 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHone as You Read: A Practical Type of Interactive Summarization
May 06, 2021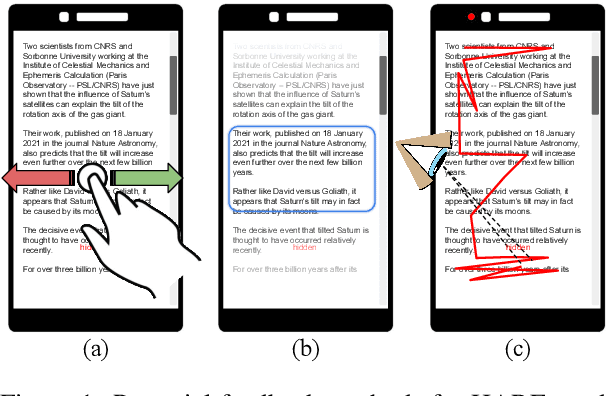
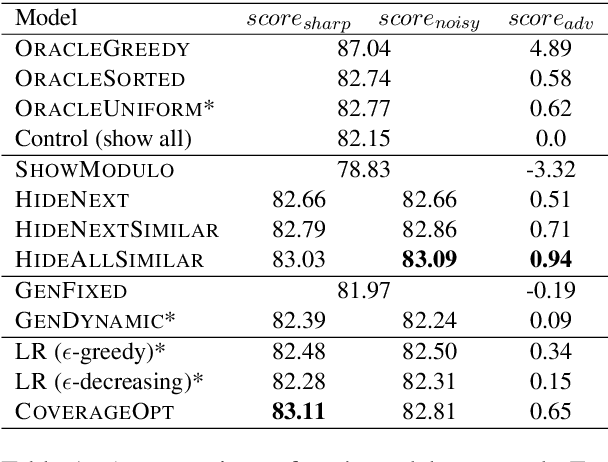
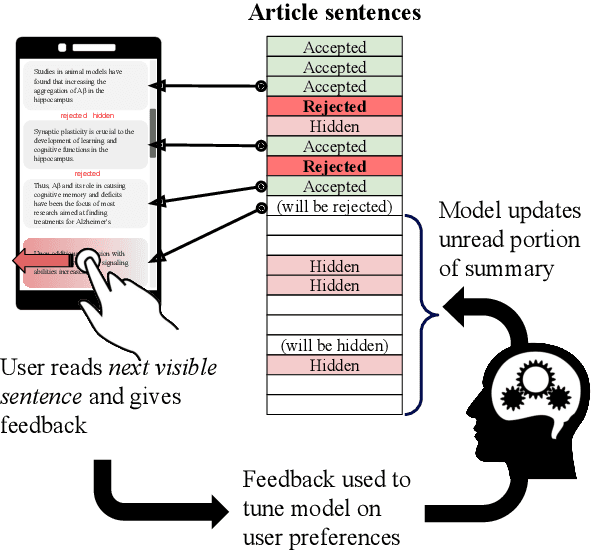

We present HARE, a new task where reader feedback is used to optimize document summaries for personal interest during the normal flow of reading. This task is related to interactive summarization, where personalized summaries are produced following a long feedback stage where users may read the same sentences many times. However, this process severely interrupts the flow of reading, making it impractical for leisurely reading. We propose to gather minimally-invasive feedback during the reading process to adapt to user interests and augment the document in real-time. Building off of recent advances in unsupervised summarization evaluation, we propose a suitable metric for this task and use it to evaluate a variety of approaches. Our approaches range from simple heuristics to preference-learning and their analysis provides insight into this important task. Human evaluation additionally supports the practicality of HARE. The code to reproduce this work is available at https://github.com/tannerbohn/HoneAsYouRead.
A Deep Learning Framework for Lifelong Machine Learning
May 01, 2021
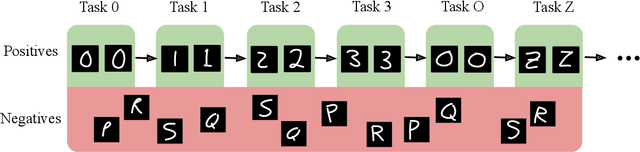


