 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training for Information Retrieval: Are Hyperlinks Fully Explored?
Paper and Code
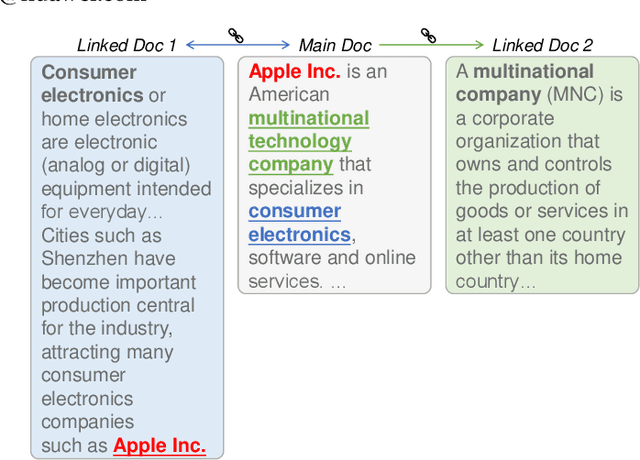
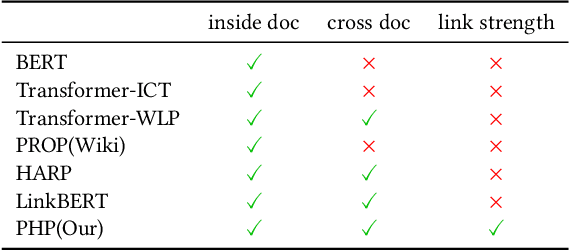
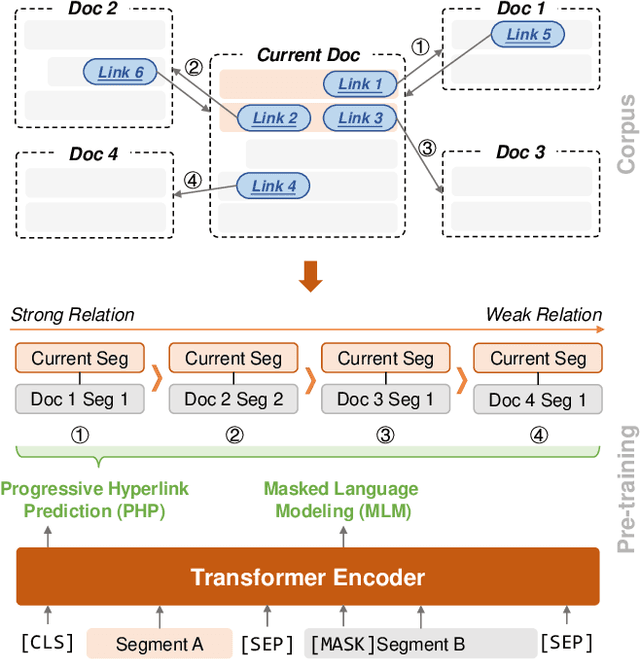
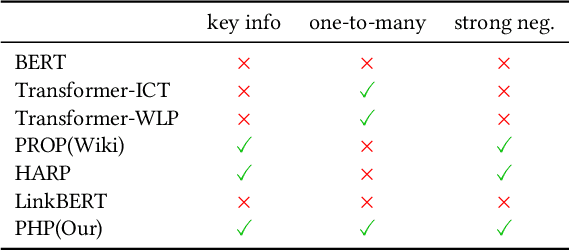
Recent years have witnessed great progress on applying pre-trained language models, e.g., BERT, to information retrieval (IR) tasks. Hyperlinks, which are commonly used in Web pages, have been leveraged for designing pre-training objectives. For example, anchor texts of the hyperlinks have been used for simulating queries, thus constructing tremendous query-document pairs for pre-training. However, as a bridge across two web pages, the potential of hyperlinks has not been fully explored. In this work, we focus on modeling the relationship between two documents that are connected by hyperlinks and designing a new pre-training objective for ad-hoc retrieval. Specifically, we categorize the relationships between documents into four groups: no link, unidirectional link, symmetric link, and the most relevant symmetric link. By comparing two documents sampled from adjacent groups, the model can gradually improve its capability of capturing matching signals. We propose a progressive hyperlink predication ({PHP}) framework to explore the utilization of hyperlinks in pre-training. Experimental results on two large-scale ad-hoc retrieval datasets and six question-answering datasets demonstrate its superiority over existing pre-training methods.