 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYES SIR!Optimizing Semantic Space of Negatives with Self-Involvement Ranker
Paper and Code
Sep 14, 2021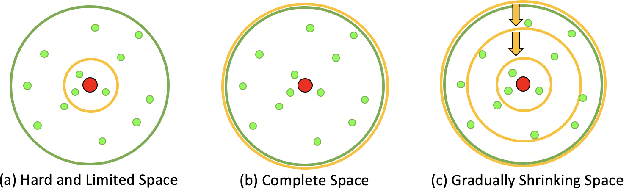
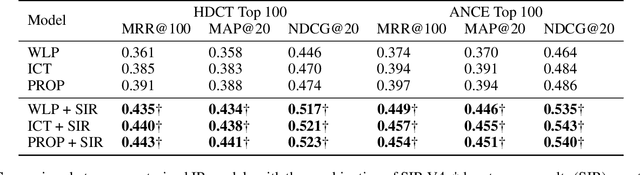
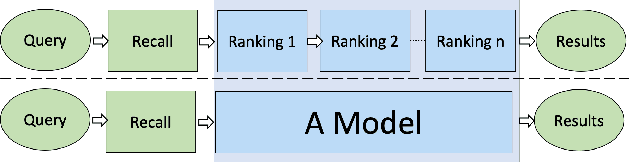
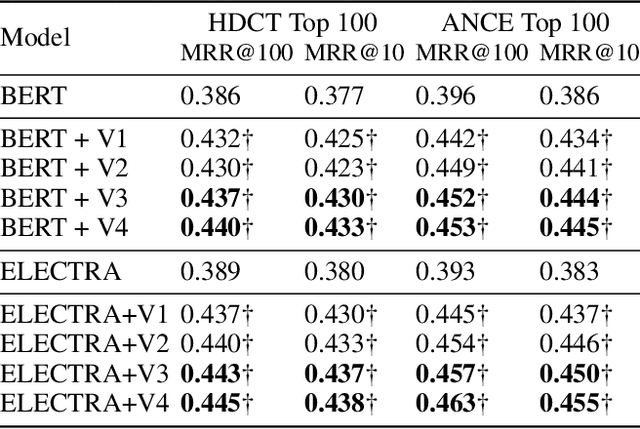
Pre-trained model such as BERT has been proved to be an effective tool for dealing with Information Retrieval (IR) problems. Due to its inspiring performance, it has been widely used to tackle with real-world IR problems such as document ranking. Recently, researchers have found that selecting "hard" rather than "random" negative samples would be beneficial for fine-tuning pre-trained models on ranking tasks. However, it remains elusive how to leverage hard negative samples in a principled way. To address the aforementioned issues, we propose a fine-tuning strategy for document ranking, namely Self-Involvement Ranker (SIR), to dynamically select hard negative samples to construct high-quality semantic space for training a high-quality ranking model. Specifically, SIR consists of sequential compressors implemented with pre-trained models. Front compressor selects hard negative samples for rear compressor. Moreover, SIR leverages supervisory signal to adaptively adjust semantic space of negative samples. Finally, supervisory signal in rear compressor is computed based on condition probability and thus can control sample dynamic and further enhance the model performance. SIR is a lightweight and general framework for pre-trained models, which simplifies the ranking process in industry practice. We test our proposed solution on MS MARCO with document ranking setting, and the results show that SIR can significantly improve the ranking performance of various pre-trained models. Moreover, our method became the new SOTA model anonymously on MS MARCO Document ranking leaderboard in May 2021.