 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Efficiency and Performance in Deepfake Audio Detection through Neuron-level dropin & Neuroplasticity Mechanisms
Mar 25, 2026Current audio deepfake detection has achieved remarkable performance using diverse deep learning architectures such as ResNet, and has seen further improvements with the introduction of large models (LMs) like Wav2Vec. The success of large language models (LLMs) further demonstrates the benefits of scaling model parameters, but also highlights one bottleneck where performance gains are constrained by parameter counts. Simply stacking additional layers, as done in current LLMs, is computationally expensive and requires full retraining. Furthermore, existing low-rank adaptation methods are primarily applied to attention-based architectures, which limits their scope. Inspired by the neuronal plasticity observed in mammalian brains, we propose novel algorithms, dropin and further plasticity, that dynamically adjust the number of neurons in certain layers to flexibly modulate model parameters. We evaluate these algorithms on multiple architectures, including ResNet, Gated Recurrent Neural Networks, and Wav2Vec. Experimental results using the widely recognised ASVSpoof2019 LA, PA, and FakeorReal dataset demonstrate consistent improvements in computational efficiency with the dropin approach and a maximum of around 39% and 66% relative reduction in Equal Error Rate with the dropin and plasticity approach among these dataset, respectively. The code and supplementary material are available at Github link.
Affect and Effect: Limitations of regularisation-based continual learning in EEG-based emotion classification
Jan 09, 2026Generalisation to unseen subjects in EEG-based emotion classification remains a challenge due to high inter-and intra-subject variability. Continual learning (CL) poses a promising solution by learning from a sequence of tasks while mitigating catastrophic forgetting. Regularisation-based CL approaches, such as Elastic Weight Consolidation (EWC), Synaptic Intelligence (SI), and Memory Aware Synapses (MAS), are commonly used as baselines in EEG-based CL studies, yet their suitability for this problem remains underexplored. This study theoretically and empirically finds that regularisation-based CL methods show limited performance for EEG-based emotion classification on the DREAMER and SEED datasets. We identify a fundamental misalignment in the stability-plasticity trade-off, where regularisation-based methods prioritise mitigating catastrophic forgetting (backward transfer) over adapting to new subjects (forward transfer). We investigate this limitation under subject-incremental sequences and observe that: (1) the heuristics for estimating parameter importance become less reliable under noisy data and covariate shift, (2) gradients on parameters deemed important by these heuristics often interfere with gradient updates required for new subjects, moving optimisation away from the minimum, (3) importance values accumulated across tasks over-constrain the model, and (4) performance is sensitive to subject order. Forward transfer showed no statistically significant improvement over sequential fine-tuning (p > 0.05 across approaches and datasets). The high variability of EEG signals means past subjects provide limited value to future subjects. Regularisation-based continual learning approaches are therefore limited for robust generalisation to unseen subjects in EEG-based emotion classification.
Large Language Models for Depression Recognition in Spoken Language Integrating Psychological Knowledge
May 28, 2025Depression is a growing concern gaining attention in both public discourse and AI research. While deep neural networks (DNNs) have been used for recognition, they still lack real-world effectiveness. Large language models (LLMs) show strong potential but require domain-specific fine-tuning and struggle with non-textual cues. Since depression is often expressed through vocal tone and behaviour rather than explicit text, relying on language alone is insufficient. Diagnostic accuracy also suffers without incorporating psychological expertise. To address these limitations, we present, to the best of our knowledge, the first application of LLMs to multimodal depression detection using the DAIC-WOZ dataset. We extract the audio features using the pre-trained model Wav2Vec, and mapped it to text-based LLMs for further processing. We also propose a novel strategy for incorporating psychological knowledge into LLMs to enhance diagnostic performance, specifically using a question and answer set to grant authorised knowledge to LLMs. Our approach yields a notable improvement in both Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) compared to a base score proposed by the related original paper. The codes are available at https://github.com/myxp-lyp/Depression-detection.git
