic features, transient and global information, and the experimental results indicate that our proposed approach can considerably boost the noise robustness of the models, especially at low signal-to-noise ratios (SNRs), for a wide range of computer audition tasks in everyday-life noisy environments.