 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARLOS: An Open, Modular, and Scalable Simulation Framework for the Development and Testing of Software for C-ITS
Apr 04, 2024Future mobility systems and their components are increasingly defined by their software. The complexity of these cooperative intelligent transport systems (C-ITS) and the everchanging requirements posed at the software require continual software updates. The dynamic nature of the system and the practically innumerable scenarios in which different software components work together necessitate efficient and automated development and testing procedures that use simulations as one core methodology. The availability of such simulation architectures is a common interest among many stakeholders, especially in the field of automated driving. That is why we propose CARLOS - an open, modular, and scalable simulation framework for the development and testing of software in C-ITS that leverages the rich CARLA and ROS ecosystems. We provide core building blocks for this framework and explain how it can be used and extended by the community. Its architecture builds upon modern microservice and DevOps principles such as containerization and continuous integration. In our paper, we motivate the architecture by describing important design principles and showcasing three major use cases - software prototyping, data-driven development, and automated testing. We make CARLOS and example implementations of the three use cases publicly available at github.com/ika-rwth-aachen/carlos
3D Point Cloud Compression with Recurrent Neural Network and Image Compression Methods
Feb 18, 2024Storing and transmitting LiDAR point cloud data is essential for many AV applications, such as training data collection, remote control, cloud services or SLAM. However, due to the sparsity and unordered structure of the data, it is difficult to compress point cloud data to a low volume. Transforming the raw point cloud data into a dense 2D matrix structure is a promising way for applying compression algorithms. We propose a new lossless and calibrated 3D-to-2D transformation which allows compression algorithms to efficiently exploit spatial correlations within the 2D representation. To compress the structured representation, we use common image compression methods and also a self-supervised deep compression approach using a recurrent neural network. We also rearrange the LiDAR's intensity measurements to a dense 2D representation and propose a new metric to evaluate the compression performance of the intensity. Compared to approaches that are based on generic octree point cloud compression or based on raw point cloud data compression, our approach achieves the best quantitative and visual performance. Source code and dataset are available at https://github.com/ika-rwth-aachen/Point-Cloud-Compression.
* Code: https://github.com/ika-rwth-aachen/Point-Cloud-Compression
Enhancing Lidar-based Object Detection in Adverse Weather using Offset Sequences in Time
Jan 17, 2024Automated vehicles require an accurate perception of their surroundings for safe and efficient driving. Lidar-based object detection is a widely used method for environment perception, but its performance is significantly affected by adverse weather conditions such as rain and fog. In this work, we investigate various strategies for enhancing the robustness of lidar-based object detection by processing sequential data samples generated by lidar sensors. Our approaches leverage temporal information to improve a lidar object detection model, without the need for additional filtering or pre-processing steps. We compare $10$ different neural network architectures that process point cloud sequences including a novel augmentation strategy introducing a temporal offset between frames of a sequence during training and evaluate the effectiveness of all strategies on lidar point clouds under adverse weather conditions through experiments. Our research provides a comprehensive study of effective methods for mitigating the effects of adverse weather on the reliability of lidar-based object detection using sequential data that are evaluated using public datasets such as nuScenes, Dense, and the Canadian Adverse Driving Conditions Dataset. Our findings demonstrate that our novel method, involving temporal offset augmentation through randomized frame skipping in sequences, enhances object detection accuracy compared to both the baseline model (Pillar-based Object Detection) and no augmentation.
