 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyTrain: Deep Neural Network Training at the Extreme Edge
Paper and Code

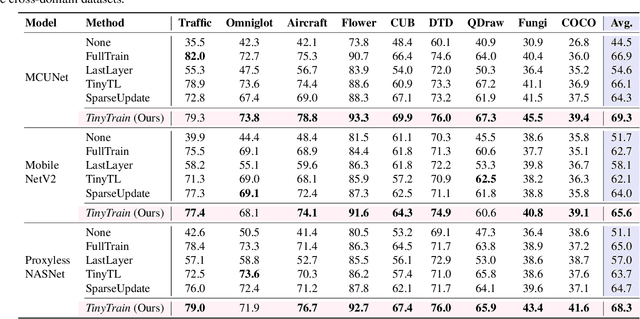
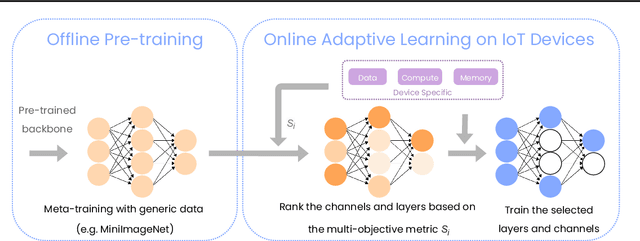
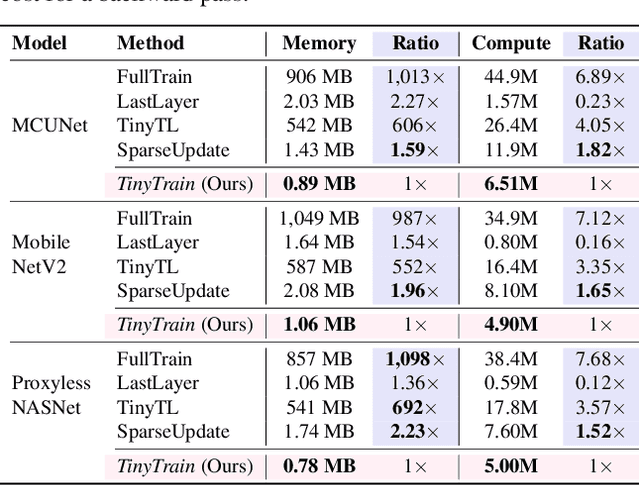
On-device training is essential for user personalisation and privacy. With the pervasiveness of IoT devices and microcontroller units (MCU), this task becomes more challenging due to the constrained memory and compute resources, and the limited availability of labelled user data. Nonetheless, prior works neglect the data scarcity issue, require excessively long training time (e.g. a few hours), or induce substantial accuracy loss ($\geq$10\%). We propose TinyTrain, an on-device training approach that drastically reduces training time by selectively updating parts of the model and explicitly coping with data scarcity. TinyTrain introduces a task-adaptive sparse-update method that dynamically selects the layer/channel based on a multi-objective criterion that jointly captures user data, the memory, and the compute capabilities of the target device, leading to high accuracy on unseen tasks with reduced computation and memory footprint. TinyTrain outperforms vanilla fine-tuning of the entire network by 3.6-5.0\% in accuracy, while reducing the backward-pass memory and computation cost by up to 2,286$\times$ and 7.68$\times$, respectively. Targeting broadly used real-world edge devices, TinyTrain achieves 9.5$\times$ faster and 3.5$\times$ more energy-efficient training over status-quo approaches, and 2.8$\times$ smaller memory footprint than SOTA approaches, while remaining within the 1 MB memory envelope of MCU-grade platforms.