 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Dialect Bird Species Recognition with Dialect-Calibrated Augmentation
Sep 26, 2025Dialect variation hampers automatic recognition of bird calls collected by passive acoustic monitoring. We address the problem on DB3V, a three-region, ten-species corpus of 8-s clips, and propose a deployable framework built on Time-Delay Neural Networks (TDNNs). Frequency-sensitive normalisation (Instance Frequency Normalisation and a gated Relaxed-IFN) is paired with gradient-reversal adversarial training to learn region-invariant embeddings. A multi-level augmentation scheme combines waveform perturbations, Mixup for rare classes, and CycleGAN transfer that synthesises Region 2 (Interior Plains)-style audio, , with Dialect-Calibrated Augmentation (DCA) softly down-weighting synthetic samples to limit artifacts. The complete system lifts cross-dialect accuracy by up to twenty percentage points over baseline TDNNs while preserving in-region performance. Grad-CAM and LIME analyses show that robust models concentrate on stable harmonic bands, providing ecologically meaningful explanations. The study demonstrates that lightweight, transparent, and dialect-resilient bird-sound recognition is attainable.
GatedxLSTM: A Multimodal Affective Computing Approach for Emotion Recognition in Conversations
Mar 26, 2025Affective Computing (AC) is essential for advancing Artificial General Intelligence (AGI), with emotion recognition serving as a key component. However, human emotions are inherently dynamic, influenced not only by an individual's expressions but also by interactions with others, and single-modality approaches often fail to capture their full dynamics. Multimodal Emotion Recognition (MER) leverages multiple signals but traditionally relies on utterance-level analysis, overlooking the dynamic nature of emotions in conversations. Emotion Recognition in Conversation (ERC) addresses this limitation, yet existing methods struggle to align multimodal features and explain why emotions evolve within dialogues. To bridge this gap, we propose GatedxLSTM, a novel speech-text multimodal ERC model that explicitly considers voice and transcripts of both the speaker and their conversational partner(s) to identify the most influential sentences driving emotional shifts. By integrating Contrastive Language-Audio Pretraining (CLAP) for improved cross-modal alignment and employing a gating mechanism to emphasise emotionally impactful utterances, GatedxLSTM enhances both interpretability and performance. Additionally, the Dialogical Emotion Decoder (DED) refines emotion predictions by modelling contextual dependencies. Experiments on the IEMOCAP dataset demonstrate that GatedxLSTM achieves state-of-the-art (SOTA) performance among open-source methods in four-class emotion classification. These results validate its effectiveness for ERC applications and provide an interpretability analysis from a psychological perspective.
Towards Friendly AI: A Comprehensive Review and New Perspectives on Human-AI Alignment
Dec 19, 2024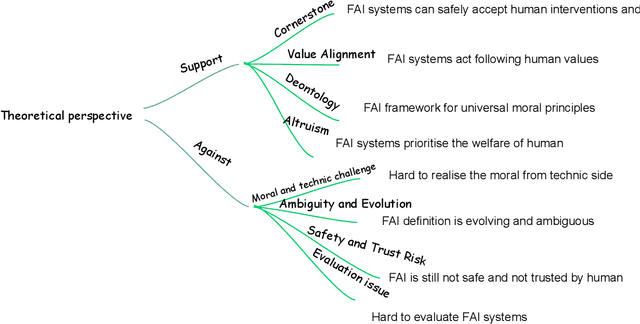
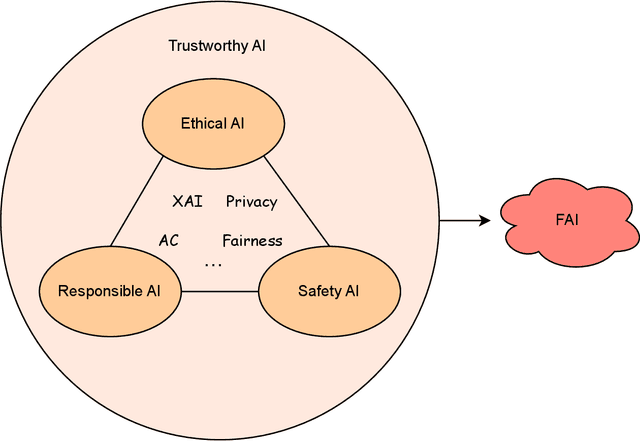
As Artificial Intelligence (AI) continues to advance rapidly, Friendly AI (FAI) has been proposed to advocate for more equitable and fair development of AI. Despite its importance, there is a lack of comprehensive reviews examining FAI from an ethical perspective, as well as limited discussion on its potential applications and future directions. This paper addresses these gaps by providing a thorough review of FAI, focusing on theoretical perspectives both for and against its development, and presenting a formal definition in a clear and accessible format. Key applications are discussed from the perspectives of eXplainable AI (XAI), privacy, fairness and affective computing (AC). Additionally, the paper identifies challenges in current technological advancements and explores future research avenues. The findings emphasise the significance of developing FAI and advocate for its continued advancement to ensure ethical and beneficial AI development.
Detecting Machine-Generated Music with Explainability -- A Challenge and Early Benchmarks
Dec 18, 2024

