 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrading through Earnings Seasons using Self-Supervised Contrastive Representation Learning
Sep 25, 2024



Earnings release is a key economic event in the financial markets and crucial for predicting stock movements. Earnings data gives a glimpse into how a company is doing financially and can hint at where its stock might go next. However, the irregularity of its release cycle makes it a challenge to incorporate this data in a medium-frequency algorithmic trading model and the usefulness of this data fades fast after it is released, making it tough for models to stay accurate over time. Addressing this challenge, we introduce the Contrastive Earnings Transformer (CET) model, a self-supervised learning approach rooted in Contrastive Predictive Coding (CPC), aiming to optimise the utilisation of earnings data. To ascertain its effectiveness, we conduct a comparative study of CET against benchmark models across diverse sectors. Our research delves deep into the intricacies of stock data, evaluating how various models, and notably CET, handle the rapidly changing relevance of earnings data over time and over different sectors. The research outcomes shed light on CET's distinct advantage in extrapolating the inherent value of earnings data over time. Its foundation on CPC allows for a nuanced understanding, facilitating consistent stock predictions even as the earnings data ages. This finding about CET presents a fresh approach to better use earnings data in algorithmic trading for predicting stock price trends.
DB3V: A Dialect Dominated Dataset of Bird Vocalisation for Cross-corpus Bird Species Recognition
Jun 11, 2024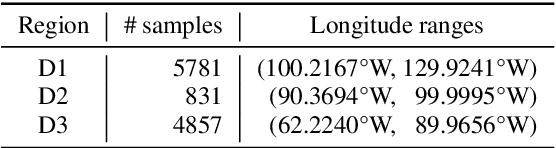
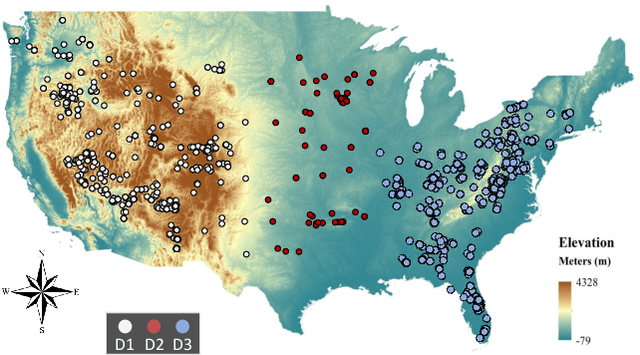
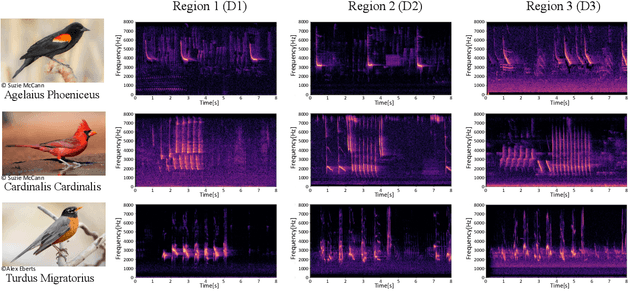
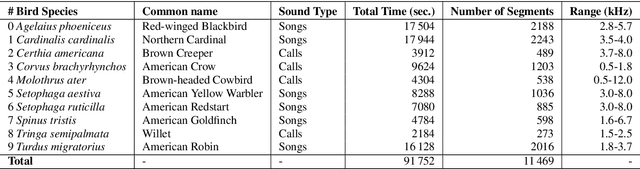
In ornithology, bird species are known to have variedit's widely acknowledged that bird species display diverse dialects in their calls across different regions. Consequently, computational methods to identify bird species onsolely through their calls face critsignificalnt challenges. There is growing interest in understanding the impact of species-specific dialects on the effectiveness of bird species recognition methods. Despite potential mitigation through the expansion of dialect datasets, the absence of publicly available testing data currently impedes robust benchmarking efforts. This paper presents the Dialect Dominated Dataset of Bird Vocalisation, the first cross-corpus dataset that focuses on dialects in bird vocalisations. The DB3V comprises more than 25 hours of audio recordings from 10 bird species distributed across three distinct regions in the contiguous United States (CONUS). In addition to presenting the dataset, we conduct analyses and establish baseline models for cross-corpus bird recognition. The data and code are publicly available online: https://zenodo.org/records/11544734
Executive Voiced Laughter and Social Approval: An Explorative Machine Learning Study
May 20, 2023

We study voiced laughter in executive communication and its effect on social approval. Integrating research on laughter, affect-as-information, and infomediaries' social evaluations of firms, we hypothesize that voiced laughter in executive communication positively affects social approval, defined as audience perceptions of affinity towards an organization. We surmise that the effect of laughter is especially strong for joint laughter, i.e., the number of instances in a given communication venue for which the focal executive and the audience laugh simultaneously. Finally, combining the notions of affect-as-information and negativity bias in human cognition, we hypothesize that the positive effect of laughter on social approval increases with bad organizational performance. We find partial support for our ideas when testing them on panel data comprising 902 German Bundesliga soccer press conferences and media tenor, applying state-of-the-art machine learning approaches for laughter detection as well as sentiment analysis. Our findings contribute to research at the nexus of executive communication, strategic leadership, and social evaluations, especially by introducing laughter as a highly consequential potential, but understudied social lubricant at the executive-infomediary interface. Our research is unique by focusing on reflexive microprocesses of social evaluations, rather than the infomediary-routines perspectives in infomediaries' evaluations. We also make methodological contributions.