Neuroplasticity in Artificial Intelligence -- An Overview and Inspirations on Drop In \& Out Learning
Mar 27, 2025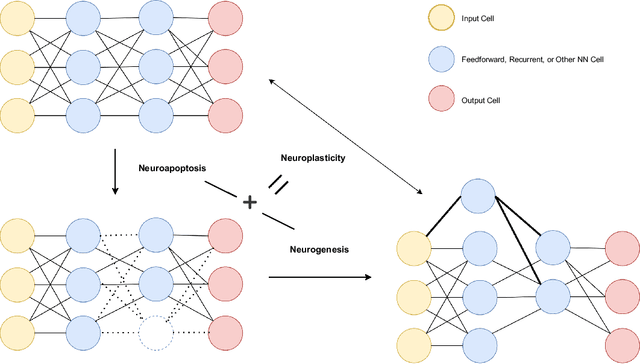
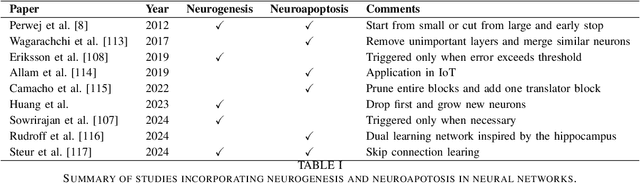
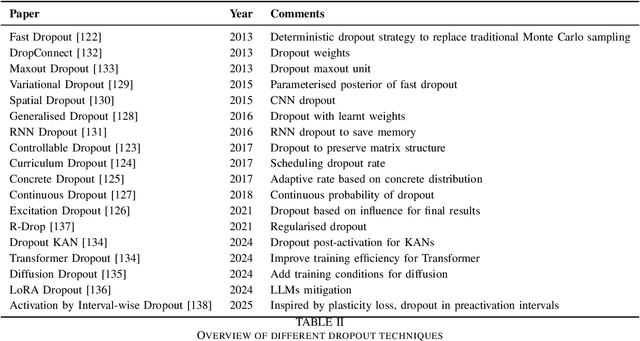
Artificial Intelligence (AI) has achieved new levels of performance and spread in public usage with the rise of deep neural networks (DNNs). Initially inspired by human neurons and their connections, NNs have become the foundation of AI models for many advanced architectures. However, some of the most integral processes in the human brain, particularly neurogenesis and neuroplasticity in addition to the more spread neuroapoptosis have largely been ignored in DNN architecture design. Instead, contemporary AI development predominantly focuses on constructing advanced frameworks, such as large language models, which retain a static structure of neural connections during training and inference. In this light, we explore how neurogenesis, neuroapoptosis, and neuroplasticity can inspire future AI advances. Specifically, we examine analogous activities in artificial NNs, introducing the concepts of ``dropin'' for neurogenesis and revisiting ``dropout'' and structural pruning for neuroapoptosis. We additionally suggest neuroplasticity combining the two for future large NNs in ``life-long learning'' settings following the biological inspiration. We conclude by advocating for greater research efforts in this interdisciplinary domain and identifying promising directions for future exploration.
GatedxLSTM: A Multimodal Affective Computing Approach for Emotion Recognition in Conversations
Mar 26, 2025Affective Computing (AC) is essential for advancing Artificial General Intelligence (AGI), with emotion recognition serving as a key component. However, human emotions are inherently dynamic, influenced not only by an individual's expressions but also by interactions with others, and single-modality approaches often fail to capture their full dynamics. Multimodal Emotion Recognition (MER) leverages multiple signals but traditionally relies on utterance-level analysis, overlooking the dynamic nature of emotions in conversations. Emotion Recognition in Conversation (ERC) addresses this limitation, yet existing methods struggle to align multimodal features and explain why emotions evolve within dialogues. To bridge this gap, we propose GatedxLSTM, a novel speech-text multimodal ERC model that explicitly considers voice and transcripts of both the speaker and their conversational partner(s) to identify the most influential sentences driving emotional shifts. By integrating Contrastive Language-Audio Pretraining (CLAP) for improved cross-modal alignment and employing a gating mechanism to emphasise emotionally impactful utterances, GatedxLSTM enhances both interpretability and performance. Additionally, the Dialogical Emotion Decoder (DED) refines emotion predictions by modelling contextual dependencies. Experiments on the IEMOCAP dataset demonstrate that GatedxLSTM achieves state-of-the-art (SOTA) performance among open-source methods in four-class emotion classification. These results validate its effectiveness for ERC applications and provide an interpretability analysis from a psychological perspective.
DOTA-ME-CS: Daily Oriented Text Audio-Mandarin English-Code Switching Dataset
Jan 21, 2025



Code-switching, the alternation between two or more languages within communication, poses great challenges for Automatic Speech Recognition (ASR) systems. Existing models and datasets are limited in their ability to effectively handle these challenges. To address this gap and foster progress in code-switching ASR research, we introduce the DOTA-ME-CS: Daily oriented text audio Mandarin-English code-switching dataset, which consists of 18.54 hours of audio data, including 9,300 recordings from 34 participants. To enhance the dataset's diversity, we apply artificial intelligence (AI) techniques such as AI timbre synthesis, speed variation, and noise addition, thereby increasing the complexity and scalability of the task. The dataset is carefully curated to ensure both diversity and quality, providing a robust resource for researchers addressing the intricacies of bilingual speech recognition with detailed data analysis. We further demonstrate the dataset's potential in future research. The DOTA-ME-CS dataset, along with accompanying code, will be made publicly available.