Humans can learn a variety of concepts and skills incrementally over the course of their lives while exhibiting many desirable properties, such as continual learning without forgetting, forward transfer and backward transfer of knowledge, and learning a new concept or task with only a few examples. Several lines of machine learning research, such as lifelong machine learning, few-shot learning, and transfer learning attempt to capture these properties. However, most previous approaches can only demonstrate subsets of these properties, often by different complex mechanisms. In this work, we propose a simple yet powerful unified deep learning framework that supports almost all of these properties and approaches through one central mechanism. Experiments on toy examples support our claims. We also draw connections between many peculiarities of human learning (such as memory loss and "rain man") and our framework. As academics, we often lack resources required to build and train, deep neural networks with billions of parameters on hundreds of TPUs. Thus, while our framework is still conceptual, and our experiment results are surely not SOTA, we hope that this unified lifelong learning framework inspires new work towards large-scale experiments and understanding human learning in general. This paper is summarized in two short YouTube videos: https://youtu.be/gCuUyGETbTU (part 1) and https://youtu.be/XsaGI01b-1o (part 2).
Catching Attention with Automatic Pull Quote Selection
May 27, 2020
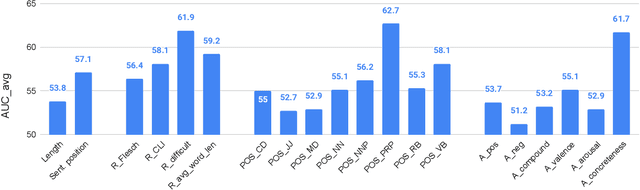
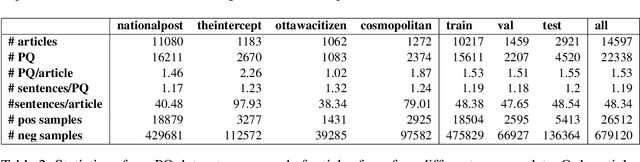

Pull quotes are an effective component of a captivating news article. These spans of text are selected from an article and provided with more salient presentation, with the aim of attracting readers with intriguing phrases and making the article more visually interesting. In this paper, we introduce the novel task of automatic pull quote selection, construct a dataset, and benchmark the performance of a number of approaches ranging from hand-crafted features to state-of-the-art sentence embeddings to cross-task models. We show that pre-trained Sentence-BERT embeddings outperform all other approaches, however the benefit over n-gram models is marginal. By closely examining the results of simple models, we also uncover many unexpected properties of pull quotes that should serve as inspiration for future approaches. We believe the benefits of exploring this problem further are clear: pull quotes have been found to increase enjoyment and readability, shape reader perceptions, and facilitate learning.
A Unified Framework for Lifelong Learning in Deep Neural Networks
Nov 28, 2019

