 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Bridge between the Two Schools: Realizing a Practical Path to Include Literacy-based Skills within the STEM Curricula
Jan 24, 2026Developing students as well-rounded professionals is increasingly important for our modern society. Although there is a great consensus that technical and professional ("soft") skills should be developed and intertwined in the core of computer science subjects, there are still few examples of alike teaching methodologies at technical schools. This contribution investigates the integration of technical and professional skills while teaching specialized curricula in computer science. We propose a broadly applicable, step-by-step methodology that connects core technical concepts (e.g., information entropy, network security) with fine arts practices such as music, video production, gaming, and performing arts (e.g., Oxford-style debates). The methodology was applied in several computer science courses at technical universities, where quantitative and qualitative assessments, including student questionnaires and exam scores, showed improved learning outcomes and increased student engagement compared to traditional methods. The results indicate that this art-based integration can effectively bridge the historical divide between the two schools of thought, offering a practical direction for educators. Within this context, we also identify open issues that will guide future research on topics such as instructor engagement, female motivation in technical subjects, and scalability of these approaches.
Spatio-temporal Latent Representations for the Analysis of Acoustic Scenes in-the-wild
Dec 10, 2024In the field of acoustic scene analysis, this paper presents a novel approach to find spatio-temporal latent representations from in-the-wild audio data. By using WE-LIVE, an in-house collected dataset that includes audio recordings in diverse real-world environments together with sparse GPS coordinates, self-annotated emotional and situational labels, we tackle the challenging task of associating each audio segment with its corresponding location as a pretext task, with the final aim of acoustically detecting violent (anomalous) contexts, left as further work. By generating acoustic embeddings and using the self-supervised learning paradigm, we aim to use the model-generated latent space to acoustically characterize the spatio-temporal context. We use YAMNet, an acoustic events classifier trained in AudioSet to temporally locate and identify acoustic events in WE-LIVE. In order to transform the discrete acoustic events into embeddings, we compare the information-retrieval-based TF-IDF algorithm and Node2Vec as an analogy to Natural Language Processing techniques. A VAE is then trained to provide a further adapted latent space. The analysis was carried out by measuring the cosine distance and visualizing data distribution via t-Distributed Stochastic Neighbor Embedding, revealing distinct acoustic scenes. Specifically, we discern variations between indoor and subway environments. Notably, these distinctions emerge within the latent space of the VAE, a stark contrast to the random distribution of data points before encoding. In summary, our research contributes a pioneering approach for extracting spatio-temporal latent representations from in-the-wild audio data.
WEMAC: Women and Emotion Multi-modal Affective Computing dataset
Mar 01, 2022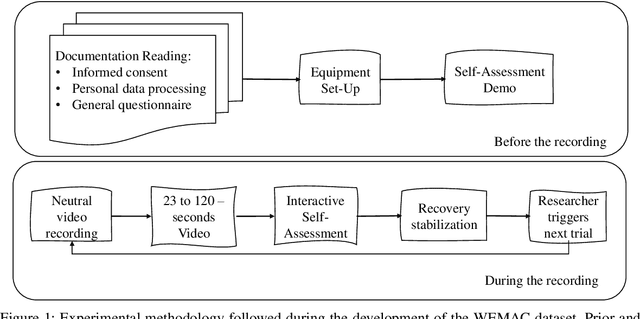

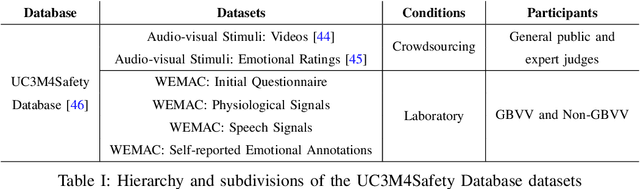

Among the seventeen Sustainable Development Goals (SDGs) proposed within the 2030 Agenda and adopted by all the United Nations member states, the Fifth SDG is a call for action to turn Gender Equality into a fundamental human right and an essential foundation for a better world. It includes the eradication of all types of violence against women. Within this context, the UC3M4Safety research team aims to develop Bindi. This is a cyber-physical system which includes embedded Artificial Intelligence algorithms, for user real-time monitoring towards the detection of affective states, with the ultimate goal of achieving the early detection of risk situations for women. On this basis, we make use of wearable affective computing including smart sensors, data encryption for secure and accurate collection of presumed crime evidence, as well as the remote connection to protecting agents. Towards the development of such system, the recordings of different laboratory and into-the-wild datasets are in process. These are contained within the UC3M4Safety Database. Thus, this paper presents and details the first release of WEMAC, a novel multi-modal dataset, which comprises a laboratory-based experiment for 47 women volunteers that were exposed to validated audio-visual stimuli to induce real emotions by using a virtual reality headset while physiological, speech signals and self-reports were acquired and collected. We believe this dataset will serve and assist research on multi-modal affective computing using physiological and speech information.
Assessing Information Transmission in Data Transformations with the Channel Multivariate Entropy Triangle
Oct 10, 2018
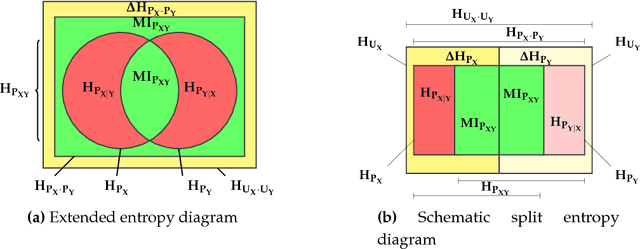
Data transformation, e.g. feature transformation and selection, is an integral part of any machine learning procedure. In this paper we introduce an information-theoretic model and tools to assess the quality of data transformations in machine learning tasks. In an unsupervised fashion, we analyze the transfer of information of the transformation of a discrete, multivariate source of information X into a discrete, multivariate sink of information Y related by a distribution PXY . The first contribution is a decomposition of the maximal potential entropy of (X, Y) that we call a balance equation, into its a) non-transferable, b) transferable but not transferred and c) transferred parts. Such balance equations can be represented in (de Finetti) entropy diagrams, our second set of contributions. The most important of these, the aggregate Channel Multivariate Entropy Triangle is a visual exploratory tool to assess the effectiveness of multivariate data transformations in transferring information from input to output variables. We also show how these decomposition and balance equation also apply to the entropies of X and Y respectively and generate entropy triangles for them. As an example, we present the application of these tools to the assessment of information transfer efficiency for PCA and ICA as unsupervised feature transformation and selection procedures in supervised classification tasks.
* 21 pages, 7 figures and 1 table