Towards Friendly AI: A Comprehensive Review and New Perspectives on Human-AI Alignment
Dec 19, 2024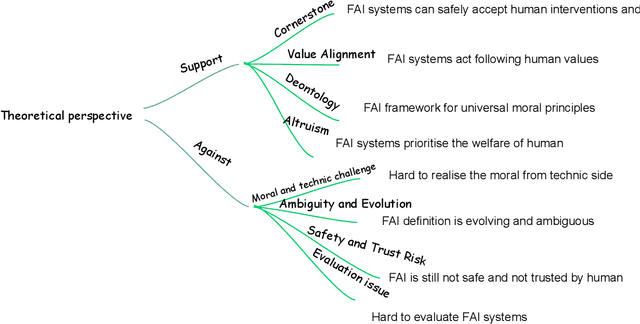
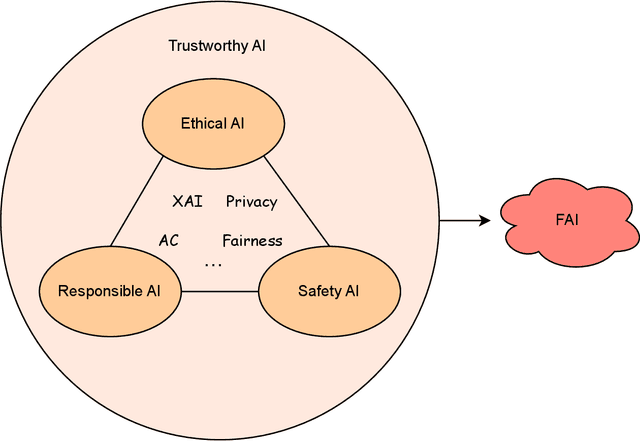
As Artificial Intelligence (AI) continues to advance rapidly, Friendly AI (FAI) has been proposed to advocate for more equitable and fair development of AI. Despite its importance, there is a lack of comprehensive reviews examining FAI from an ethical perspective, as well as limited discussion on its potential applications and future directions. This paper addresses these gaps by providing a thorough review of FAI, focusing on theoretical perspectives both for and against its development, and presenting a formal definition in a clear and accessible format. Key applications are discussed from the perspectives of eXplainable AI (XAI), privacy, fairness and affective computing (AC). Additionally, the paper identifies challenges in current technological advancements and explores future research avenues. The findings emphasise the significance of developing FAI and advocate for its continued advancement to ensure ethical and beneficial AI development.
Detecting Machine-Generated Music with Explainability -- A Challenge and Early Benchmarks
Dec 18, 2024

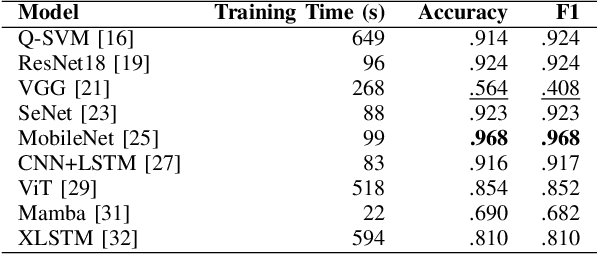
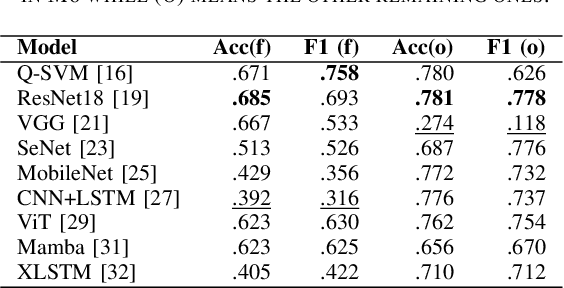
Machine-generated music (MGM) has become a groundbreaking innovation with wide-ranging applications, such as music therapy, personalised editing, and creative inspiration within the music industry. However, the unregulated proliferation of MGM presents considerable challenges to the entertainment, education, and arts sectors by potentially undermining the value of high-quality human compositions. Consequently, MGM detection (MGMD) is crucial for preserving the integrity of these fields. Despite its significance, MGMD domain lacks comprehensive benchmark results necessary to drive meaningful progress. To address this gap, we conduct experiments on existing large-scale datasets using a range of foundational models for audio processing, establishing benchmark results tailored to the MGMD task. Our selection includes traditional machine learning models, deep neural networks, Transformer-based architectures, and State Space Models (SSM). Recognising the inherently multimodal nature of music, which integrates both melody and lyrics, we also explore fundamental multimodal models in our experiments. Beyond providing basic binary classification outcomes, we delve deeper into model behaviour using multiple explainable Aritificial Intelligence (XAI) tools, offering insights into their decision-making processes. Our analysis reveals that ResNet18 performs the best according to in-domain and out-of-domain tests. By providing a comprehensive comparison of benchmark results and their interpretability, we propose several directions to inspire future research to develop more robust and effective detection methods for MGM.