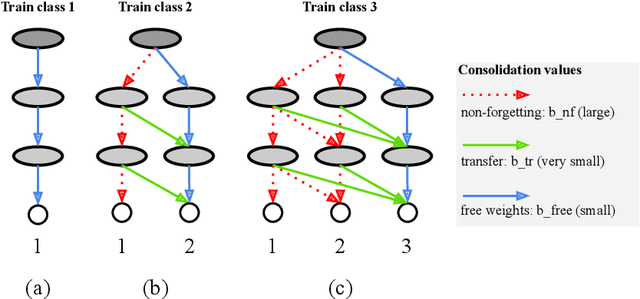
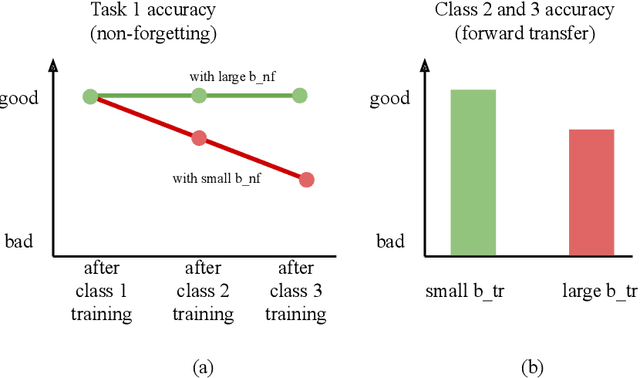
Humans can learn a variety of concepts and skills incrementally over the course of their lives while exhibiting an array of desirable properties, such as non-forgetting, concept rehearsal, forward transfer and backward transfer of knowledge, few-shot learning, and selective forgetting. Previous approaches to lifelong machine learning can only demonstrate subsets of these properties, often by combining multiple complex mechanisms. In this Perspective, we propose a powerful unified framework that can demonstrate all of the properties by utilizing a small number of weight consolidation parameters in deep neural networks. In addition, we are able to draw many parallels between the behaviours and mechanisms of our proposed framework and those surrounding human learning, such as memory loss or sleep deprivation. This Perspective serves as a conduit for two-way inspiration to further understand lifelong learning in machines and humans.
Few-Shot Abstract Visual Reasoning With Spectral Features
Oct 04, 2019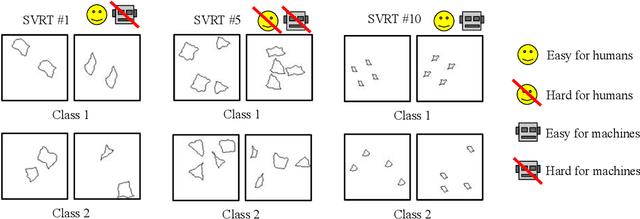
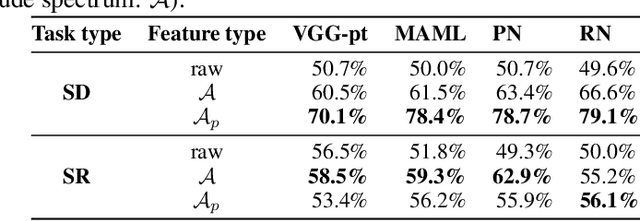
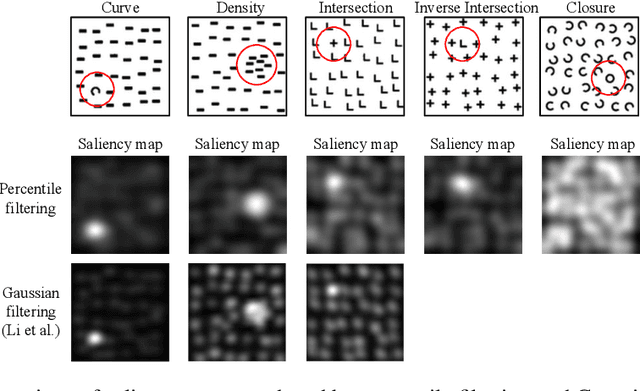

We present an image preprocessing technique capable of improving the performance of few-shot classifiers on abstract visual reasoning tasks. Many visual reasoning tasks with abstract features are easy for humans to learn with few examples but very difficult for computer vision approaches with the same number of samples, despite the ability for deep learning models to learn abstract features. Same-different (SD) problems represent a type of visual reasoning task requiring knowledge of pattern repetition within individual images, and modern computer vision approaches have largely faltered on these classification problems, even when provided with vast amounts of training data. We propose a simple method for solving these problems based on the insight that removing peaks from the amplitude spectrum of an image is capable of emphasizing the unique parts of the image. When combined with several classifiers, our method performs well on the SD SVRT tasks with few-shot learning, improving upon the best comparable results on all tasks, with average absolute accuracy increases nearly 40% for some classifiers. In particular, we find that combining Relational Networks with this image preprocessing approach improves their performance from chance-level to over 90% accuracy on several SD tasks.