 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDB3V: A Dialect Dominated Dataset of Bird Vocalisation for Cross-corpus Bird Species Recognition
Jun 11, 2024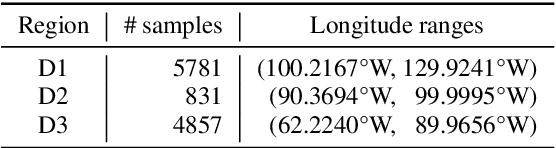
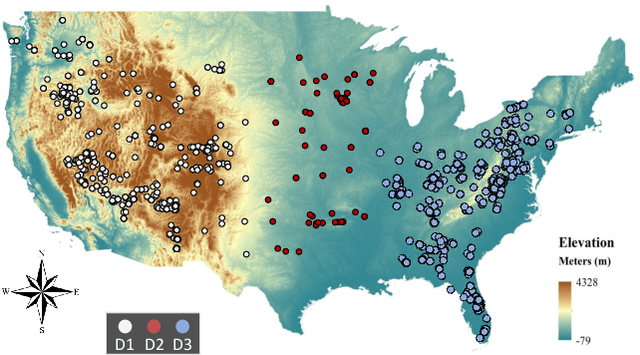
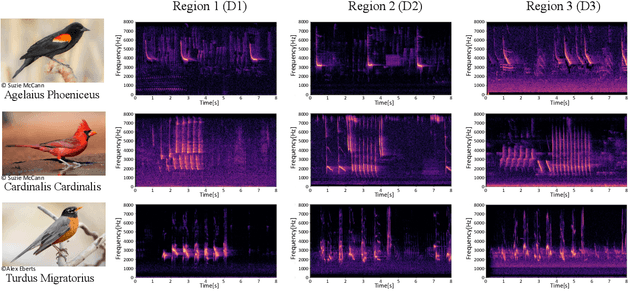
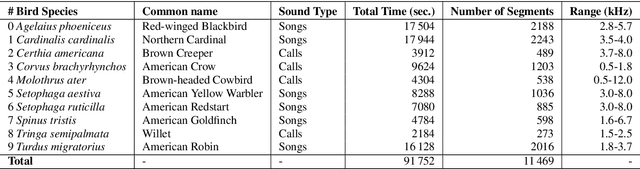
In ornithology, bird species are known to have variedit's widely acknowledged that bird species display diverse dialects in their calls across different regions. Consequently, computational methods to identify bird species onsolely through their calls face critsignificalnt challenges. There is growing interest in understanding the impact of species-specific dialects on the effectiveness of bird species recognition methods. Despite potential mitigation through the expansion of dialect datasets, the absence of publicly available testing data currently impedes robust benchmarking efforts. This paper presents the Dialect Dominated Dataset of Bird Vocalisation, the first cross-corpus dataset that focuses on dialects in bird vocalisations. The DB3V comprises more than 25 hours of audio recordings from 10 bird species distributed across three distinct regions in the contiguous United States (CONUS). In addition to presenting the dataset, we conduct analyses and establish baseline models for cross-corpus bird recognition. The data and code are publicly available online: https://zenodo.org/records/11544734
U-DiT TTS: U-Diffusion Vision Transformer for Text-to-Speech
May 22, 2023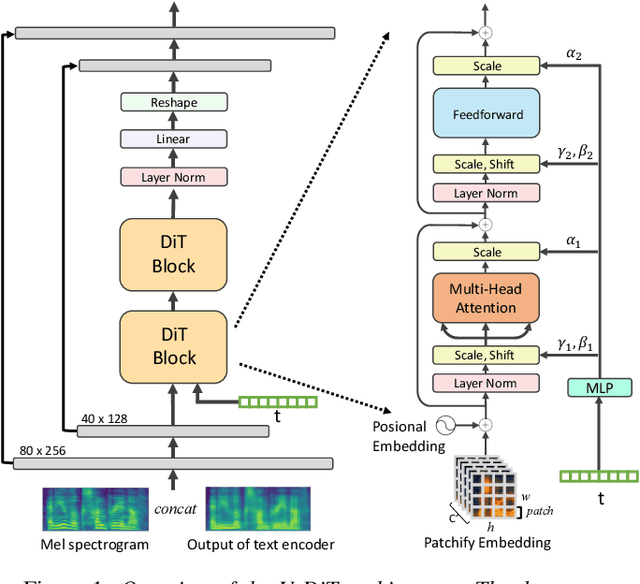

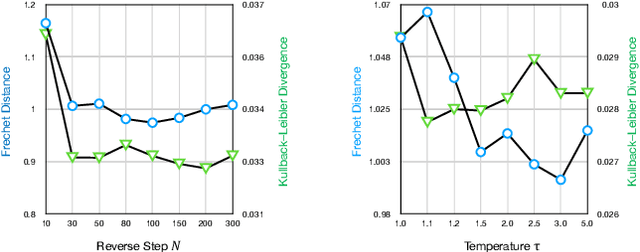
Deep learning has led to considerable advances in text-to-speech synthesis. Most recently, the adoption of Score-based Generative Models (SGMs), also known as Diffusion Probabilistic Models (DPMs), has gained traction due to their ability to produce high-quality synthesized neural speech in neural speech synthesis systems. In SGMs, the U-Net architecture and its variants have long dominated as the backbone since its first successful adoption. In this research, we mainly focus on the neural network in diffusion-model-based Text-to-Speech (TTS) systems and propose the U-DiT architecture, exploring the potential of vision transformer architecture as the core component of the diffusion models in a TTS system. The modular design of the U-DiT architecture, inherited from the best parts of U-Net and ViT, allows for great scalability and versatility across different data scales. The proposed U-DiT TTS system is a mel spectrogram-based acoustic model and utilizes a pretrained HiFi-GAN as the vocoder. The objective (ie Frechet distance) and MOS results show that our DiT-TTS system achieves state-of-art performance on the single speaker dataset LJSpeech. Our demos are publicly available at: https://eihw.github.io/u-dit-tts/