Detecting Document-level Paraphrased Machine Generated Content: Mimicking Human Writing Style and Involving Discourse Features
Dec 17, 2024



The availability of high-quality APIs for Large Language Models (LLMs) has facilitated the widespread creation of Machine-Generated Content (MGC), posing challenges such as academic plagiarism and the spread of misinformation. Existing MGC detectors often focus solely on surface-level information, overlooking implicit and structural features. This makes them susceptible to deception by surface-level sentence patterns, particularly for longer texts and in texts that have been subsequently paraphrased. To overcome these challenges, we introduce novel methodologies and datasets. Besides the publicly available dataset Plagbench, we developed the paraphrased Long-Form Question and Answer (paraLFQA) and paraphrased Writing Prompts (paraWP) datasets using GPT and DIPPER, a discourse paraphrasing tool, by extending artifacts from their original versions. To address the challenge of detecting highly similar paraphrased texts, we propose MhBART, an encoder-decoder model designed to emulate human writing style while incorporating a novel difference score mechanism. This model outperforms strong classifier baselines and identifies deceptive sentence patterns. To better capture the structure of longer texts at document level, we propose DTransformer, a model that integrates discourse analysis through PDTB preprocessing to encode structural features. It results in substantial performance gains across both datasets -- 15.5\% absolute improvement on paraLFQA, 4\% absolute improvement on paraWP, and 1.5\% absolute improvement on M4 compared to SOTA approaches.
M6: Multi-generator, Multi-domain, Multi-lingual and cultural, Multi-genres, Multi-instrument Machine-Generated Music Detection Databases
Dec 08, 2024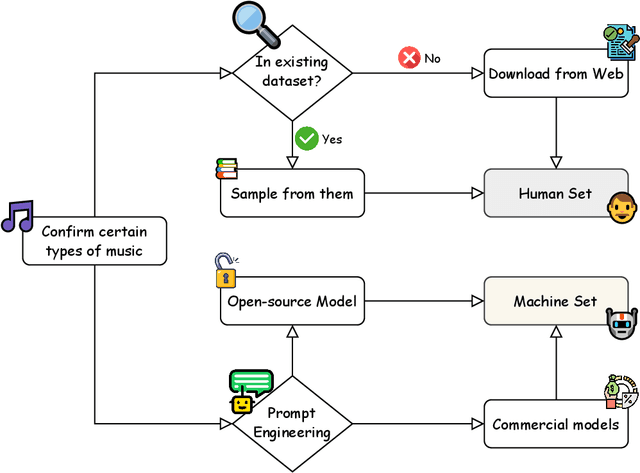


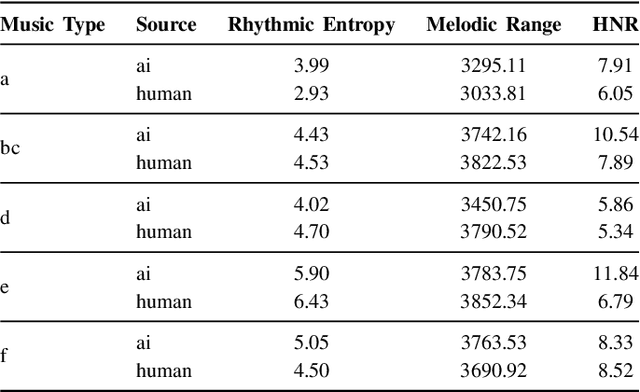
Machine-generated music (MGM) has emerged as a powerful tool with applications in music therapy, personalised editing, and creative inspiration for the music community. However, its unregulated use threatens the entertainment, education, and arts sectors by diminishing the value of high-quality human compositions. Detecting machine-generated music (MGMD) is, therefore, critical to safeguarding these domains, yet the field lacks comprehensive datasets to support meaningful progress. To address this gap, we introduce \textbf{M6}, a large-scale benchmark dataset tailored for MGMD research. M6 is distinguished by its diversity, encompassing multiple generators, domains, languages, cultural contexts, genres, and instruments. We outline our methodology for data selection and collection, accompanied by detailed data analysis, providing all WAV form of music. Additionally, we provide baseline performance scores using foundational binary classification models, illustrating the complexity of MGMD and the significant room for improvement. By offering a robust and multifaceted resource, we aim to empower future research to develop more effective detection methods for MGM. We believe M6 will serve as a critical step toward addressing this societal challenge. The dataset and code will be freely available to support open collaboration and innovation in this field.