 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Augmented End-to-End Multi-Task Learning for Emotion Prediction from Speech
Mar 29, 2019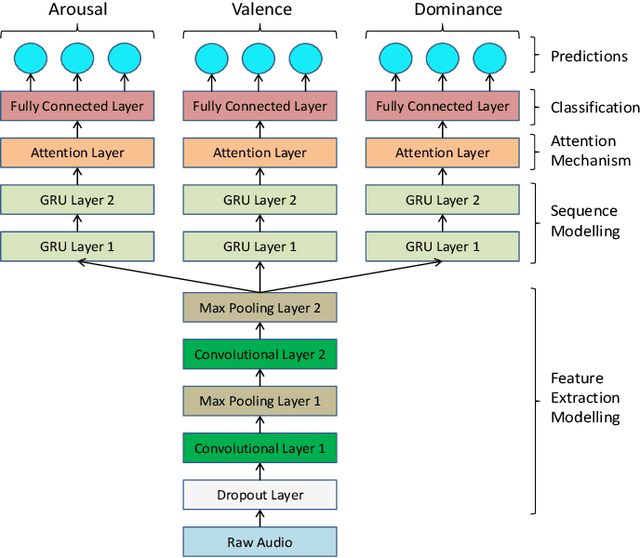
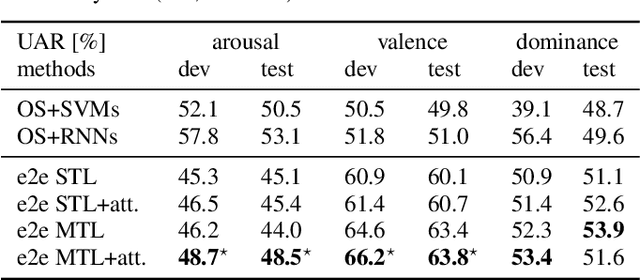
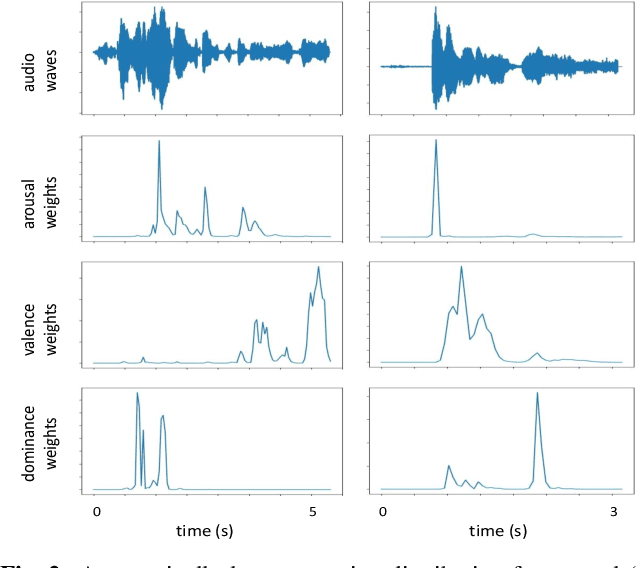
Despite the increasing research interest in end-to-end learning systems for speech emotion recognition, conventional systems either suffer from the overfitting due in part to the limited training data, or do not explicitly consider the different contributions of automatically learnt representations for a specific task. In this contribution, we propose a novel end-to-end framework which is enhanced by learning other auxiliary tasks and an attention mechanism. That is, we jointly train an end-to-end network with several different but related emotion prediction tasks, i.e., arousal, valence, and dominance predictions, to extract more robust representations shared among various tasks than traditional systems with the hope that it is able to relieve the overfitting problem. Meanwhile, an attention layer is implemented on top of the layers for each task, with the aim to capture the contribution distribution of different segment parts for each individual task. To evaluate the effectiveness of the proposed system, we conducted a set of experiments on the widely used database IEMOCAP. The empirical results show that the proposed systems significantly outperform corresponding baseline systems.