RobotKube: Orchestrating Large-Scale Cooperative Multi-Robot Systems with Kubernetes and ROS
Aug 14, 2023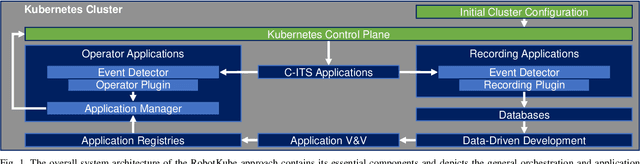
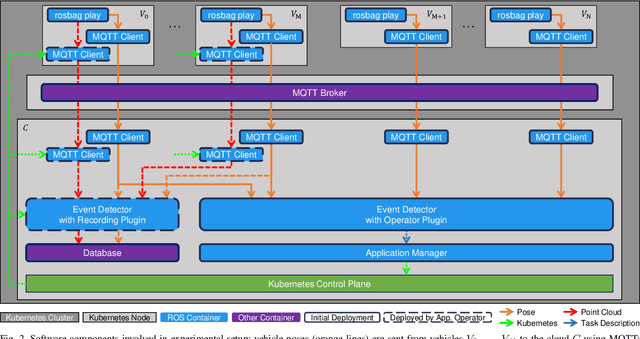
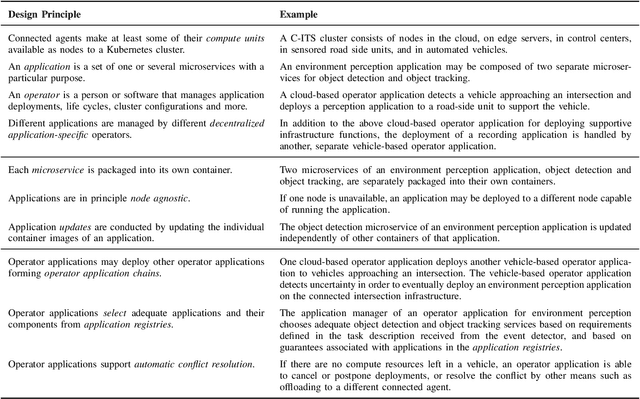

Modern cyber-physical systems (CPS) such as Cooperative Intelligent Transport Systems (C-ITS) are increasingly defined by the software which operates these systems. In practice, microservice architectures can be employed, which may consist of containerized microservices running in a cluster comprised of robots and supporting infrastructure. These microservices need to be orchestrated dynamically according to ever changing requirements posed at the system. Additionally, these systems are embedded in DevOps processes aiming at continually updating and upgrading both the capabilities of CPS components and of the system as a whole. In this paper, we present RobotKube, an approach to orchestrating containerized microservices for large-scale cooperative multi-robot CPS based on Kubernetes. We describe how to automate the orchestration of software across a CPS, and include the possibility to monitor and selectively store relevant accruing data. In this context, we present two main components of such a system: an event detector capable of, e.g., requesting the deployment of additional applications, and an application manager capable of automatically configuring the required changes in the Kubernetes cluster. By combining the widely adopted Kubernetes platform with the Robot Operating System (ROS), we enable the use of standard tools and practices for developing, deploying, scaling, and monitoring microservices in C-ITS. We demonstrate and evaluate RobotKube in an exemplary and reproducible use case that we make publicly available at https://github.com/ika-rwth-aachen/robotkube .
Combined Registration and Fusion of Evidential Occupancy Grid Maps for Live Digital Twins of Traffic
Apr 07, 2023


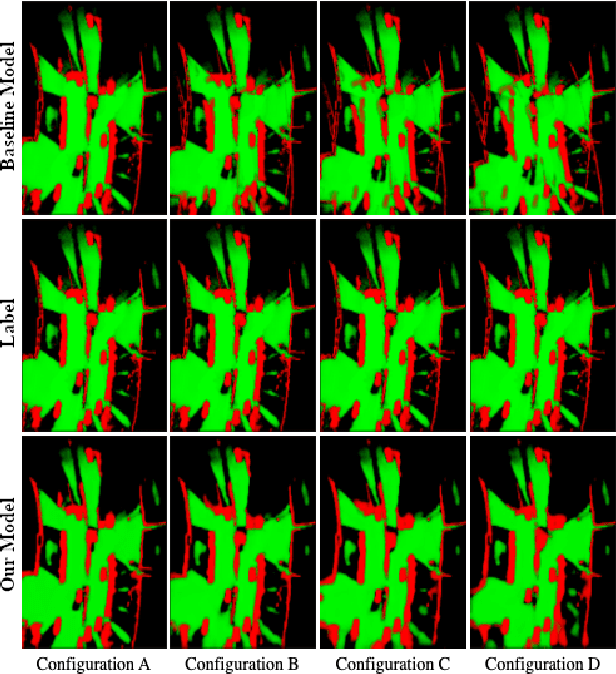
Cooperation of automated vehicles (AVs) can improve safety, efficiency and comfort in traffic. Digital twins of Cooperative Intelligent Transport Systems (C-ITS) play an important role in monitoring, managing and improving traffic. Computing a live digital twin of traffic requires as input live perception data of preferably multiple connected entities such as automated vehicles (AVs). One such type of perception data are evidential occupancy grid maps (OGMs). The computation of a digital twin involves their spatiotemporal alignment and fusion. In this work, we focus on the spatial alignment, also known as registration, and fusion of evidential occupancy grid maps of multiple automated vehicles. While there exists extensive research on the synchronization and fusion of object-based environment representations, the registration and fusion of OGMs originating from multiple connected vehicles has not been investigated much. We propose a methodology that involves training a deep neural network (DNN) to predict a fused evidential OGM from two OGMs computed by different AVs. The output includes an estimate of the first- and second-order uncertainty. We demonstrate that the DNN trained with synthetic data only outperforms a baseline approach based on coordinate transformation and combination rules also on real-world data. Experimental results on synthetic data show that our approach is able to compensate for spatial misalignments of up to 5 meters and 20 degrees.
