 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruct-IPT: All-in-One Image Processing Transformer via Weight Modulation
Jun 30, 2024



Due to the unaffordable size and intensive computation costs of low-level vision models, All-in-One models that are designed to address a handful of low-level vision tasks simultaneously have been popular. However, existing All-in-One models are limited in terms of the range of tasks and performance. To overcome these limitations, we propose Instruct-IPT -- an All-in-One Image Processing Transformer that could effectively address manifold image restoration tasks with large inter-task gaps, such as denoising, deblurring, deraining, dehazing, and desnowing. Rather than popular feature adaptation methods, we propose weight modulation that adapts weights to specific tasks. Firstly, we figure out task-sensitive weights via a toy experiment and introduce task-specific biases on top of them. Secondly, we conduct rank analysis for a good compression strategy and perform low-rank decomposition on the biases. Thirdly, we propose synchronous training that updates the task-general backbone model and the task-specific biases simultaneously. In this way, the model is instructed to learn general and task-specific knowledge. Via our simple yet effective method that instructs the IPT to be task experts, Instruct-IPT could better cooperate between tasks with distinct characteristics at humble costs. Further, we propose to maneuver Instruct-IPT with text instructions for better user interfaces. We have conducted experiments on Instruct-IPT to demonstrate the effectiveness of our method on manifold tasks, and we have effectively extended our method to diffusion denoisers as well. The code is available at https://github.com/huawei-noah/Pretrained-IPT.
IFT: Image Fusion Transformer for Ghost-free High Dynamic Range Imaging
Sep 26, 2023
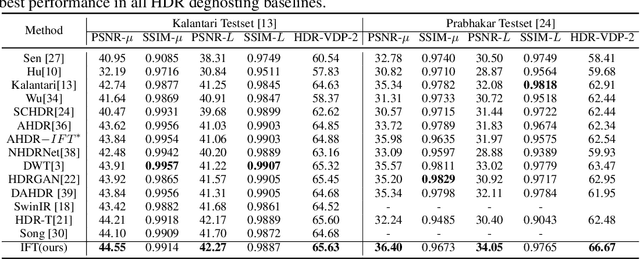

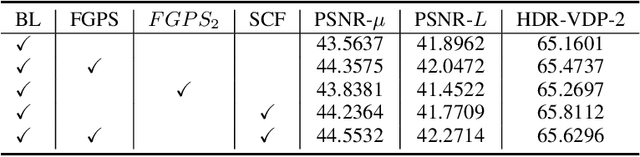
Multi-frame high dynamic range (HDR) imaging aims to reconstruct ghost-free images with photo-realistic details from content-complementary but spatially misaligned low dynamic range (LDR) images. Existing HDR algorithms are prone to producing ghosting artifacts as their methods fail to capture long-range dependencies between LDR frames with large motion in dynamic scenes. To address this issue, we propose a novel image fusion transformer, referred to as IFT, which presents a fast global patch searching (FGPS) module followed by a self-cross fusion module (SCF) for ghost-free HDR imaging. The FGPS searches the patches from supporting frames that have the closest dependency to each patch of the reference frame for long-range dependency modeling, while the SCF conducts intra-frame and inter-frame feature fusion on the patches obtained by the FGPS with linear complexity to input resolution. By matching similar patches between frames, objects with large motion ranges in dynamic scenes can be aligned, which can effectively alleviate the generation of artifacts. In addition, the proposed FGPS and SCF can be integrated into various deep HDR methods as efficient plug-in modules. Extensive experiments on multiple benchmarks show that our method achieves state-of-the-art performance both quantitatively and qualitatively.