 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly-Informed Confidence Calibration for Vision-Based Safety Prediction
May 20, 2026Reliable confidence estimates are important for safely deploying vision-based controllers in autonomous racing, where safety predictions must be derived from camera images, yet modern predictors become dangerously overconfident under test-time distribution shifts. We identify a critical perception-dynamics gap in existing anomaly signals: widely used scores, such as autoencoder reconstruction error, capture visual corruptions but miss dynamics anomalies (e.g., actuation bias, latency), where images remain plausible while the trajectory degrades. To address this, we propose an Anomaly-Informed Online Calibration approach that, without retraining any model component, fuses two complementary anomaly scores extracted from a world model: a perceptual score from reconstruction error and a dynamics score from epistemic uncertainty and control-stream statistics. Based on these fused scores, a lightweight temperature-scaling calibrator leverages test-time augmentation to selectively reduce overconfidence under shift while preserving nominal-condition performance. Experiments on a physical DonkeyCar under four real-world anomaly protocols unseen during training (darkness, blur, actuation bias, processing latency) reduce average expected calibration error from 0.184 to 0.116, a 37% improvement over the best baseline, without modifying the base safety predictor.
Riemannian Neural Geodesic Interpolant
Apr 22, 2025

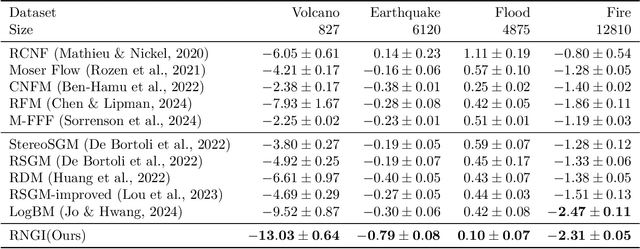

Stochastic interpolants are efficient generative models that bridge two arbitrary probability density functions in finite time, enabling flexible generation from the source to the target distribution or vice versa. These models are primarily developed in Euclidean space, and are therefore limited in their application to many distribution learning problems defined on Riemannian manifolds in real-world scenarios. In this work, we introduce the Riemannian Neural Geodesic Interpolant (RNGI) model, which interpolates between two probability densities on a Riemannian manifold along the stochastic geodesics, and then samples from one endpoint as the final state using the continuous flow originating from the other endpoint. We prove that the temporal marginal density of RNGI solves a transport equation on the Riemannian manifold. After training the model's the neural velocity and score fields, we propose the Embedding Stochastic Differential Equation (E-SDE) algorithm for stochastic sampling of RNGI. E-SDE significantly improves the sampling quality by reducing the accumulated error caused by the excessive intrinsic discretization of Riemannian Brownian motion in the classical Geodesic Random Walk (GRW) algorithm. We also provide theoretical bounds on the generative bias measured in terms of KL-divergence. Finally, we demonstrate the effectiveness of the proposed RNGI and E-SDE through experiments conducted on both collected and synthetic distributions on S2 and SO(3).
Benchmarking Hallucination in Large Language Models based on Unanswerable Math Word Problem
Mar 06, 2024



Large language models (LLMs) are highly effective in various natural language processing (NLP) tasks. However, they are susceptible to producing unreliable conjectures in ambiguous contexts called hallucination. This paper presents a new method for evaluating LLM hallucination in Question Answering (QA) based on the unanswerable math word problem (MWP). To support this approach, we innovatively develop a dataset called Unanswerable Math Word Problem (UMWP) which comprises 5200 questions across five categories. We developed an evaluation methodology combining text similarity and mathematical expression detection to determine whether LLM considers the question unanswerable. The results of extensive experiments conducted on 31 LLMs, including GPT-3, InstructGPT, LLaMA, and Claude, demonstrate that in-context learning and reinforcement learning with human feedback (RLHF) training significantly enhance the model's ability to avoid hallucination. We show that utilizing MWP is a reliable and effective approach to assess hallucination. Our code and data are available at https://github.com/Yuki-Asuuna/UMWP.
Do Large Language Models Know What They Don't Know?
