 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKMIR: A Benchmark for Evaluating Knowledge Memorization, Identification and Reasoning Abilities of Language Models
Feb 28, 2022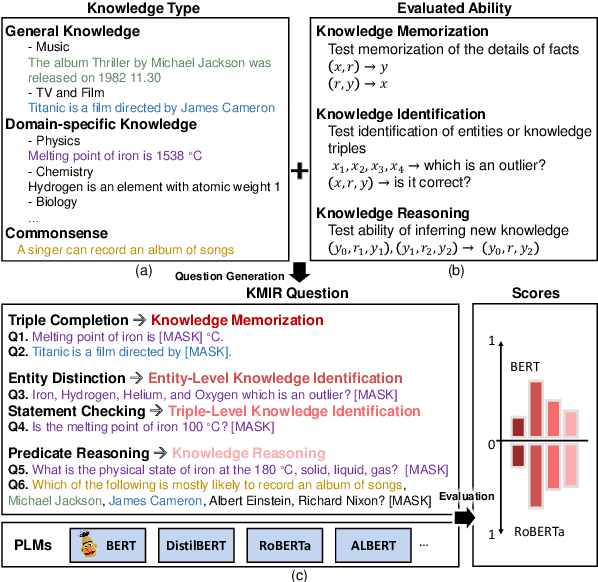



Previous works show the great potential of pre-trained language models (PLMs) for storing a large amount of factual knowledge. However, to figure out whether PLMs can be reliable knowledge sources and used as alternative knowledge bases (KBs), we need to further explore some critical features of PLMs. Firstly, knowledge memorization and identification abilities: traditional KBs can store various types of entities and relationships; do PLMs have a high knowledge capacity to store different types of knowledge? Secondly, reasoning ability: a qualified knowledge source should not only provide a collection of facts, but support a symbolic reasoner. Can PLMs derive new knowledge based on the correlations between facts? To evaluate these features of PLMs, we propose a benchmark, named Knowledge Memorization, Identification, and Reasoning test (KMIR). KMIR covers 3 types of knowledge, including general knowledge, domain-specific knowledge, and commonsense, and provides 184,348 well-designed questions. Preliminary experiments with various representative pre-training language models on KMIR reveal many interesting phenomenons: 1) The memorization ability of PLMs depends more on the number of parameters than training schemes. 2) Current PLMs are struggling to robustly remember the facts. 3) Model compression technology retains the amount of knowledge well, but hurts the identification and reasoning abilities. We hope KMIR can facilitate the design of PLMs as better knowledge sources.