 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgekarl. -- A Research Vehicle for Automated and Connected Driving
Feb 09, 2026As highly automated driving is transitioning from single-vehicle closed-access testing to commercial deployments of public ride-hailing in selected areas (e.g., Waymo), automated driving and connected cooperative intelligent transport systems (C-ITS) remain active fields of research. Even though simulation is omnipresent in the development and validation life cycle of automated and connected driving technology, the complex nature of public road traffic and software that masters it still requires real-world integration and testing with actual vehicles. Dedicated vehicles for research and development allow testing and validation of software and hardware components under real-world conditions early on. They also enable collecting and publishing real-world datasets that let others conduct research without vehicle access, and support early demonstration of futuristic use cases. In this paper, we present karl., our new research vehicle for automated and connected driving. Apart from major corporations, few institutions worldwide have access to their own L4-capable research vehicles, restricting their ability to carry out independent research. This paper aims to help bridge that gap by sharing the reasoning, design choices, and technical details that went into making karl. a flexible and powerful platform for research, engineering, and validation in the context of automated and connected driving. More impressions of karl. are available at https://karl.ac.
OCCUQ: Exploring Efficient Uncertainty Quantification for 3D Occupancy Prediction
Mar 13, 2025Autonomous driving has the potential to significantly enhance productivity and provide numerous societal benefits. Ensuring robustness in these safety-critical systems is essential, particularly when vehicles must navigate adverse weather conditions and sensor corruptions that may not have been encountered during training. Current methods often overlook uncertainties arising from adversarial conditions or distributional shifts, limiting their real-world applicability. We propose an efficient adaptation of an uncertainty estimation technique for 3D occupancy prediction. Our method dynamically calibrates model confidence using epistemic uncertainty estimates. Our evaluation under various camera corruption scenarios, such as fog or missing cameras, demonstrates that our approach effectively quantifies epistemic uncertainty by assigning higher uncertainty values to unseen data. We introduce region-specific corruptions to simulate defects affecting only a single camera and validate our findings through both scene-level and region-level assessments. Our results show superior performance in Out-of-Distribution (OoD) detection and confidence calibration compared to common baselines such as Deep Ensembles and MC-Dropout. Our approach consistently demonstrates reliable uncertainty measures, indicating its potential for enhancing the robustness of autonomous driving systems in real-world scenarios. Code and dataset are available at https://github.com/ika-rwth-aachen/OCCUQ .
MultiCorrupt: A Multi-Modal Robustness Dataset and Benchmark of LiDAR-Camera Fusion for 3D Object Detection
Feb 18, 2024Multi-modal 3D object detection models for automated driving have demonstrated exceptional performance on computer vision benchmarks like nuScenes. However, their reliance on densely sampled LiDAR point clouds and meticulously calibrated sensor arrays poses challenges for real-world applications. Issues such as sensor misalignment, miscalibration, and disparate sampling frequencies lead to spatial and temporal misalignment in data from LiDAR and cameras. Additionally, the integrity of LiDAR and camera data is often compromised by adverse environmental conditions such as inclement weather, leading to occlusions and noise interference. To address this challenge, we introduce MultiCorrupt, a comprehensive benchmark designed to evaluate the robustness of multi-modal 3D object detectors against ten distinct types of corruptions. We evaluate five state-of-the-art multi-modal detectors on MultiCorrupt and analyze their performance in terms of their resistance ability. Our results show that existing methods exhibit varying degrees of robustness depending on the type of corruption and their fusion strategy. We provide insights into which multi-modal design choices make such models robust against certain perturbations. The dataset generation code and benchmark are open-sourced at https://github.com/ika-rwth-aachen/MultiCorrupt.
3D Point Cloud Compression with Recurrent Neural Network and Image Compression Methods
Feb 18, 2024Storing and transmitting LiDAR point cloud data is essential for many AV applications, such as training data collection, remote control, cloud services or SLAM. However, due to the sparsity and unordered structure of the data, it is difficult to compress point cloud data to a low volume. Transforming the raw point cloud data into a dense 2D matrix structure is a promising way for applying compression algorithms. We propose a new lossless and calibrated 3D-to-2D transformation which allows compression algorithms to efficiently exploit spatial correlations within the 2D representation. To compress the structured representation, we use common image compression methods and also a self-supervised deep compression approach using a recurrent neural network. We also rearrange the LiDAR's intensity measurements to a dense 2D representation and propose a new metric to evaluate the compression performance of the intensity. Compared to approaches that are based on generic octree point cloud compression or based on raw point cloud data compression, our approach achieves the best quantitative and visual performance. Source code and dataset are available at https://github.com/ika-rwth-aachen/Point-Cloud-Compression.