Attention-Augmented End-to-End Multi-Task Learning for Emotion Prediction from Speech
Mar 29, 2019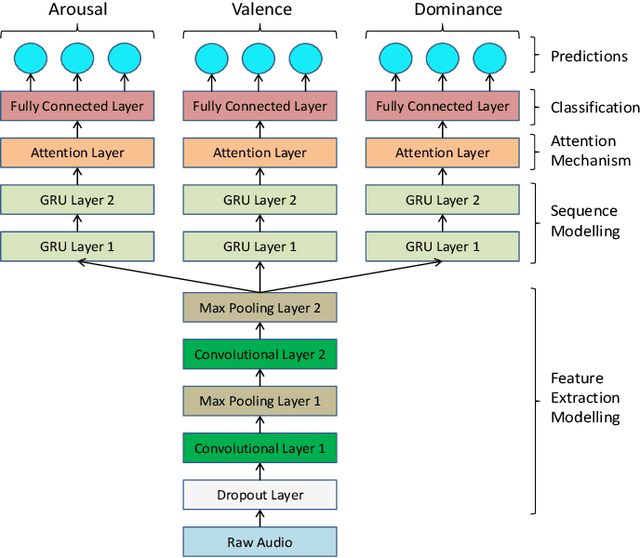
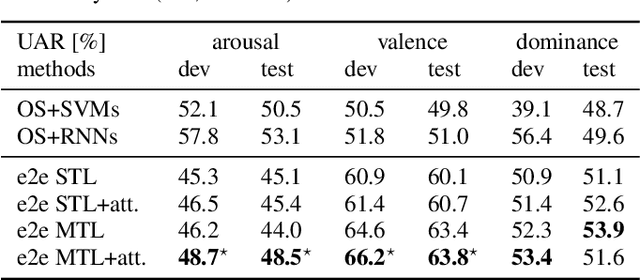
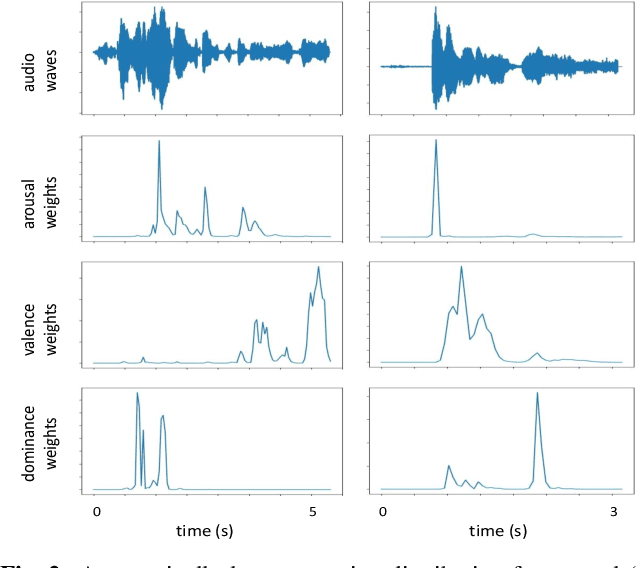
Despite the increasing research interest in end-to-end learning systems for speech emotion recognition, conventional systems either suffer from the overfitting due in part to the limited training data, or do not explicitly consider the different contributions of automatically learnt representations for a specific task. In this contribution, we propose a novel end-to-end framework which is enhanced by learning other auxiliary tasks and an attention mechanism. That is, we jointly train an end-to-end network with several different but related emotion prediction tasks, i.e., arousal, valence, and dominance predictions, to extract more robust representations shared among various tasks than traditional systems with the hope that it is able to relieve the overfitting problem. Meanwhile, an attention layer is implemented on top of the layers for each task, with the aim to capture the contribution distribution of different segment parts for each individual task. To evaluate the effectiveness of the proposed system, we conducted a set of experiments on the widely used database IEMOCAP. The empirical results show that the proposed systems significantly outperform corresponding baseline systems.