May 30, 2023Large language models (LLMs) have a wealth of knowledge that allows them to excel in various Natural Language Processing (NLP) tasks. Current research focuses on enhancing their performance within their existing knowledge. Despite their vast knowledge, LLMs are still limited by the amount of information they can accommodate and comprehend. Therefore, the ability to understand their own limitations on the unknows, referred to as self-knowledge, is of paramount importance. This study aims to evaluate LLMs' self-knowledge by assessing their ability to identify unanswerable or unknowable questions. We introduce an automated methodology to detect uncertainty in the responses of these models, providing a novel measure of their self-knowledge. We further introduce a unique dataset, SelfAware, consisting of unanswerable questions from five diverse categories and their answerable counterparts. Our extensive analysis, involving 20 LLMs including GPT-3, InstructGPT, and LLaMA, discovering an intrinsic capacity for self-knowledge within these models. Moreover, we demonstrate that in-context learning and instruction tuning can further enhance this self-knowledge. Despite this promising insight, our findings also highlight a considerable gap between the capabilities of these models and human proficiency in recognizing the limits of their knowledge.
Pre-training for Information Retrieval: Are Hyperlinks Fully Explored?
Sep 14, 2022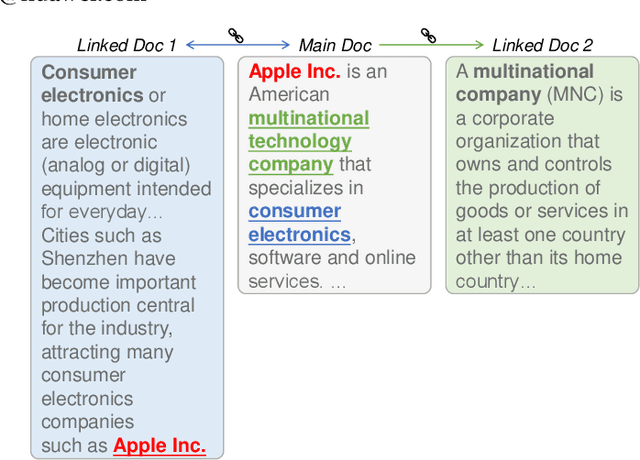
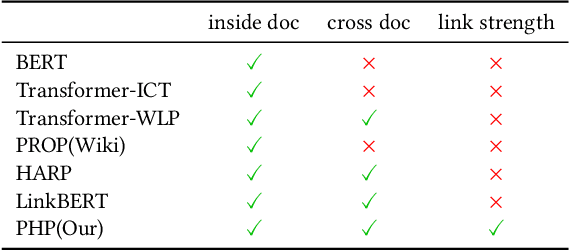
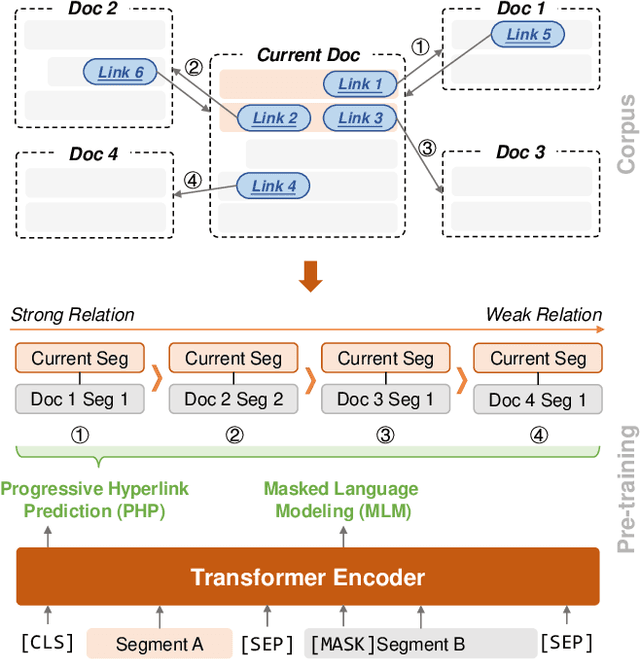
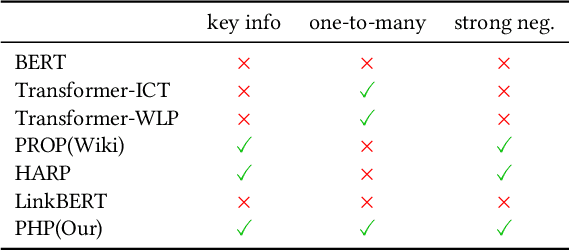
Recent years have witnessed great progress on applying pre-trained language models, e.g., BERT, to information retrieval (IR) tasks. Hyperlinks, which are commonly used in Web pages, have been leveraged for designing pre-training objectives. For example, anchor texts of the hyperlinks have been used for simulating queries, thus constructing tremendous query-document pairs for pre-training. However, as a bridge across two web pages, the potential of hyperlinks has not been fully explored. In this work, we focus on modeling the relationship between two documents that are connected by hyperlinks and designing a new pre-training objective for ad-hoc retrieval. Specifically, we categorize the relationships between documents into four groups: no link, unidirectional link, symmetric link, and the most relevant symmetric link. By comparing two documents sampled from adjacent groups, the model can gradually improve its capability of capturing matching signals. We propose a progressive hyperlink predication ({PHP}) framework to explore the utilization of hyperlinks in pre-training. Experimental results on two large-scale ad-hoc retrieval datasets and six question-answering datasets demonstrate its superiority over existing pre-training methods.
