 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatching Attention with Automatic Pull Quote Selection
Paper and Code

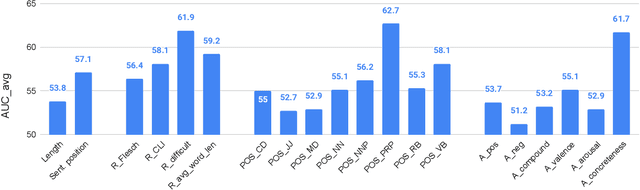
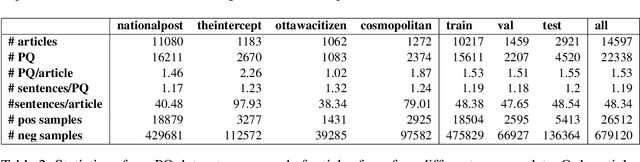

Pull quotes are an effective component of a captivating news article. These spans of text are selected from an article and provided with more salient presentation, with the aim of attracting readers with intriguing phrases and making the article more visually interesting. In this paper, we introduce the novel task of automatic pull quote selection, construct a dataset, and benchmark the performance of a number of approaches ranging from hand-crafted features to state-of-the-art sentence embeddings to cross-task models. We show that pre-trained Sentence-BERT embeddings outperform all other approaches, however the benefit over n-gram models is marginal. By closely examining the results of simple models, we also uncover many unexpected properties of pull quotes that should serve as inspiration for future approaches. We believe the benefits of exploring this problem further are clear: pull quotes have been found to increase enjoyment and readability, shape reader perceptions, and facilitate learning.