 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinary Anomaly Detection in Streaming IoT Traffic under Concept Drift
Oct 31, 2025



With the growing volume of Internet of Things (IoT) network traffic, machine learning (ML)-based anomaly detection is more relevant than ever. Traditional batch learning models face challenges such as high maintenance and poor adaptability to rapid anomaly changes, known as concept drift. In contrast, streaming learning integrates online and incremental learning, enabling seamless updates and concept drift detection to improve robustness. This study investigates anomaly detection in streaming IoT traffic as binary classification, comparing batch and streaming learning approaches while assessing the limitations of current IoT traffic datasets. We simulated heterogeneous network data streams by carefully mixing existing datasets and streaming the samples one by one. Our results highlight the failure of batch models to handle concept drift, but also reveal persisting limitations of current datasets to expose model limitations due to low traffic heterogeneity. We also investigated the competitiveness of tree-based ML algorithms, well-known in batch anomaly detection, and compared it to non-tree-based ones, confirming the advantages of the former. Adaptive Random Forest achieved F1-score of 0.990 $\pm$ 0.006 at one-third the computational cost of its batch counterpart. Hoeffding Adaptive Tree reached F1-score of 0.910 $\pm$ 0.007, reducing computational cost by four times, making it a viable choice for online applications despite a slight trade-off in stability.
Characterizing and Detecting Money Laundering Activities on the Bitcoin Network
Dec 27, 2019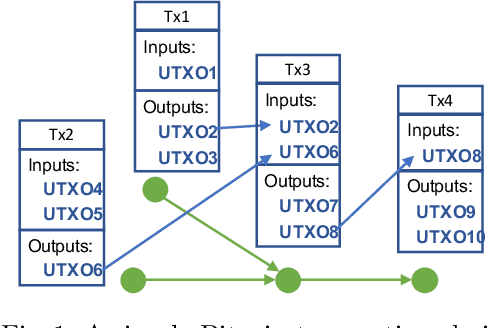

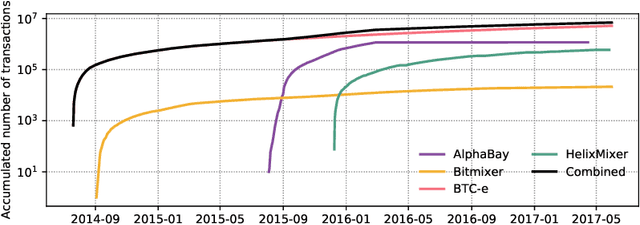
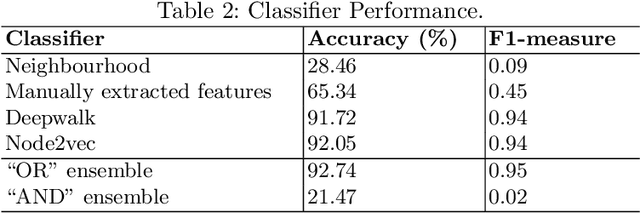
Bitcoin is by far the most popular crypto-currency solution enabling peer-to-peer payments. Despite some studies highlighting the network does not provide full anonymity, it is still being heavily used for a wide variety of dubious financial activities such as money laundering, ponzi schemes, and ransom-ware payments. In this paper, we explore the landscape of potential money laundering activities occurring across the Bitcoin network. Using data collected over three years, we create transaction graphs and provide an in-depth analysis on various graph characteristics to differentiate money laundering transactions from regular transactions. We found that the main difference between laundering and regular transactions lies in their output values and neighbourhood information. Then, we propose and evaluate a set of classifiers based on four types of graph features: immediate neighbours, curated features, deepwalk embeddings, and node2vec embeddings to classify money laundering and regular transactions. Results show that the node2vec-based classifier outperforms other classifiers in binary classification reaching an average accuracy of 92.29% and an F1-measure of 0.93 and high robustness over a 2.5-year time span. Finally, we demonstrate how effective our classifiers are in discovering unknown laundering services. The classifier performance dropped compared to binary classification, however, the prediction can be improved with simple ensemble techniques for some services.