Coarse-to-Fine: Hierarchical Multi-task Learning for Natural Language Understanding
Aug 19, 2022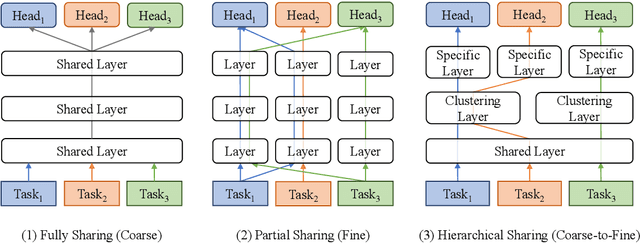
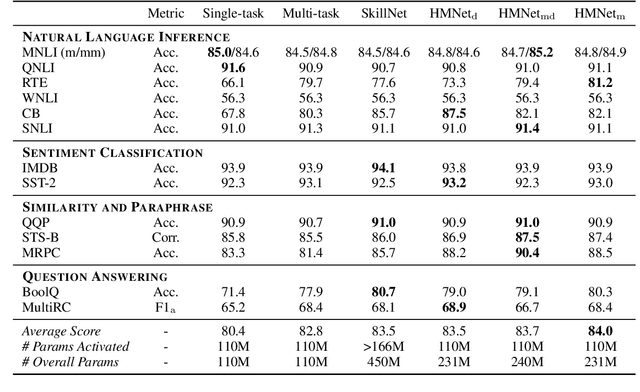
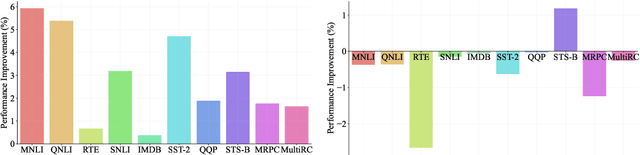
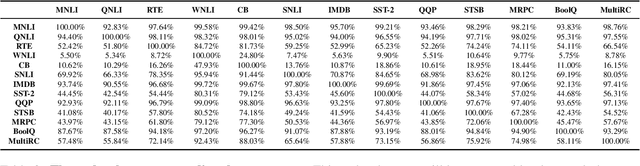
Generalized text representations are the foundation of many natural language understanding tasks. To fully utilize the different corpus, it is inevitable that models need to understand the relevance among them. However, many methods ignore the relevance and adopt a single-channel model (a coarse paradigm) directly for all tasks, which lacks enough rationality and interpretation. In addition, some existing works learn downstream tasks by stitches skill block(a fine paradigm), which might cause irrationalresults due to its redundancy and noise. Inthis work, we first analyze the task correlation through three different perspectives, i.e., data property, manual design, and model-based relevance, based on which the similar tasks are grouped together. Then, we propose a hierarchical framework with a coarse-to-fine paradigm, with the bottom level shared to all the tasks, the mid-level divided to different groups, and the top-level assigned to each of the tasks. This allows our model to learn basic language properties from all tasks, boost performance on relevant tasks, and reduce the negative impact from irrelevant tasks. Our experiments on 13 benchmark datasets across five natural language understanding tasks demonstrate the superiority of our method.
