 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training for Information Retrieval: Are Hyperlinks Fully Explored?
Sep 14, 2022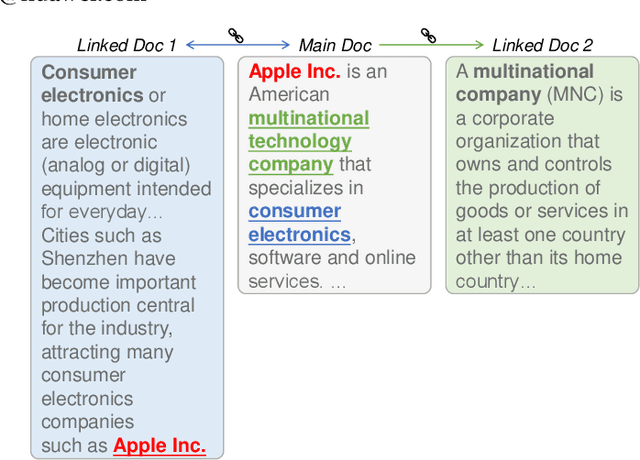
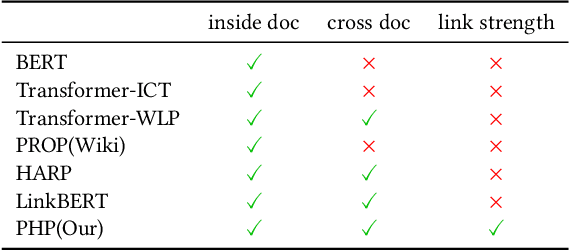
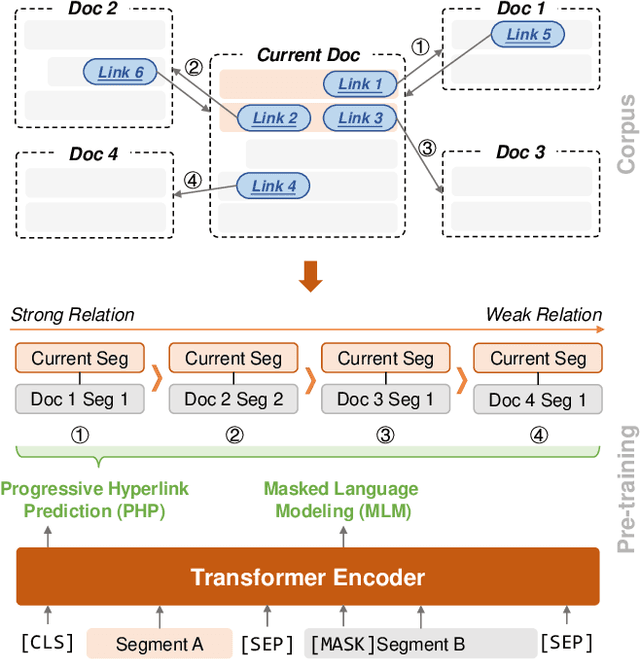
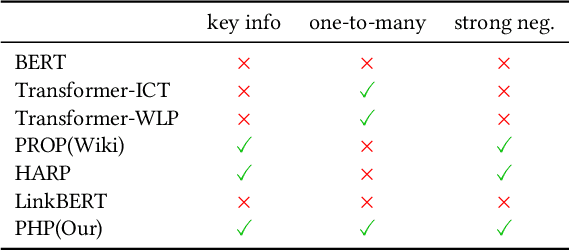
Recent years have witnessed great progress on applying pre-trained language models, e.g., BERT, to information retrieval (IR) tasks. Hyperlinks, which are commonly used in Web pages, have been leveraged for designing pre-training objectives. For example, anchor texts of the hyperlinks have been used for simulating queries, thus constructing tremendous query-document pairs for pre-training. However, as a bridge across two web pages, the potential of hyperlinks has not been fully explored. In this work, we focus on modeling the relationship between two documents that are connected by hyperlinks and designing a new pre-training objective for ad-hoc retrieval. Specifically, we categorize the relationships between documents into four groups: no link, unidirectional link, symmetric link, and the most relevant symmetric link. By comparing two documents sampled from adjacent groups, the model can gradually improve its capability of capturing matching signals. We propose a progressive hyperlink predication ({PHP}) framework to explore the utilization of hyperlinks in pre-training. Experimental results on two large-scale ad-hoc retrieval datasets and six question-answering datasets demonstrate its superiority over existing pre-training methods.