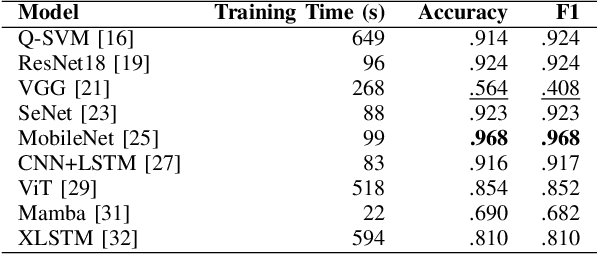
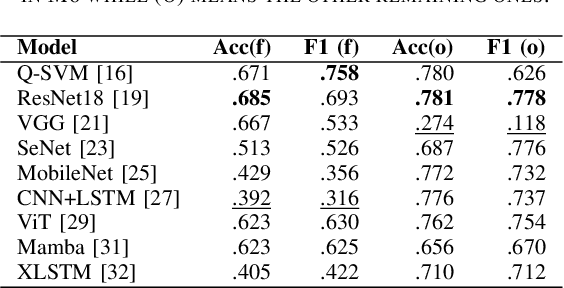
Machine-generated music (MGM) has become a groundbreaking innovation with wide-ranging applications, such as music therapy, personalised editing, and creative inspiration within the music industry. However, the unregulated proliferation of MGM presents considerable challenges to the entertainment, education, and arts sectors by potentially undermining the value of high-quality human compositions. Consequently, MGM detection (MGMD) is crucial for preserving the integrity of these fields. Despite its significance, MGMD domain lacks comprehensive benchmark results necessary to drive meaningful progress. To address this gap, we conduct experiments on existing large-scale datasets using a range of foundational models for audio processing, establishing benchmark results tailored to the MGMD task. Our selection includes traditional machine learning models, deep neural networks, Transformer-based architectures, and State Space Models (SSM). Recognising the inherently multimodal nature of music, which integrates both melody and lyrics, we also explore fundamental multimodal models in our experiments. Beyond providing basic binary classification outcomes, we delve deeper into model behaviour using multiple explainable Aritificial Intelligence (XAI) tools, offering insights into their decision-making processes. Our analysis reveals that ResNet18 performs the best according to in-domain and out-of-domain tests. By providing a comprehensive comparison of benchmark results and their interpretability, we propose several directions to inspire future research to develop more robust and effective detection methods for MGM.
Audio-based Kinship Verification Using Age Domain Conversion
Oct 14, 2024


Audio-based kinship verification (AKV) is important in many domains, such as home security monitoring, forensic identification, and social network analysis. A key challenge in the task arises from differences in age across samples from different individuals, which can be interpreted as a domain bias in a cross-domain verification task. To address this issue, we design the notion of an "age-standardised domain" wherein we utilise the optimised CycleGAN-VC3 network to perform age-audio conversion to generate the in-domain audio. The generated audio dataset is employed to extract a range of features, which are then fed into a metric learning architecture to verify kinship. Experiments are conducted on the KAN_AV audio dataset, which contains age and kinship labels. The results demonstrate that the method markedly enhances the accuracy of kinship verification, while also offering novel insights for future kinship verification research.
Audio Explanation Synthesis with Generative Foundation Models
Oct 10, 2024



The increasing success of audio foundation models across various tasks has led to a growing need for improved interpretability to understand their intricate decision-making processes better. Existing methods primarily focus on explaining these models by attributing importance to elements within the input space based on their influence on the final decision. In this paper, we introduce a novel audio explanation method that capitalises on the generative capacity of audio foundation models. Our method leverages the intrinsic representational power of the embedding space within these models by integrating established feature attribution techniques to identify significant features in this space. The method then generates listenable audio explanations by prioritising the most important features. Through rigorous benchmarking against standard datasets, including keyword spotting and speech emotion recognition, our model demonstrates its efficacy in producing audio explanations.