Towards More Effective and Economic Sparsely-Activated Model
Oct 14, 2021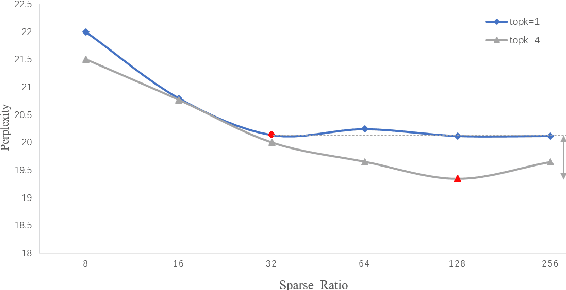
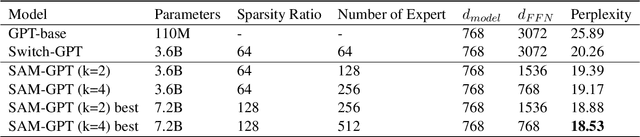
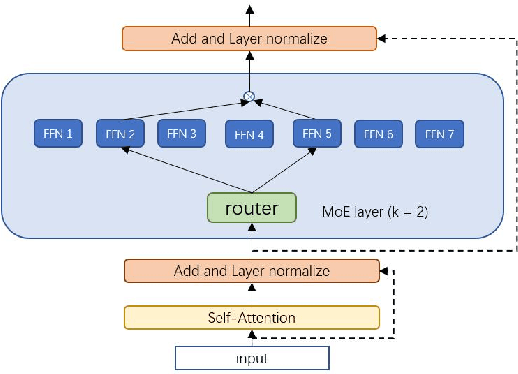
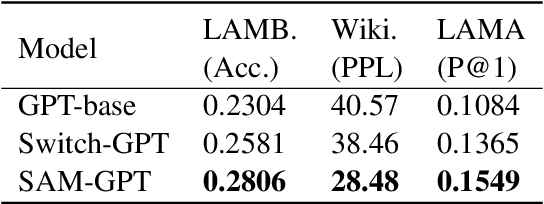
The sparsely-activated models have achieved great success in natural language processing through large-scale parameters and relatively low computational cost, and gradually become a feasible technique for training and implementing extremely large models. Due to the limit of communication cost, activating multiple experts is hardly affordable during training and inference. Therefore, previous work usually activate just one expert at a time to alleviate additional communication cost. Such routing mechanism limits the upper bound of model performance. In this paper, we first investigate a phenomenon that increasing the number of activated experts can boost the model performance with higher sparse ratio. To increase the number of activated experts without an increase in computational cost, we propose SAM (Switch and Mixture) routing, an efficient hierarchical routing mechanism that activates multiple experts in a same device (GPU). Our methods shed light on the training of extremely large sparse models and experiments prove that our models can achieve significant performance gain with great efficiency improvement.
Replicating Active Appearance Model by Generator Network
May 14, 2018
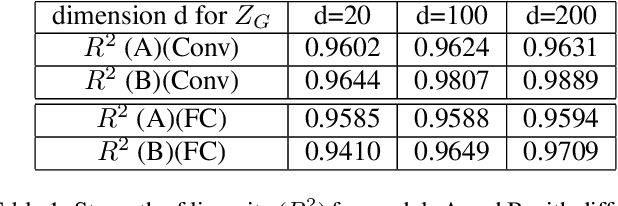


A recent Cell paper [Chang and Tsao, 2017] reports an interesting discovery. For the face stimuli generated by a pre-trained active appearance model (AAM), the responses of neurons in the areas of the primate brain that are responsible for face recognition exhibit strong linear relationship with the shape variables and appearance variables of the AAM that generates the face stimuli. In this paper, we show that this behavior can be replicated by a deep generative model called the generator network, which assumes that the observed signals are generated by latent random variables via a top-down convolutional neural network. Specifically, we learn the generator network from the face images generated by a pre-trained AAM model using variational auto-encoder, and we show that the inferred latent variables of the learned generator network have strong linear relationship with the shape and appearance variables of the AAM model that generates the face images. Unlike the AAM model that has an explicit shape model where the shape variables generate the control points or landmarks, the generator network has no such shape model and shape variables. Yet the generator network can learn the shape knowledge in the sense that some of the latent variables of the learned generator network capture the shape variations in the face images generated by AAM.