Snore-GANs: Improving Automatic Snore Sound Classification with Synthesized Data
Mar 29, 2019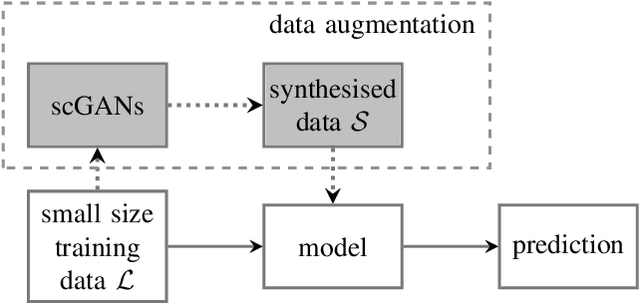
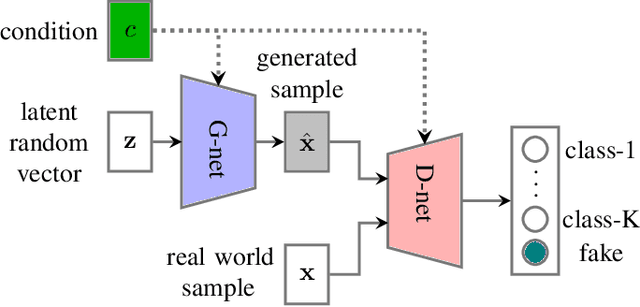
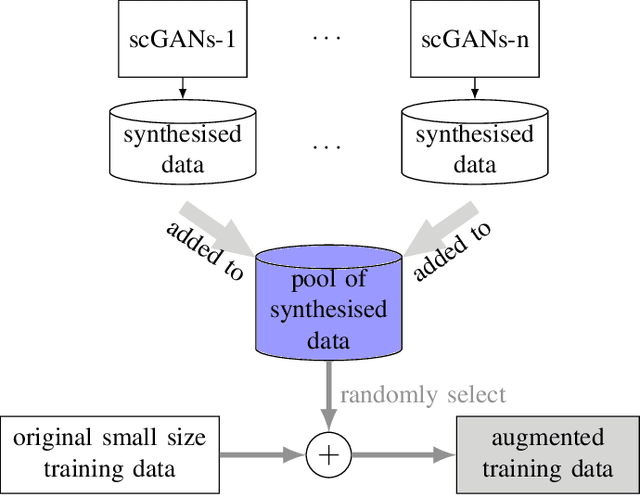
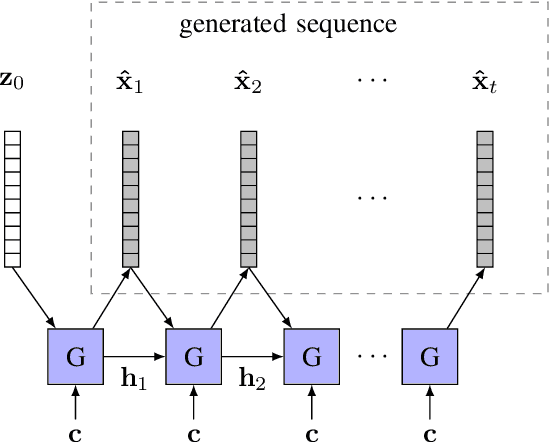
One of the frontier issues that severely hamper the development of automatic snore sound classification (ASSC) associates to the lack of sufficient supervised training data. To cope with this problem, we propose a novel data augmentation approach based on semi-supervised conditional Generative Adversarial Networks (scGANs), which aims to automatically learn a mapping strategy from a random noise space to original data distribution. The proposed approach has the capability of well synthesizing 'realistic' high-dimensional data, while requiring no additional annotation process. To handle the mode collapse problem of GANs, we further introduce an ensemble strategy to enhance the diversity of the generated data. The systematic experiments conducted on a widely used Munich-Passau snore sound corpus demonstrate that the scGANs-based systems can remarkably outperform other classic data augmentation systems, and are also competitive to other recently reported systems for ASSC.