 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskOCR: Text Recognition with Masked Encoder-Decoder Pretraining
Jun 01, 2022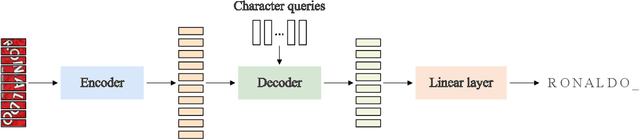

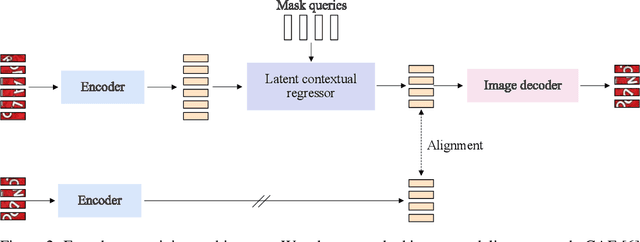

In this paper, we present a model pretraining technique, named MaskOCR, for text recognition. Our text recognition architecture is an encoder-decoder transformer: the encoder extracts the patch-level representations, and the decoder recognizes the text from the representations. Our approach pretrains both the encoder and the decoder in a sequential manner. (i) We pretrain the encoder in a self-supervised manner over a large set of unlabeled real text images. We adopt the masked image modeling approach, which shows the effectiveness for general images, expecting that the representations take on semantics. (ii) We pretrain the decoder over a large set of synthesized text images in a supervised manner and enhance the language modeling capability of the decoder by randomly masking some text image patches occupied by characters input to the encoder and accordingly the representations input to the decoder. Experiments show that the proposed MaskOCR approach achieves superior results on the benchmark datasets, including Chinese and English text images.