 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality-based Transfer of Driving Scenarios to Unseen Intersections
Apr 02, 2024



Scenario-based testing of automated driving functions has become a promising method to reduce time and cost compared to real-world testing. In scenario-based testing automated functions are evaluated in a set of pre-defined scenarios. These scenarios provide information about vehicle behaviors, environmental conditions, or road characteristics using parameters. To create realistic scenarios, parameters and parameter dependencies have to be fitted utilizing real-world data. However, due to the large variety of intersections and movement constellations found in reality, data may not be available for certain scenarios. This paper proposes a methodology to systematically analyze relations between parameters of scenarios. Bayesian networks are utilized to analyze causal dependencies in order to decrease the amount of required data and to transfer causal patterns creating unseen scenarios. Thereby, infrastructural influences on movement patterns are investigated to generate realistic scenarios on unobserved intersections. For evaluation, scenarios and underlying parameters are extracted from the inD dataset. Movement patterns are estimated, transferred and checked against recorded data from those initially unseen intersections.
An Automated Analysis Framework for Trajectory Datasets
Feb 12, 2022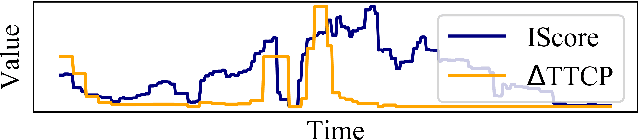
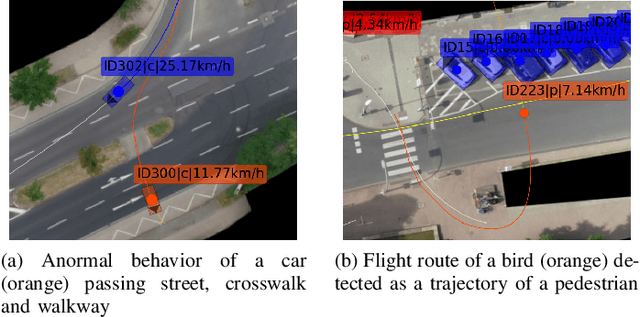


Trajectory datasets of road users have become more important in the last years for safety validation of highly automated vehicles. Several naturalistic trajectory datasets with each more than 10.000 tracks were released and others will follow. Considering this amount of data, it is necessary to be able to compare these datasets in-depth with ease to get an overview. By now, the datasets' own provided information is mainly limited to meta-data and qualitative descriptions which are mostly not consistent with other datasets. This is insufficient for users to differentiate the emerging datasets for application-specific selection. Therefore, an automated analysis framework is proposed in this work. Starting with analyzing individual tracks, fourteen elementary characteristics, so-called detection types, are derived and used as the base of this framework. To describe each traffic scenario precisely, the detections are subdivided into common metrics, clustering methods and anomaly detection. Those are combined using a modular approach. The detections are composed into new scores to describe three defined attributes of each track data quantitatively: interaction, anomaly and relevance. These three scores are calculated hierarchically for different abstract layers to provide an overview not just between datasets but also for tracks, spatial regions and individual situations. So, an objective comparison between datasets can be realized. Furthermore, it can help to get a deeper understanding of the recorded infrastructure and its effect on road user behavior. To test the validity of the framework, a study is conducted to compare the scores with human perception. Additionally, several datasets are compared.