 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Adaptive Translation for Knowledge Graph Embedding
Paper and Code
Dec 04, 2015
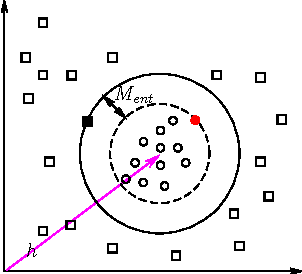

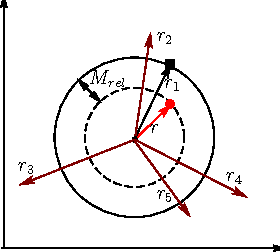
Knowledge graph embedding aims to represent entities and relations in a large-scale knowledge graph as elements in a continuous vector space. Existing methods, e.g., TransE and TransH, learn embedding representation by defining a global margin-based loss function over the data. However, the optimal loss function is determined during experiments whose parameters are examined among a closed set of candidates. Moreover, embeddings over two knowledge graphs with different entities and relations share the same set of candidate loss functions, ignoring the locality of both graphs. This leads to the limited performance of embedding related applications. In this paper, we propose a locally adaptive translation method for knowledge graph embedding, called TransA, to find the optimal loss function by adaptively determining its margin over different knowledge graphs. Experiments on two benchmark data sets demonstrate the superiority of the proposed method, as compared to the-state-of-the-art ones.