 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreathRNNet: Breathing Based Authentication on Resource-Constrained IoT Devices using RNNs
Paper and Code
Sep 22, 2017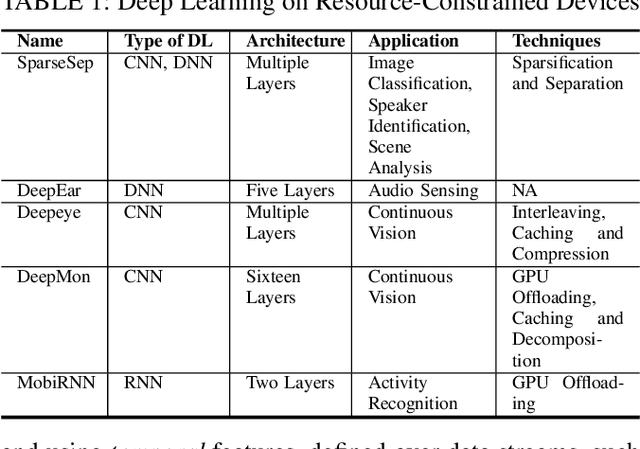
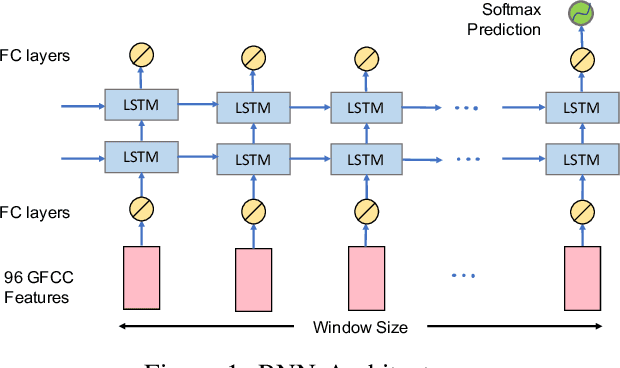
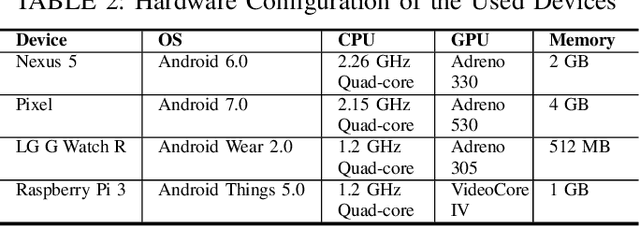
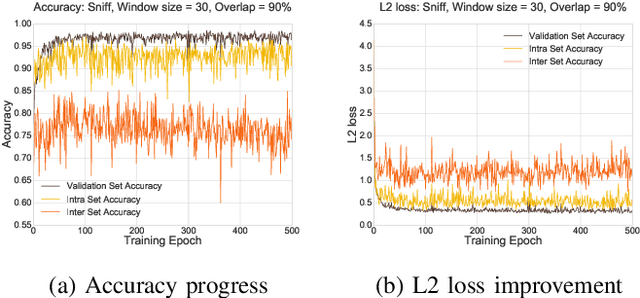
Recurrent neural networks (RNNs) have shown promising results in audio and speech processing applications due to their strong capabilities in modelling sequential data. In many applications, RNNs tend to outperform conventional models based on GMM/UBMs and i-vectors. Increasing popularity of IoT devices makes a strong case for implementing RNN based inferences for applications such as acoustics based authentication, voice commands, and edge analytics for smart homes. Nonetheless, the feasibility and performance of RNN based inferences on resources-constrained IoT devices remain largely unexplored. In this paper, we investigate the feasibility of using RNNs for an end-to-end authentication system based on breathing acoustics. We evaluate the performance of RNN models on three types of devices; smartphone, smartwatch, and Raspberry Pi and show that unlike CNN models, RNN models can be easily ported onto resource-constrained devices without a significant loss in accuracy.