 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEAR4Health: A blueprint for making computer audition a staple of modern healthcare
Jan 25, 2023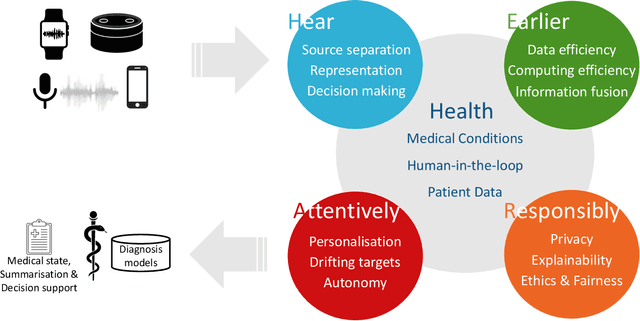

Recent years have seen a rapid increase in digital medicine research in an attempt to transform traditional healthcare systems to their modern, intelligent, and versatile equivalents that are adequately equipped to tackle contemporary challenges. This has led to a wave of applications that utilise AI technologies; first and foremost in the fields of medical imaging, but also in the use of wearables and other intelligent sensors. In comparison, computer audition can be seen to be lagging behind, at least in terms of commercial interest. Yet, audition has long been a staple assistant for medical practitioners, with the stethoscope being the quintessential sign of doctors around the world. Transforming this traditional technology with the use of AI entails a set of unique challenges. We categorise the advances needed in four key pillars: Hear, corresponding to the cornerstone technologies needed to analyse auditory signals in real-life conditions; Earlier, for the advances needed in computational and data efficiency; Attentively, for accounting to individual differences and handling the longitudinal nature of medical data; and, finally, Responsibly, for ensuring compliance to the ethical standards accorded to the field of medicine.
DeepSpectrumLite: A Power-Efficient Transfer Learning Framework for Embedded Speech and Audio Processing from Decentralised Data
Apr 23, 2021



Deep neural speech and audio processing systems have a large number of trainable parameters, a relatively complex architecture, and require a vast amount of training data and computational power. These constraints make it more challenging to integrate such systems into embedded devices and utilise them for real-time, real-world applications. We tackle these limitations by introducing DeepSpectrumLite, an open-source, lightweight transfer learning framework for on-device speech and audio recognition using pre-trained image convolutional neural networks (CNNs). The framework creates and augments Mel-spectrogram plots on-the-fly from raw audio signals which are then used to finetune specific pre-trained CNNs for the target classification task. Subsequently, the whole pipeline can be run in real-time with a mean inference lag of 242.0 ms when a DenseNet121 model is used on a consumer-grade Motorola moto e7 plus smartphone. DeepSpectrumLite operates decentralised, eliminating the need for data upload for further processing. By obtaining state-of-the-art results on a set of paralinguistics tasks, we demonstrate the suitability of the proposed transfer learning approach for embedded audio signal processing, even when data is scarce. We provide an extensive command-line interface for users and developers which is comprehensively documented and publicly available at https://github.com/DeepSpectrum/DeepSpectrumLite.
On the Impact of Word Error Rate on Acoustic-Linguistic Speech Emotion Recognition: An Update for the Deep Learning Era
Apr 20, 2021
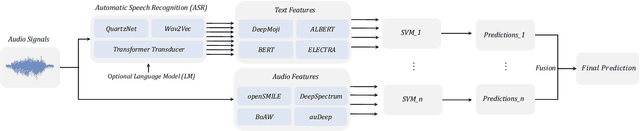
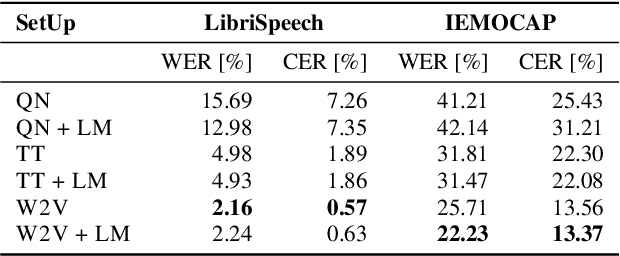

Text encodings from automatic speech recognition (ASR) transcripts and audio representations have shown promise in speech emotion recognition (SER) ever since. Yet, it is challenging to explain the effect of each information stream on the SER systems. Further, more clarification is required for analysing the impact of ASR's word error rate (WER) on linguistic emotion recognition per se and in the context of fusion with acoustic information exploitation in the age of deep ASR systems. In order to tackle the above issues, we create transcripts from the original speech by applying three modern ASR systems, including an end-to-end model trained with recurrent neural network-transducer loss, a model with connectionist temporal classification loss, and a wav2vec framework for self-supervised learning. Afterwards, we use pre-trained textual models to extract text representations from the ASR outputs and the gold standard. For extraction and learning of acoustic speech features, we utilise openSMILE, openXBoW, DeepSpectrum, and auDeep. Finally, we conduct decision-level fusion on both information streams -- acoustics and linguistics. Using the best development configuration, we achieve state-of-the-art unweighted average recall values of $73.6\,\%$ and $73.8\,\%$ on the speaker-independent development and test partitions of IEMOCAP, respectively.