* Code: https://github.com/ika-rwth-aachen/Point-Cloud-Compression
Explainable Multi-Camera 3D Object Detection with Transformer-Based Saliency Maps
Dec 22, 2023Vision Transformers (ViTs) have achieved state-of-the-art results on various computer vision tasks, including 3D object detection. However, their end-to-end implementation also makes ViTs less explainable, which can be a challenge for deploying them in safety-critical applications, such as autonomous driving, where it is important for authorities, developers, and users to understand the model's reasoning behind its predictions. In this paper, we propose a novel method for generating saliency maps for a DetR-like ViT with multiple camera inputs used for 3D object detection. Our method is based on the raw attention and is more efficient than gradient-based methods. We evaluate the proposed method on the nuScenes dataset using extensive perturbation tests and show that it outperforms other explainability methods in terms of visual quality and quantitative metrics. We also demonstrate the importance of aggregating attention across different layers of the transformer. Our work contributes to the development of explainable AI for ViTs, which can help increase trust in AI applications by establishing more transparency regarding the inner workings of AI models.
Data-Driven Occupancy Grid Mapping using Synthetic and Real-World Data
Nov 15, 2022In perception tasks of automated vehicles (AVs) data-driven have often outperformed conventional approaches. This motivated us to develop a data-driven methodology to compute occupancy grid maps (OGMs) from lidar measurements. Our approach extends previous work such that the estimated environment representation now contains an additional layer for cells occupied by dynamic objects. Earlier solutions could only distinguish between free and occupied cells. The information whether an obstacle could move plays an important role for planning the behavior of an AV. We present two approaches to generating training data. One approach extends our previous work on using synthetic training data so that OGMs with the three aforementioned cell states are generated. The other approach uses manual annotations from the nuScenes dataset to create training data. We compare the performance of both models in a quantitative analysis on unseen data from the real-world dataset. Next, we analyze the ability of both approaches to cope with a domain shift, i.e. when presented with lidar measurements from a different sensor on a different vehicle. We propose using information gained from evaluation on real-world data to further close the reality gap and create better synthetic data that can be used to train occupancy grid mapping models for arbitrary sensor configurations. Code is available at https://github.com/ika-rwth-aachen/DEviLOG.
Enabling Connectivity for Automated Mobility: A Novel MQTT-based Interface Evaluated in a 5G Case Study on Edge-Cloud Lidar Object Detection
Sep 08, 2022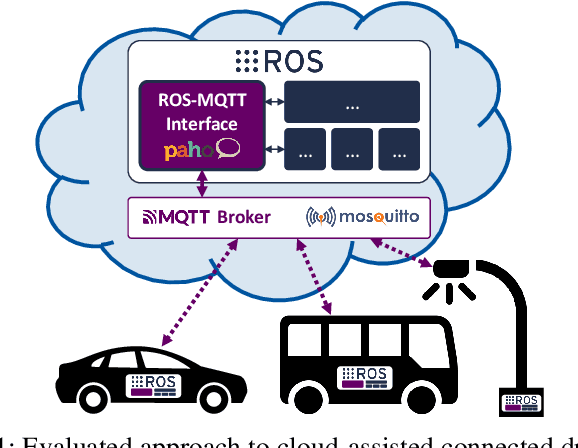


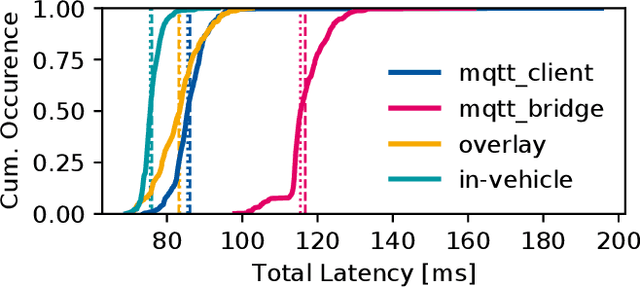
Enabling secure and reliable high-bandwidth lowlatency connectivity between automated vehicles and external servers, intelligent infrastructure, and other road users is a central step in making fully automated driving possible. The availability of data interfaces, which allow this kind of connectivity, has the potential to distinguish artificial agents' capabilities in connected, cooperative, and automated mobility systems from the capabilities of human operators, who do not possess such interfaces. Connected agents can for example share data to build collective environment models, plan collective behavior, and learn collectively from the shared data that is centrally combined. This paper presents multiple solutions that allow connected entities to exchange data. In particular, we propose a new universal communication interface which uses the Message Queuing Telemetry Transport (MQTT) protocol to connect agents running the Robot Operating System (ROS). Our work integrates methods to assess the connection quality in the form of various key performance indicators in real-time. We compare a variety of approaches that provide the connectivity necessary for the exemplary use case of edge-cloud lidar object detection in a 5G network. We show that the mean latency between the availability of vehicle-based sensor measurements and the reception of a corresponding object list from the edge-cloud is below 87 ms. All implemented solutions are made open-source and free to use. Source code is available at https://github.com/ika-rwth-aachen/ros-v2x-benchmarking-suite.