Towards More Effective and Economic Sparsely-Activated Model
Oct 14, 2021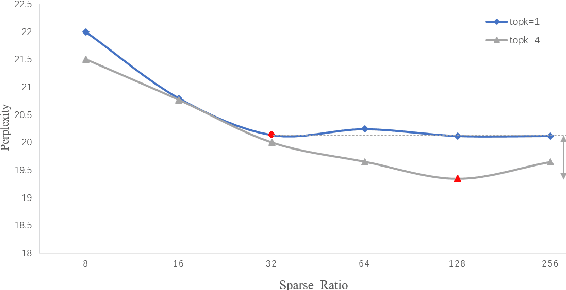
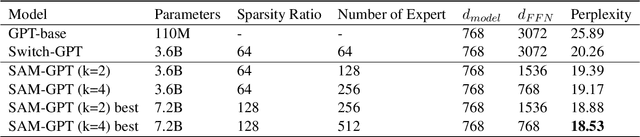
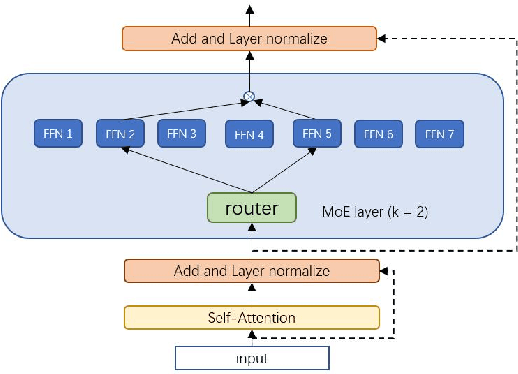
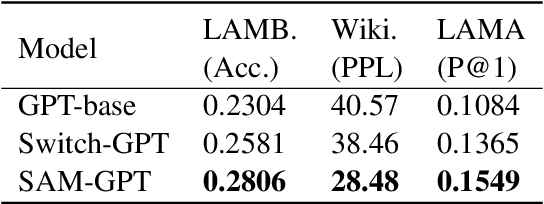
The sparsely-activated models have achieved great success in natural language processing through large-scale parameters and relatively low computational cost, and gradually become a feasible technique for training and implementing extremely large models. Due to the limit of communication cost, activating multiple experts is hardly affordable during training and inference. Therefore, previous work usually activate just one expert at a time to alleviate additional communication cost. Such routing mechanism limits the upper bound of model performance. In this paper, we first investigate a phenomenon that increasing the number of activated experts can boost the model performance with higher sparse ratio. To increase the number of activated experts without an increase in computational cost, we propose SAM (Switch and Mixture) routing, an efficient hierarchical routing mechanism that activates multiple experts in a same device (GPU). Our methods shed light on the training of extremely large sparse models and experiments prove that our models can achieve significant performance gain with great efficiency improvement.
YES SIR!Optimizing Semantic Space of Negatives with Self-Involvement Ranker
Sep 14, 2021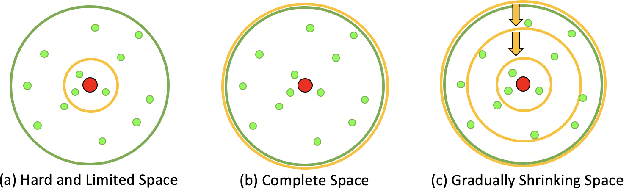
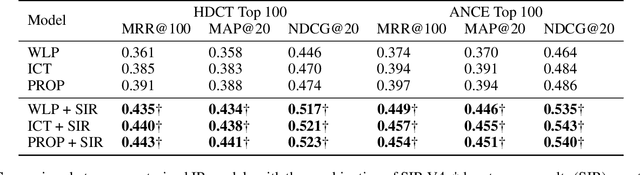
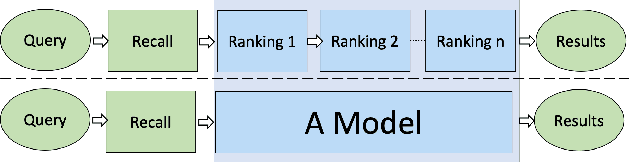
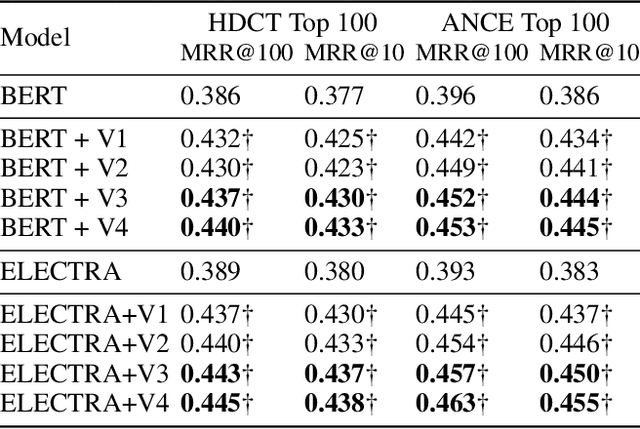
Pre-trained model such as BERT has been proved to be an effective tool for dealing with Information Retrieval (IR) problems. Due to its inspiring performance, it has been widely used to tackle with real-world IR problems such as document ranking. Recently, researchers have found that selecting "hard" rather than "random" negative samples would be beneficial for fine-tuning pre-trained models on ranking tasks. However, it remains elusive how to leverage hard negative samples in a principled way. To address the aforementioned issues, we propose a fine-tuning strategy for document ranking, namely Self-Involvement Ranker (SIR), to dynamically select hard negative samples to construct high-quality semantic space for training a high-quality ranking model. Specifically, SIR consists of sequential compressors implemented with pre-trained models. Front compressor selects hard negative samples for rear compressor. Moreover, SIR leverages supervisory signal to adaptively adjust semantic space of negative samples. Finally, supervisory signal in rear compressor is computed based on condition probability and thus can control sample dynamic and further enhance the model performance. SIR is a lightweight and general framework for pre-trained models, which simplifies the ranking process in industry practice. We test our proposed solution on MS MARCO with document ranking setting, and the results show that SIR can significantly improve the ranking performance of various pre-trained models. Moreover, our method became the new SOTA model anonymously on MS MARCO Document ranking leaderboard in May 2021.