Data-Driven Occupancy Grid Mapping using Synthetic and Real-World Data
Nov 15, 2022In perception tasks of automated vehicles (AVs) data-driven have often outperformed conventional approaches. This motivated us to develop a data-driven methodology to compute occupancy grid maps (OGMs) from lidar measurements. Our approach extends previous work such that the estimated environment representation now contains an additional layer for cells occupied by dynamic objects. Earlier solutions could only distinguish between free and occupied cells. The information whether an obstacle could move plays an important role for planning the behavior of an AV. We present two approaches to generating training data. One approach extends our previous work on using synthetic training data so that OGMs with the three aforementioned cell states are generated. The other approach uses manual annotations from the nuScenes dataset to create training data. We compare the performance of both models in a quantitative analysis on unseen data from the real-world dataset. Next, we analyze the ability of both approaches to cope with a domain shift, i.e. when presented with lidar measurements from a different sensor on a different vehicle. We propose using information gained from evaluation on real-world data to further close the reality gap and create better synthetic data that can be used to train occupancy grid mapping models for arbitrary sensor configurations. Code is available at https://github.com/ika-rwth-aachen/DEviLOG.
Enabling Connectivity for Automated Mobility: A Novel MQTT-based Interface Evaluated in a 5G Case Study on Edge-Cloud Lidar Object Detection
Sep 08, 2022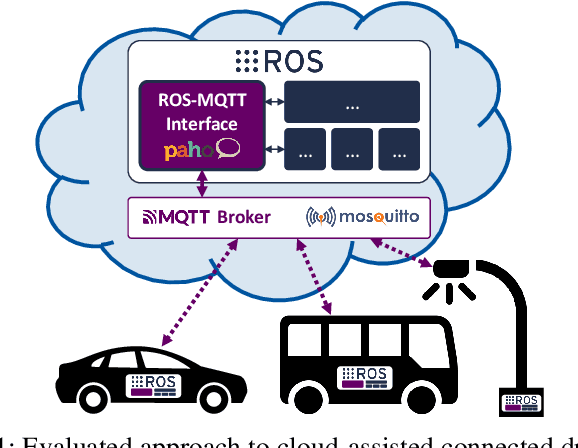


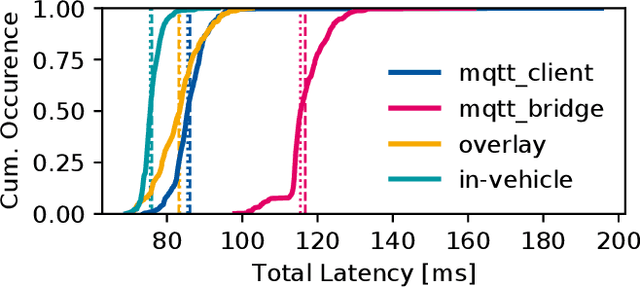
Enabling secure and reliable high-bandwidth lowlatency connectivity between automated vehicles and external servers, intelligent infrastructure, and other road users is a central step in making fully automated driving possible. The availability of data interfaces, which allow this kind of connectivity, has the potential to distinguish artificial agents' capabilities in connected, cooperative, and automated mobility systems from the capabilities of human operators, who do not possess such interfaces. Connected agents can for example share data to build collective environment models, plan collective behavior, and learn collectively from the shared data that is centrally combined. This paper presents multiple solutions that allow connected entities to exchange data. In particular, we propose a new universal communication interface which uses the Message Queuing Telemetry Transport (MQTT) protocol to connect agents running the Robot Operating System (ROS). Our work integrates methods to assess the connection quality in the form of various key performance indicators in real-time. We compare a variety of approaches that provide the connectivity necessary for the exemplary use case of edge-cloud lidar object detection in a 5G network. We show that the mean latency between the availability of vehicle-based sensor measurements and the reception of a corresponding object list from the edge-cloud is below 87 ms. All implemented solutions are made open-source and free to use. Source code is available at https://github.com/ika-rwth-aachen/ros-v2x-benchmarking-suite.
A Simulation-based End-to-End Learning Framework for Evidential Occupancy Grid Mapping
Feb 25, 2021


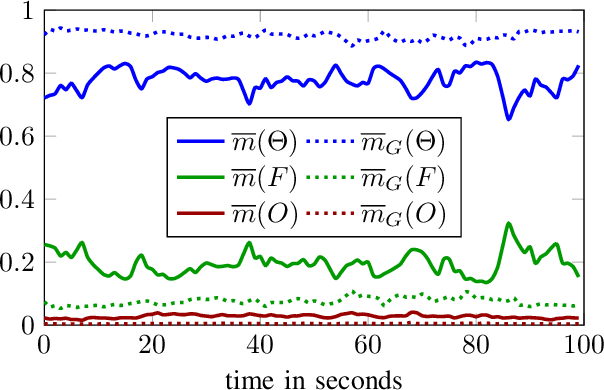
Evidential occupancy grid maps (OGMs) are a popular representation of the environment of automated vehicles. Inverse sensor models (ISMs) are used to compute OGMs from sensor data such as lidar point clouds. Geometric ISMs show a limited performance when estimating states in unobserved but inferable areas and have difficulties dealing with ambiguous input. Deep learning-based ISMs face the challenge of limited training data and they often cannot handle uncertainty quantification yet. We propose a deep learning-based framework for learning an OGM algorithm which is both capable of quantifying uncertainty and which does not rely on manually labeled data. Results on synthetic and on real-world data show superiority over other approaches.
A Sim2Real Deep Learning Approach for the Transformation of Images from Multiple Vehicle-Mounted Cameras to a Semantically Segmented Image in Bird's Eye View
May 08, 2020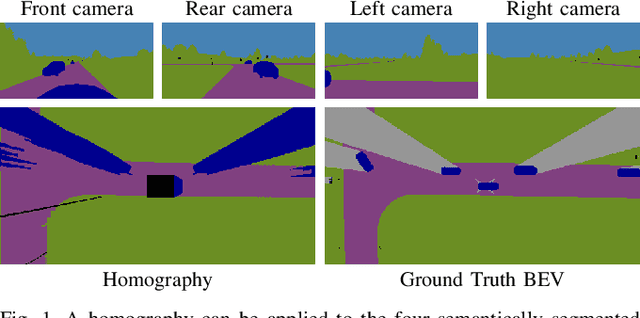

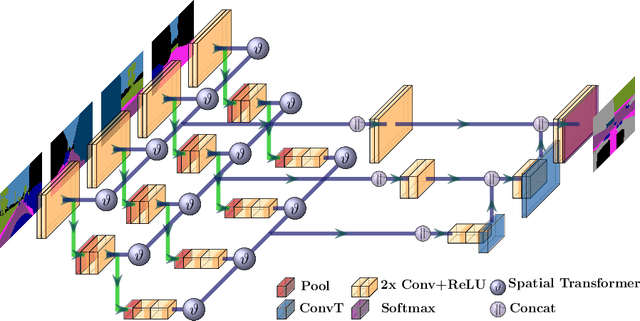
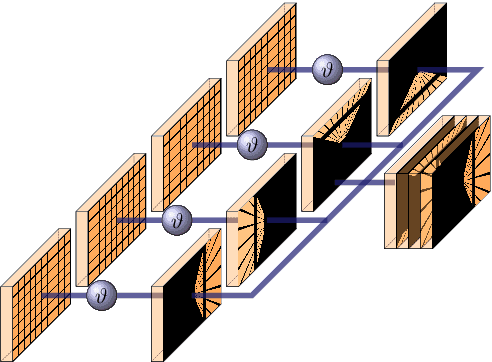
Accurate environment perception is essential for automated driving. When using monocular cameras, the distance estimation of elements in the environment poses a major challenge. Distances can be more easily estimated when the camera perspective is transformed to a bird's eye view (BEV). For flat surfaces, Inverse Perspective Mapping (IPM) can accurately transform images to a BEV. Three-dimensional objects such as vehicles and vulnerable road users are distorted by this transformation making it difficult to estimate their position relative to the sensor. This paper describes a methodology to obtain a corrected 360{\deg} BEV image given images from multiple vehicle-mounted cameras. The corrected BEV image is segmented into semantic classes and includes a prediction of occluded areas. The neural network approach does not rely on manually labeled data, but is trained on a synthetic dataset in such a way that it generalizes well to real-world data. By using semantically segmented images as input, we reduce the reality gap between simulated and real-world data and are able to show that our method can be successfully applied in the real world. Extensive experiments conducted on the synthetic data demonstrate the superiority of our approach compared to IPM. Source code and datasets are available at https://github.com/ika-rwth-aachen/Cam2BEV